






一、基础知识
1.1 检索所有列
通配符(*)
检索出所有的列
select * from order;
一般而言,除非你确实需要表中的每一列,否则最好别使用*通配符。虽然使用通配符能让你自己省事,不用明确列出所需列,但检索不需要的列通常会降低检索速度和应用程序的性能。
1.2 检索不同的值
使用distinct关键字,顾名思义,指数据库只返回不同的值;
select distinct(t.name) from patient t;
输出结果
| ID | 姓名 |
|---|---|
| 1 | 张美林 |
| 2 | 朱萩垚 |
| 3 | 张凤春 |
| 4 | 段永丽 |
| 5 | 潘思睿 |
1.3 限制结果
Oracle,需要基于ROWNUM(行计数器)来计算行
select distinct(t.name) from patient t where rownum < 7;
1.4 注释
注释从/*开始,到*/结束,/*和*/之间的任何内容都是注释
1.5 排序检索数据
明确地排序用SELECT语句检索出的数据,可使用ORDER BY子句。ORDER BY子句取一个或多个列的名字,据此对输出进行排序。
select * from name t order by t.user_name desc;
输出结果
| ID | 姓名 |
|---|---|
| 1 | 张美林 |
| 2 | 朱萩垚 |
| 3 | 张凤春 |
| 4 | 段永丽 |
| 5 | 潘思睿 |
ORDER BY还支持按相对列位置进行排序;
select
t.id,
t.user_name,
t.people_name
from
name t
order by 1,3;
输出结果
| ID | 工号 | 姓名 |
|---|---|---|
| 1 | 1095 | 张再升 |
| 2 | 1096 | 吴莲芳 |
| 3 | 1097 | 巴春琴 |
| 4 | 1098 | 窦梅支 |
| 5 | 1099 | 赵灵芳 |
| 6 | 1100 | 吴艳玲 |
| 7 | 1101 | 唐有国 |
| 8 | 1102 | 丁国保 |
1.6 使用where子句
在select语句中,数据根据where子句中指定的搜索条件进行过滤。where子句在表名(from子句)之后给出;
where操作符

1.7 范围值检查
在使用between时,必须指定两个值——所需范围的低端值和高端值。这两个值必须用and关键字分隔。between匹配范围中所有的值,包括指定的开始值和结束值。
1.7 空值检查
在创建表时,表设计人员可以指定其中的列能否不包含值。在一个列不包含值时,称其包含空值NULL。
NULL
无值(no value),它与字段包含0、空字符串或仅仅包含空格不同。
select
t.id,
t.user_name,
t.people_name
from
name t
where
t.user_name is null;
1.8 字符串拼接
拼接(concatenate)
将值联结到一起(将一个值附加到另一个值)构成单个值;
根据你所使用的DBMS,此操作符可用加号(+)或两个竖杠(||)表示;
特殊注意事项
说明:是+还是||?
SQL Server使用+号。DB2、Oracle、PostgreSQL和SQLite使用||
select t.user_name || '(' || t.people_name || ')' as 姓名 from user t order by t.user_name;
输出结果
| ID | 工号姓名 |
|---|---|
| 1 | 1082(杜婷) |
| 2 | 1083(黑明伟) |
| 3 | 1085(顾芳娜) |
| 4 | 1088(杨永鸿) |
| 5 | 1096(吴莲芳) |
| 6 | 1105(苏绍能) |
| 7 | 1101(李四) |
