








本章需要学习的知识有:
- 学习处理文件,让程序能够快速的分析大量数据;
- 如何处理一些错误,避免程序在面临一些意外的情况产生崩溃;
- 学习异常,它们是Python创建时的特殊对象,用于管理程序运行时出现的错误;
- 还需要学习
JSON模块保存用户数据,以免这些数据在程序结束运行后丢失。
学习处理文件和保存数据能让自己编写的程序更易于使用:用户能够选择输入什么样的数据以及在什么时候输入;用户使用程序做完一些工作之后,可将程序关闭,以后接着往下做。学习处理异常可帮助应对文件不存在等等情况,以及处理其他可能导致程序崩溃的问题。这让程序在面对错误的数据时更稳健 — 不管这些错误数据源自无意的错误,还是出于破坏程序的恶意企图。文件和异常这部分知识可以提高程序的适用性、可用性以及稳定性。
实际开发中常常会遇到对数据进行持久化的场景,所谓持久化是指将数据从无法长久保存数据的存储介质(通常是内存)转移到可以长久保存数据的存储介质(通常是硬盘)中。实现数据持久化最直接简单的方式就是通过文件系统将数据保存到文件中。
计算机的文件系统是一种存储和组织计算机数据的方法,它使得对数据的访问和查找变得容易,文件系统使用文件和树形目录的抽象逻辑概念代替了硬盘、光盘、闪存等物理设备的数据块概念,用户使用文件系统来保存数据时,不必关心数据实际保存在硬盘的哪个数据块上,只需要记住这个文件的路径和文件名。在写入新数据之前,用户不必关心硬盘上的哪个数据块没有被使用,硬盘上的存储空间管理(分配和释放)功能由文件系统自动完成,用户只需要记住数据被写入到了哪个文件中。
10.1 读取文件
文本文件可存储的数据多得令人难以置信:天气数据、交通数据、社会经济数据、文学作品等等。每当需要分析或修改存储在文件中的信息时,读取文件就非常的重要,对数据分析应用程序来说也是这样的。比如,可以编写一个程序来读取文件文本文件中的内容,并且以新的格式重写该文件,让浏览器能够显示。
要使用文本文件中的信息,首先需要将信息读取到内存中,既可以一次性读取文件的全部内容,也可以逐行读取。
在 Python 中,Path(来自 pathlib 模块)和 open() 函数都与文件操作相关,但它们的用途和功能有显著差异。以下是它们的异同点及典型用途:
1. 核心区别
| 特性 | pathlib.Path | open() |
|---|---|---|
| 功能定位 | 路径操作(创建、解析、管理文件/目录路径) | 文件内容操作(读写文件内容) |
| 所属模块 | pathlib(Python 3.4+) | 内置函数,无需导入 |
| 返回对象 | Path 对象(路径的抽象表示) | 文件对象(如 TextIOWrapper) |
| 主要用途 | 路径解析、文件元数据操作、目录管理 | 读写文件内容(文本或二进制) |
2. 核心用途
pathlib.Path
-
路径操作:
- 创建、拼接路径:
Path("/dir") / "file.txt"。 - 检查路径是否存在:
Path("file.txt").exists()。 - 获取文件属性(大小、修改时间等):
Path("file.txt").stat()。 - 创建/删除目录或文件:
Path("dir").mkdir(),Path("file.txt").unlink()。
- 创建、拼接路径:
-
简化文件读写:
- 快捷读写文本:
Path("file.txt").read_text(),write_text()。 - 快捷读写二进制:
Path("file.png").read_bytes(),write_bytes()。
- 快捷读写文本:
-
跨平台兼容性:
- 自动处理不同操作系统的路径分隔符(如
\vs/)。
- 自动处理不同操作系统的路径分隔符(如
open()
- 文件内容操作:
- 打开文件并返回文件对象,支持多种模式(
r,w,a,rb,wb等)。 - 逐行读取、写入、追加内容。
- 支持上下文管理器(
with open(...) as f),确保资源释放。
- 打开文件并返回文件对象,支持多种模式(
- 精细控制:
- 处理大文件时逐行读取(避免内存问题)。
- 指定编码(如
encoding="utf-8")或错误处理策略。
3. 相同点
-
文件系统交互:二者均用于操作文件或目录。
-
上下文管理器:均支持
with语句(如with Path("file.txt").open() as f或with open("file.txt") as f)。 -
组合使用:
Path对象可通过.open()方法调用open()函数:from pathlib import Path path = Path("data/file.txt") with path.open(mode="r", encoding="utf-8") as f: content = f.read()
4. 何时选择?
