







下载scrapy
pip install scrapy
创建项目

在桌面创建一个文件夹用来放项目
将创建好的项目放到文件夹内
直接将项目拖进pycharm
创建一个spider

在setting.py文件中修改robots协议

在新建好的spider中,初始化start_urls列表,告诉scrapy要下载的网页有哪些

name:spider的名称,将来启动的时候,需要指定启动哪个,就是这个name
allowed_domains:允许爬取的域名
start_urls:初始url列表,我们只需要把url放到这个[]中,将来启动scrapy的时候,scrapy就会拿到这个列表中的url自动帮我们下载好,下载好的结果就是一个response,这个response就是下面parse方法的参数,由parse方法接收
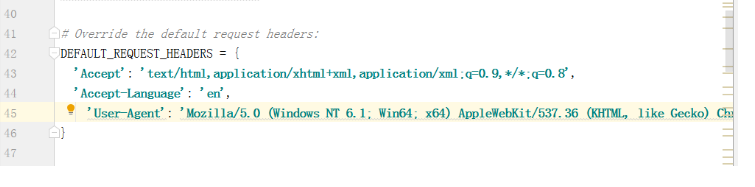
在settings.py配置文件中设置请求,添加请求头
在spider文件中的parse方法里测试是否能获取到页面数据
scrapy启动的方法:scrapy crawl name等于的字符串

在item.py中,定义我们要爬取的字段时哪些

在parse方法中实例化一个item,从页面中提取数据,将提取出来的数据设置到item对象中
补充:response.xpath返回的就是一个selector对象,selector对象可以继续调用xpath方法提取元素
可以通过以下两个方法从selector对象中获取字符串内容
- extract_first():相当于text[0]
- extract():取出返回的整个list中的每一个字符串内容
注:在启动方法后面加 --nolog 可以不打印日志运行scrapy















 1244
1244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