| 8 | 1102(王五) |
rtrim()函数去掉值右边的所有空格。通过使用rtrim(),各个列都进行了整理;
说明:TRIM函数
大多数DBMS都支持RTRIM()(正如刚才所见,它去掉字符串右边的空格)、LTRIM()(去掉字符串左边的空格)以及TRIM()(去掉字符串左右两边的空格)
使用别名
从前面的输出可以看到,SELECT语句可以很好地拼接地址字段。但是,这个新计算列的名字是什么呢?实际上它没有名字,它只是一个值。如果仅在SQL查询工具中查看一下结果,这样没有什么不好。但是,一个未命名的列不能用于客户端应用中,因为客户端没有办法引用它。
解决方法
为了解决这个问题,SQL支持列别名。别名(alias)是一个字段或值的替换名。别名用AS关键字赋予。
1.9 执行算术计算
SQL算术操作符
提示:如何测试计算
SELECT语句为测试、检验函数和计算提供了很好的方法。虽然SELECT通常用于从表中检索数据,但是省略了FROM子句后就是简单地访问和处理表达式,例如SELECT 3*2;
例如:
select 3*2 —— 将返回6;
select trim(’ abc ') —— 将返回abc;
select curdate() —— 使用curdate()函数返回当前日期和时间
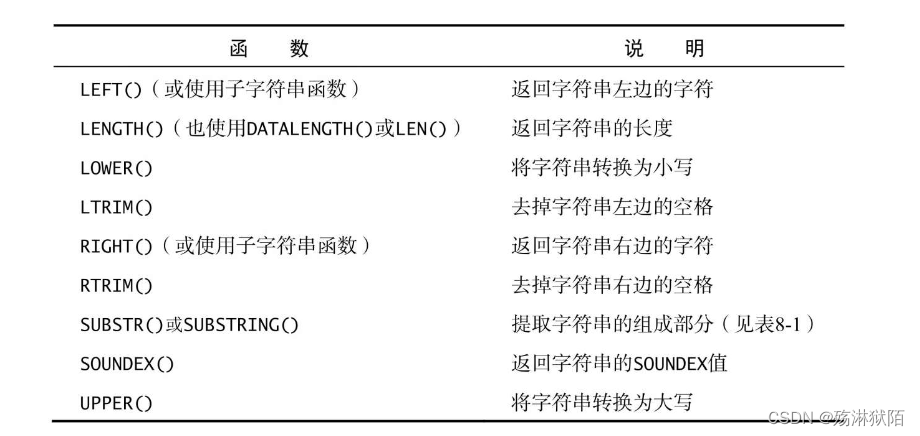
1.10 函数
SQL函数不区分大小写,因此upper(), UPPER(), Upper()都可以,substr(), SUBSTR(), SubStr()也都是可以的;
常见文本处理函数
数值处理函数

SQL聚集函数

1.11 where 语句和having语句
说明:
使用having和where非常类似,如果不指定group by,则大多数DBMS会同等对待它们。不过,你自己要能区分这一点。使用having时应该结合group by子句,而where子句用于标准的行级过滤。
说明:having和where的差别
这里有另一种理解方法,where在数据分组前进行过滤,having在数据分组后进行过滤。这是一个重要的区别,where排除的行不包括在分组中。这可能会改变计算值,从而影响having子句中基于这些值过滤掉的分组。
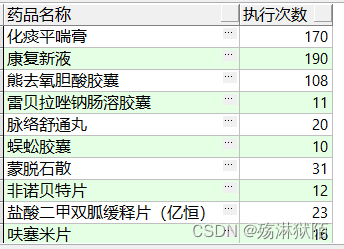
SQL
select
t.order_name as 药品名称,
count(1) as 执行次数
from work t
where t.usage_code = '口服'
and t.org_id_input = '综合楼制剂室' --开单科室
group by
t.order_name
having count(1) > 2;
输出结果
1.12 分组和排序

我们经常发现,用GROUP BY分组的数据确实是以分组顺序输出的。但并不总是这样,这不是SQL规范所要求的。此外,即使特定的DBMS总是按给出的GROUP BY子句排序数据,用户也可能会要求以不同的顺序排序。就因为你以某种方式分组数据(获得特定的分组聚集值),并不表示你需要以相同的方式排序输出。应该提供明确的ORDER BY子句,即使其效果等同于GROUP BY子句。
提示:
不要忘记ORDER BY一般在使用GROUP BY子句时,应该也给出ORDER BY子句。这是保证数据正确排序的唯一方法。千万不要仅依赖GROUP BY排序数据。
SQL
select
t.order_name as 药品名称,
count(1) as 执行次数
from work t
where t.usage_code = '口服'
and t.org_id_input = '综合楼制剂室' --开单科室
group by
t.order_name
having count(1) > 2
order by
执行次数;
输出结果

1.13 select子句顺序

1.14 小结
ORDER BY 对输出进行排序;
