








 超级会员免费看
超级会员免费看

前面一章讲了常规的数据包过滤方法,本篇介绍下未解码字段过滤方法。
我们知道tcpdump或者别的抓包手段抓到的数据包的原始数据都是16进制的原始码流,wireshark会根据码流里的每一层的协议标识先识别出协议,再根据协议标准去将16进制原始码流解码成我们可以看懂的ASCII码。
但是由于一些原因,例如原始包的协议内容被抓断了,以及网络设备之间约定的东西,wireshark没有从头抓起,没有获取到,所以无法识别一些提前约定的东西,尤其对于使用头压缩技术的协议,例如http2协议,这些原因造成wireshark不是总能将原始的码流解码成明文。还有些私有协议,wireshark当然没有标准字段解码依据,也是无法解码的。
上面讲的种种情况下,我们欲过滤自己想要的字段怎么办呢?
一,有参考包内容的
1、tcp传输层过滤原始码流
我们可以不必关注上层应用协议是什么,上层的协议的header和data都属于tcp的data部分,所以我们可以通过tcp的data进行过滤我们想要的内容。
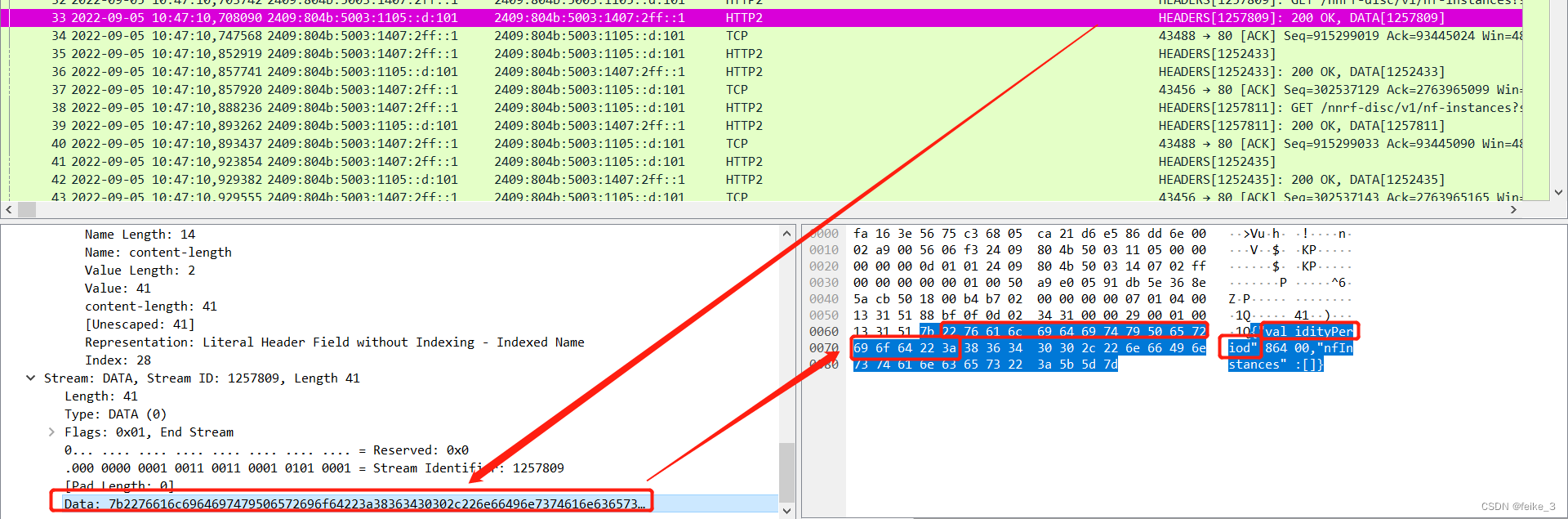
例如这个标记的200ok的数据包里的内容,wireshark就没能具体解码出来,我们将红框的16机制数copy出来:
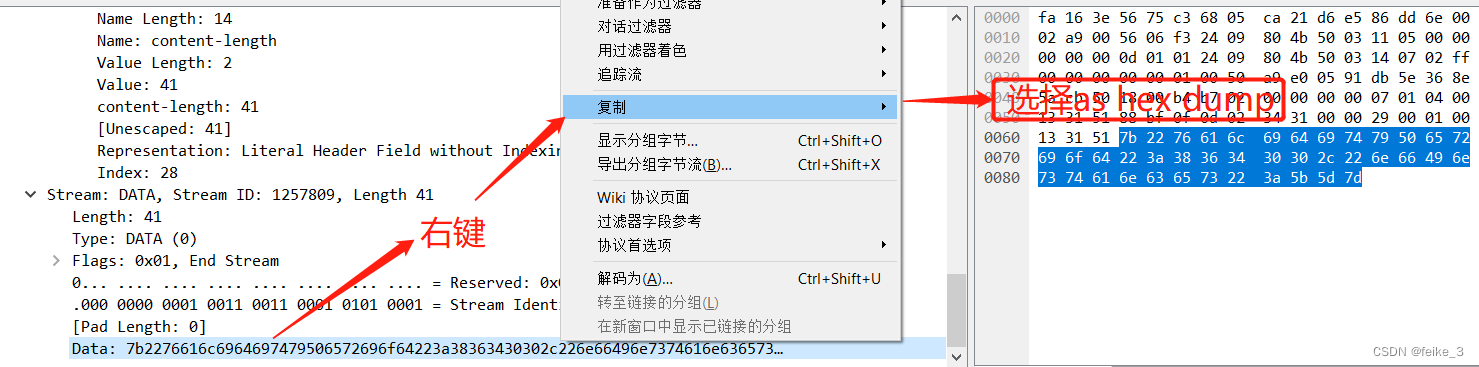
0000 7b == 22 76 6

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1282
1282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