GROUP BY 分组排序,常和聚集函数搭配使用;
WHERE 行级过滤;
HAVING 组级过滤;
1.15 子查询
SELECT语句是SQL的查询。我们迄今为止所看到的所有SELECT语句都是简单查询,即从单个数据库表中检索数据的单条语句。
查询(query)
任何SQL语句都是查询。但此术语一般指SELECT语句。
SQL还允许创建子查询(subquery),即嵌套在其他查询中的查询。
可以把一条SELECT语句返回的结果用于另一条SELECT语句的WHERE子句。
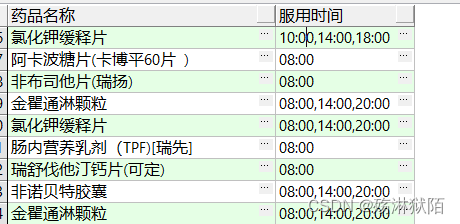
SQL
select
a.order_name as 药品名称,
a.time as 服用时间
from work a
where
a.order_id in(select
t.order_id
from item t
where t.ordered_by = '住院楼四楼-消化科' --患者所在科室
and t.performed_by = '医技楼三楼-西药房');--西药房
输出结果
在WHERE子句中使用子查询能够编写出功能很强且很灵活的SQL语句。对于能嵌套的子查询的数目没有限制,不过在实际使用时由于性能的限制,不能嵌套太多的子查询。
注意:只能是单列
作为子查询的SELECT语句只能查询单个列。企图检索多个列将返回错误。
注意:
子查询和性能这里给出的代码有效,并且获得了所需的结果。但是,使用子查询并不总是执行这类数据检索的最有效方法。
1.16 作为计算字段使用子查询
使用子查询的另一方法是创建计算字段。
问题阐述
假如需要显示work表中每个顾客的购药总数。订单与相应的顾客ID存储在work表中。执行这个操作,要遵循下面的步骤:
(1) 从work表中检索顾客列表;
(2) 对于检索出的每个顾客,统计其在item表中的订单数目。
正如前两课所述,可以使用SELECT COUNT(*)对表中的行进行计数,并且通过提供一条where子句来过滤某个特定的药品ID,仅对该顾客的订单进行计数。
SQL
select a.order_name,--药品名称
(select
count(*)
from item t
where t.order_id = a.order_id) as 次数
from work a
group by
a.order_name,
a.order_id;
输出结果
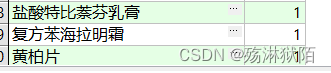
注意:
完全限定列名你已经看到了为什么要使用完全限定列名,没有具体指定就会返回错误结果,因为DBMS会误解你的意思。有时候,由于出现冲突列名而导致的歧义性,会引起DBMS抛出错误信息。例如,WHERE或ORDER BY子句指定的某个列名可能会出现在多个表中。好的做法是,如果在SELECT语句中操作多个表,就应使用完全限定列名来避免歧义。
提示:
不止一种解决方案正如这一课前面所述,虽然这里给出的样例代码运行良好,但它并不是解决这种数据检索的最有效方法。在后面两课学习JOIN时,我们还会遇到这个例子。
1.17 联结
1.17.1 联结
SQL最强大的功能之一就是能在数据查询的执行中联结(join)表。联结是利用SQL的SELECT能执行的最重要的操作,很好地理解联结及其语法是学习SQL的极为重要的部分。
主要的关键点,相同的数据出现多次决不是一件好事,这是关系数据库设计的基础。关系表的设计就是要把信息分解成多个表,一类数据一个表。各表通过某些共同的值互相关联(所以才叫关系数据库)。
由于数据不重复,数据显然是一致的,使得处理数据和生成报表更简单。总之,关系数据可以有效地存储,方便地处理。因此,关系数据库的可伸缩性远比非关系数据库要好。
可伸缩(scale)
能够适应不断增加的工作量而不失败。设计良好的数据库或应用程序称为可伸缩性好(scale well)。
为什么要使用联结??
因为需要将数据分解为多个表能更有效地存储,更方便地处理,并且可伸缩性更好。
说明:使用交互式DBMS工具
重要的是,要理解联结不是物理实体。换句话说,它在实际的数据库表中并不存在。DBMS会根据需要建立联结,它在查询执行期间一直存在。许多DBMS提供图形界面,用来交互式地定义表关系。这些工具极其有助于维护引用完整性。在使用关系表时,仅在关系列中插入合法数据是非常重要的。引用完整性表示DBMS强制实施数据完整性规则。这些规则一般由提供了界面的DBMS管理。
警告:
完全限定列名就像前一课提到的,在引用的列可能出现歧义时,必须使用完全限定列名(用一个句点分隔表名和列名)。如果引用一个没有用表名限制的具有歧义的列名,大多数DBMS会返回错误。
WHERE子句的重要性
WHERE子句作为过滤条件,只包含那些匹配给定条件(这里是联结条件)的行。
笛卡儿积(cartesian product)
由没有联结条件的表关系返回的结果为笛卡儿积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。
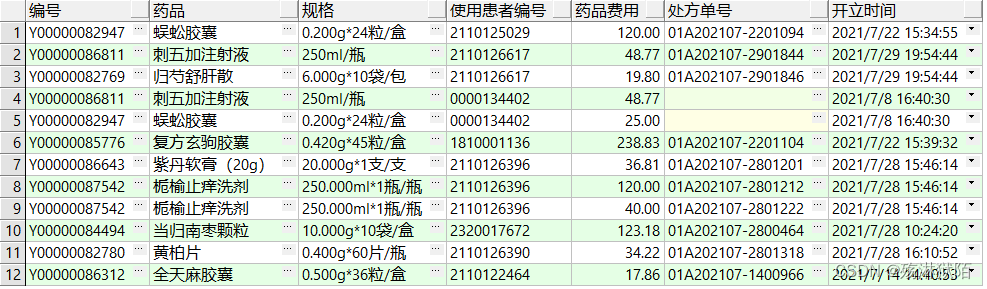
SQL
select t.pham_std_code as 编号,
t.pham_name as 药品,
t.pham_spec as 规格,
b.patient_id as 使用患者编号,
b.costs as 药品费用,
b.apply_id as 处方单号,
b.charge_date as 开立时间
from pham t,item b
where t.pham_code = b.item_code
and t.pham_cate_code = '中成药';
运行结果
注意:
不要忘了WHERE子句要保证所有联结都有WHERE子句,否则DBMS将返回比想要的数据多得多的数据。同理,要保证WHERE子句的正确性。不正确的过滤条件会导致DBMS返回不正确的数据。
提示:叉联结有时,返回笛卡儿积的联结,也称叉联结(cross join)。
1.17.2 内联结
目前为止使用的联结称为等值联结(equijoin),它基于两个表之间的相等测试。这种联结也称为内联结(inner join)。其实,可以对这种联结使用稍微不同的语法,明确指定联结的类型。
在使用这种语法时,联结条件用特定的ON子句而不是WHERE子句给出。传递给ON的实际条件与传递给WHERE的相同。
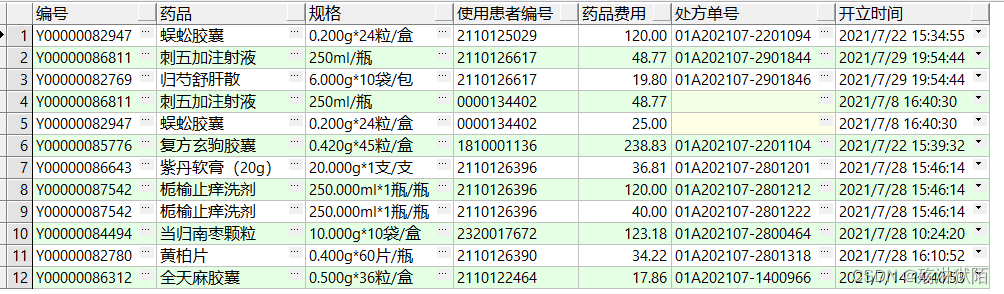
SQL
select t.pham_std_code as 编号,
t.pham_name as 药品,
t.pham_spec as 规格,
b.patient_id as 使用患者编号,
b.costs as 药品费用,
b.apply_id as 处方单号,
b.charge_date as 开立时间
from pham t
inner join item b on t.pham_code = b.item_code
and t.pham_cate_code = '中成药';
运行结果
说明:“正确的”语法
ANSI SQL规范首选INNER JOIN语法,之前使用的是简单的等值语法。其实,SQL语言纯正论者是用鄙视的眼光看待简单语法的。这就是说,DBMS的确支持简单格式和标准格式,我建议你要理解这两种格式,具体使用就看你用哪个更顺手了。
1.17.3 联结多个表
SQL不限制一条SELECT语句中可以联结的表的数目。创建联结的基本规则也相同。首先列出所有表,然后定义表之间的关系。
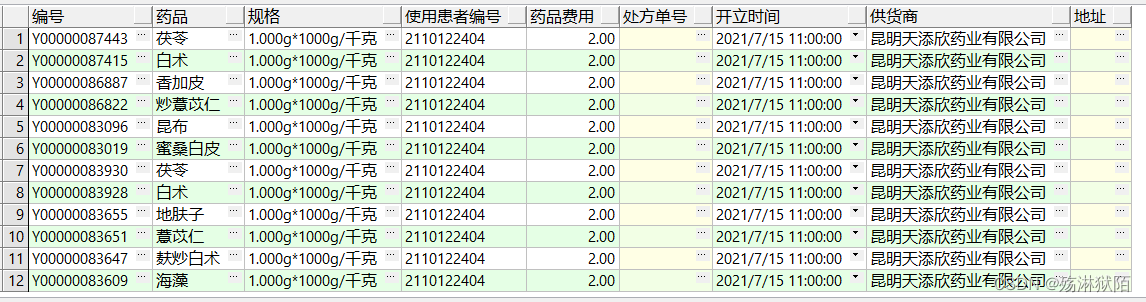
SQL
select t.pham_std_code as 编号,
t.pham_name as 药品,
t.pham_spec as 规格,
b.patient_id as 使用患者编号,
b.costs as 药品费用,
b.apply_id as 处方单号,
b.charge_date as 开立时间,
c.supplier as 供货商,
c.ent_addr as 地址
from pham t,item b, supplier c
运行结果
注意:性能考虑
DBMS在运行时关联指定的每个表,以处理联结。这种处理可能非常耗费资源,因此应该注意,不要联结不必要的表。联结的表越多,性能下降越厉害。
注意:联结中表的最大数目
虽然SQL本身不限制每个联结约束中表的数目,但实际上许多DBMS都有限制。请参阅具体的DBMS文档以了解其限制。
提示:
多做实验可以看到,执行任一给定的SQL操作一般不止一种方法。很少有绝对正确或绝对错误的方法。性能可能会受操作类型、所使用的DBMS、表中数据量、是否存在索引或键等条件的影响。因此,有必要试验不同的选择机制,找出最适合具体情况的方法。
说明:
联结的列名上述所有例子里,联结的几个列的名字都是一样的。列名相同并不是必需的,而且你经常会遇到命名规范不同的数据库。简单起见较为重要。
1.17.4 小结
联结是SQL中一个最重要、最强大的特性,有效地使用联结需要对关系数据库设计有基本的了解。需要掌握一些关系数据库设计的基本知识,包括等值联结(也称为内联结)这种最常用的联结。
1.18 使用表别名
实例(以Oracle为主)
select rtrim(t.patient_id) || '(' || rtrim(t.item_name) || ')' as 项目
from item t
order by
t.patient_id;
运行结果
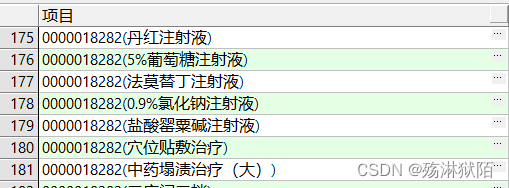
SQL除了可以对列名和计算字段使用别名,还允许给表名起别名。
这样做有两个主要理由:
❑ 缩短SQL语句;
❑ 允许在一条SELECT语句中多次使用相同的表。
SQL
select t.pham_std_code as 编号,
t.pham_name as 药品,
t.pham_spec as 规格,
b.patient_id as 使用患者编号,
b.costs as 药品费用,
b.apply_id as 处方单号,
b.charge_date as 开立时间
from pham t,item b
where t.pham_code = b.item_code
and t.pham_cate_code = '中成药'
order by t.pham_std_code;
如1.17中的这个例子,表别名只用于WHERE子句。其实它不仅能用于WHERE子句,还可以用于SELECT的列表、ORDER BY子句以及其他语句部分。
1.19 使用表别名使用带聚集函数的联结
聚集函数用来汇总数据
内联结:inner join … on
实例
select
b.item_code 药品序号,
b.item_name 药品,
count(1) as 数量,--统计药品使用数量
d.pham_spec as 药品规格
from item b
inner join pham d on d.pham_std_code = b.item_code
group by --进行分组排序
b.item_code,
b.item_name,
d.pham_spec;
运行结果
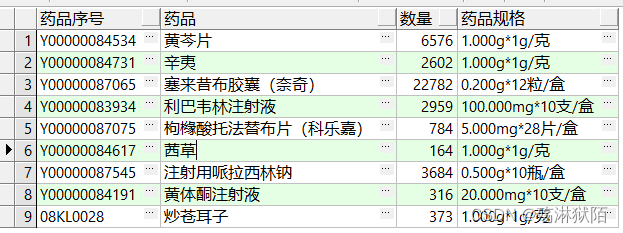
汇总一下联结及其使用的要点:
❑ 注意所使用的联结类型。一般我们使用内联结,但使用外联结也有效。
❑ 关于确切的联结语法,应该查看具体的文档,看相应的DBMS支持何种语法。
❑ 保证使用正确的联结条件(不管采用哪种语法),否则会返回不正确的数据。
❑ 应该总是提供联结条件,否则会得出笛卡儿积。
❑ 在一个联结中可以包含多个表,甚至可以对每个联结采用不同的联结类型。虽然这样做是合法的,一般也很有用,但应该在一起测试它们前分别测试每个联结。这会使故障排除更为简单。
1.20 组合查询
如何利用UNION操作符将多条SELECT语句组合成一个结果集:
多数SQL查询只包含从一个或多个表中返回数据的单条SELECT语句。但是,SQL也允许执行多个查询(多条SELECT语句),并将结果作为一个查询结果集返回。这些组合查询通常称为并(union)或复合查询(compound query)。
主要有两种情况需要使用组合查询:
❑ 在一个查询中从不同的表返回结构数据;
❑ 对一个表执行多个查询,按一个查询返回数据。
提示:组合查询和多个WHERE条件多数情况下,组合相同表的两个查询所完成的工作与具有多个WHERE子句条件的一个查询所完成的工作相同。
union 语法
select column_name(s) from table1
union
select column_name(s) from table2;
UNION规则:
可以看到,UNION非常容易使用,但在进行组合时需要注意几条规则。
❑ UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔(因此,如果组合四条SELECT语句,将要使用三个UNION关键字)。
❑ UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过,各个列不需要以相同的次序列出)。
❑ 列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含转换的类型(例如,不同的数值类型或不同的日期类型)。
UNION从查询结果集中自动去除了重复的行;换句话说,它的行为与一条SELECT语句中使用多个WHERE子句条件一样。使用UNION时,重复的行会被自动取消。
事实上,如果想返回所有的匹配行,可使用UNION ALL而不是UNION。
提示:UNION与WHERE
UNION几乎总是完成与多个WHERE条件相同的工作。UNION ALL为UNION的一种形式,它完成WHERE子句完成不了的工作。如果确实需要每个条件的匹配行全部出现(包括重复行),就必须使用UNION ALL,而不是WHERE。
SQL UNION ALL 语法
select column_name(s) from table1
UNION ALL
select column_name(s) from table2;
对组合查询结果排序
SELECT语句的输出用ORDER BY子句排序。在用UNION组合查询时,只能使用一条ORDER BY子句,它必须位于最后一条SELECT语句之后。对于结果集,不存在用一种方式排序一部分,而又用另一种方式排序另一部分的情况,因此不允许使用多条ORDER BY子句。
联结
A inner join B 取交集。
A left join B 取 A 全部,B 没有对应的值为 null
A right join B 取 B 全部 A 没有对应的值为 null
A full outer join B 取并集,彼此没有对应的值为 null
对应条件在 on 后面填写
小试牛刀
SQL25 查找山东大学或者性别为男生的信息
描述:
题目:现在运营想要分别查看学校为山东大学或者性别为男性的用户的device_id、gender、age和gpa数据,请取出相应结果,结果不去重。
题意明确:
分别查看学校为山东大学或者性别为男性的用户的device_id、gender、age和gpa数据,结果不去重;
问题分解:
限定条件:学校为山东大学或者性别为男性的用户:university=‘山东大学’, gender=‘male’;
分别查看&结果不去重:所以直接使用两个条件的or是不行的,直接用union也不行,要用union all,分别去查满足条件1的和满足条件2的,然后合在一起不去重;
SQL
select
a.device_id,
a.gender,
a.age,
a.gpa
from
user_profile a
where
a.university = '山东大学'
union all
select
b.device_id,
b.gender,
b.age,
b.gpa
from
user_profile b
where
b.gender = 'male'
运行结果

1.21 数据插入
insert用来将行插入(或添加)到数据库表
插入有几种方式:
❑ 插入完整的行;
❑ 插入行的一部分;
❑ 插入某些查询的结果;
1.21.1 插入完整的行
把数据插入表中的最简单方法是使用基本的INSERT语法,它要求指定表名和插入到新行中的值。
语法
INSERT INTO table_name
VALUES (value1,value2,value3,...);
在某些SQL实现中,跟在INSERT之后的INTO关键字是可选的。但是,即使不一定需要,最好还是提供这个关键字,这样做将保证SQL代码在DBMS之间可移植。
说明:不能插入同一条记录两次
注意:小心使用VALUES
不管使用哪种INSERT语法,VALUES的数目都必须正确。如果不提供列名,则必须给每个表列提供一个值;如果提供列名,则必须给列出的每个列一个值。否则,就会产生一条错误消息,相应的行不能成功插入。
1.21.2 插入行的一部分
使用INSERT的推荐方法是明确给出表的列名。使用这种语法,还可以省略列,这表示可以只给某些列提供值,给其他列不提供值。
注意:省略列
如果表的定义允许,则可以在INSERT操作中省略某些列。省略的列必须满足以下某个条件。
❑ 该列定义为允许NULL值(无值或空值)。
❑ 在表定义中给出默认值。这表示如果不给出值,将使用默认值。
注意:省略所需的值
如果表中不允许有NULL值或者默认值,这时却省略了表中的值,DBMS就会产生错误消息,相应的行不能成功插入。
插入数据
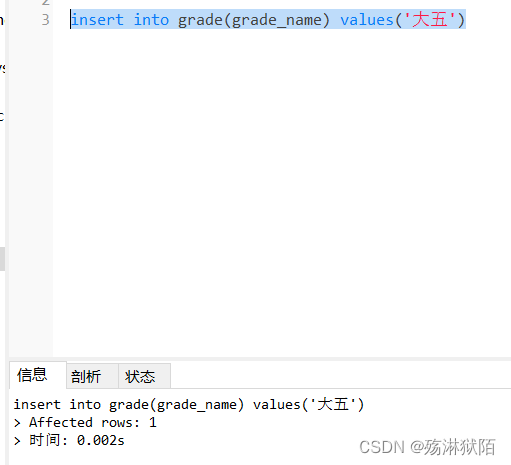
查询结果
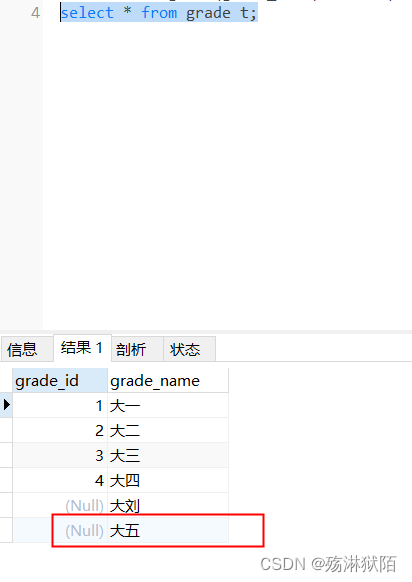
1.21.3 插入检索出的数据
INSERT还存在另一种形式,可以利用它将SELECT语句的结果插入表中,这就是所谓的INSERT SELECT。顾名思义,它是由一条INSERT语句和一条SELECT语句组成的。
insert into select 和select into from 的区别
--插入一行,要求表scorebak 必须存在
insert into scorebak select * from socre where neza='neza'
--也是插入一行,要求表scorebak 不存在
select * into scorebak from score where neza='neza'
提示:
INSERT SELECT中的列名为简单起见,这个例子在INSERT和SELECT语句中使用了相同的列名。但是,不一定要求列名匹配。事实上,DBMS一点儿也不关心SELECT返回的列名。它使用的是列的位置,因此SELECT中的第一列(不管其列名)将用来填充表列中指定的第一列,第二列将用来填充表列中指定的第二列,等等。
INSERT SELECT中SELECT语句可以包含WHERE子句,以过滤插入的数据。
1.22 复制表
有一种数据插入不使用INSERT语句。要将一个表的内容复制到一个全新的表(运行中创建的表),可以使用CREATE SELECT语句;
语法:
create table 表名1 as select * from 表名2;
1.23 更新和删除数据
1.23.1 更新数据
更新(修改)表中的数据,可以使用UPDATE语句。有两种使用UPDATE的方式:
❑ 更新表中的特定行;
❑ 更新表中的所有行。
注意:不要省略WHERE子句
在使用UPDATE时一定要细心。因为稍不注意,就会更新表中的所有行;
提示:UPDATE与安全
在客户端/服务器的DBMS中,使用UPDATE语句可能需要特殊的安全权限。在你使用UPDATE前,应该保证自己有足够的安全权限。
UPDATE语法:
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
参数说明:
table_name:要修改的表名称。
column1, column2, ...:要修改的字段名称,可以为多个字段。
value1, value2, ...:要修改的值,可以为多个值。
condition:修改条件,用于指定哪些数据要修改。
使用UPDATE语句非常容易,甚至可以说太容易了。
基本的UPDATE语句由三部分组成,分别是:
❑ 要更新的表;
❑ 列名和它们的新值;
❑ 确定要更新哪些行的过滤条件。
在更新多个列时,只需要使用一条SET命令,每个“列=值”对之间用逗号分隔(最后一列之后不用逗号)。
1.23.2 删除数据
从一个表中删除(去掉)数据,使用DELETE语句。有两种使用DELETE的方式:
❑ 从表中删除特定的行;
❑ 从表中删除所有行。
注意:不要省略WHERE子句
在使用DELETE时一定要细心。因为稍不注意,就会错误地删除表中所有行。
提示:和UPDATE一样,DELETE与安全在客户端/服务器的DBMS中,使用DELETE语句可能需要特殊的安全权限。在你使用DELETE前,应该保证自己有足够的安全权限。
提示:FROM关键字
在某些SQL实现中,跟在DELETE后的关键字FROM是可选的。但是即使不需要,也最好提供这个关键字。这样做将保证SQL代码在DBMS之间可移植。
DELETE 语法
DELETE FROM table_name
WHERE condition;
参数说明:
table_name:要删除的表名称。
condition:删除条件,用于指定哪些数据要删除。
说明:删除表的内容而不是表
DELETE语句从表中删除行,甚至是删除表中所有行。但是,DELETE不删除表本身。
提示:更快的删除如果想从表中删除所有行,不要使用DELETE。可使用TRUNCATE TABLE语句,它完成相同的工作,而速度更快(因为不记录数据的变动)。
1.23.3 更新和删除的指导原则
使用的UPDATE和DELETE语句都有WHERE子句,这样做的理由:如果省略了WHERE子句,则UPDATE或DELETE将被应用到表中所有的行。换句话说,如果执行UPDATE而不带WHERE子句,则表中每一行都将用新值更新。类似地,如果执行DELETE语句而不带WHERE子句,表的所有数据都将被删除。
使用UPDATE或DELETE时所遵循的重要原则。
❑ 除非确实打算更新和删除每一行,否则绝对不要使用不带WHERE子句的UPDATE或DELETE语句。
❑ 保证每个表都有主键,尽可能像WHERE子句那样使用它(可以指定各主键、多个值或值的范围)。
❑ 在UPDATE或DELETE语句使用WHERE子句前,应该先用SELECT进行测试,保证它过滤的是正确的记录,以防编写的WHERE子句不正确。
❑ 使用强制实施引用完整性的数据库,这样DBMS将不允许删除其数据与其他表相关联的行。
❑ 有的DBMS允许数据库管理员施加约束,防止执行不带WHERE子句的UPDATE或DELETE语句。如果所采用的DBMS支持这个特性,应该使用它。
















 1537
1537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