- 使用
Path的场景:- 需要操作路径(如拼接、检查存在性、创建目录)。
- 快速读写小文件(直接调用
.read_text()/.write_text())。 - 需要跨平台兼容的路径处理。
- 使用
open()的场景:- 需要逐行读取或写入大文件。
- 需要精细控制文件读写(如二进制模式、指定编码、追加内容)。
- 直接处理文件内容流(如网络传输、流式处理)。
5. 代码示例
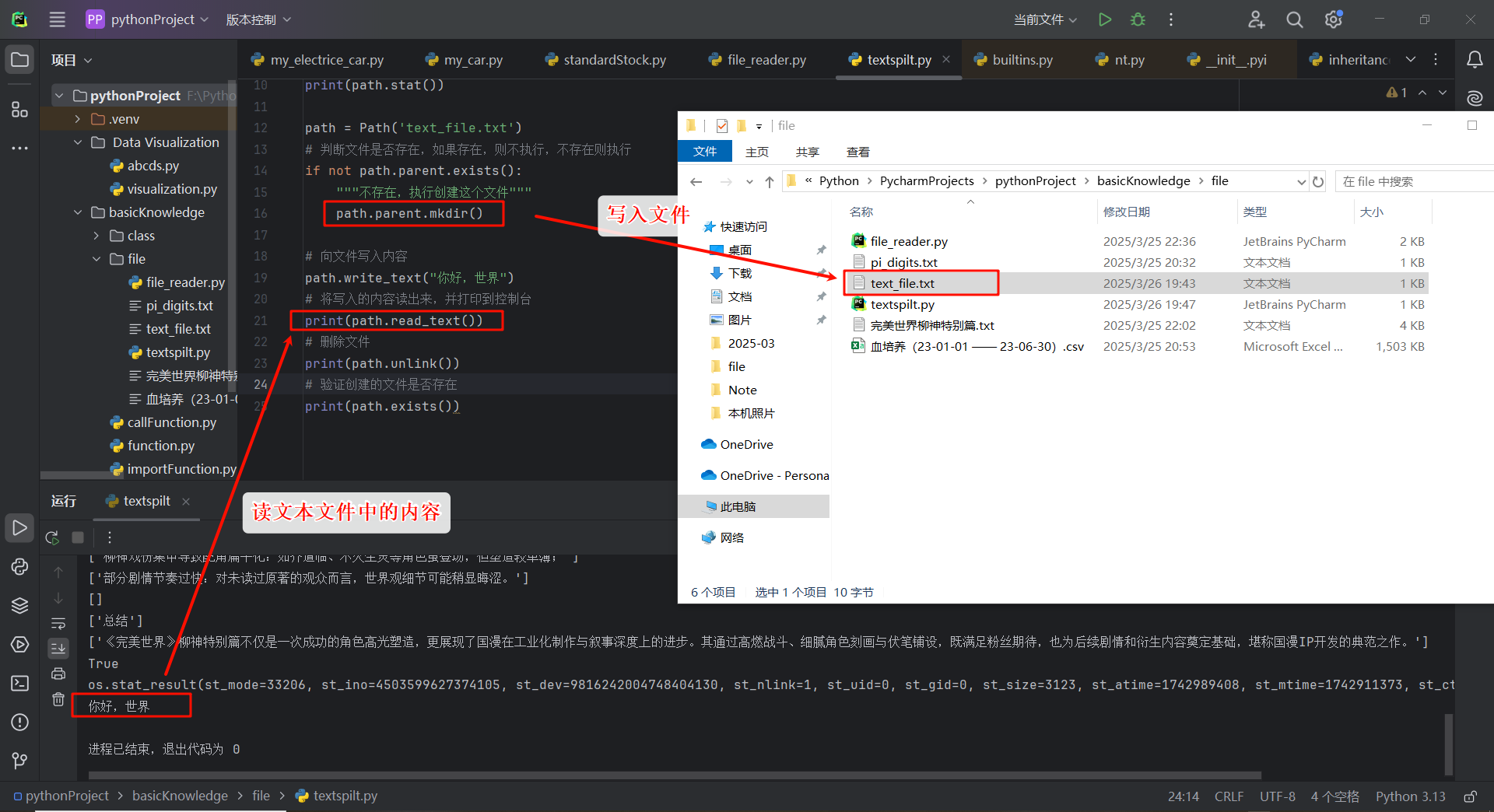
Path 的典型用法
path = Path('text_file.txt')
# 判断文件是否存在,如果存在,则不执行,不存在则执行
if not path.parent.exists():
"""不存在,执行创建这个文件"""
path.parent.mkdir()
# 向文件写入内容
path.write_text("你好,世界")
# 将写入的内容读出来,并打印到控制台 结果:你好,世界
print(path.read_text())
# 删除文件
print(path.unlink())
# 验证创建的文件是否存在 结果:False
print(path.exists())
open() 的典型用法
# 写入文件
with open("data/file.txt", "w", encoding="utf-8") as f:
f.write("Hello, open()!")
# 逐行读取大文件
with open("data/large.log", "r") as f:
for line in f:
process_line(line)
总结
Path:专注于路径管理和简单文件读写,提供面向对象的 API,适合路径操作和快速文件操作。open():专注于文件内容读写,提供底层控制,适合处理复杂或大型文件。
二者通常结合使用:用 Path 管理路径,再用 Path.open() 或内置 open() 处理内容。
10.1.1 读取文件的全部内容
要读取文件,需要一个包含若干行文本的文件。下面来创建一个文件,它包含精确到小数点后30位的圆周率数值,且在小数点后每10位处换行。
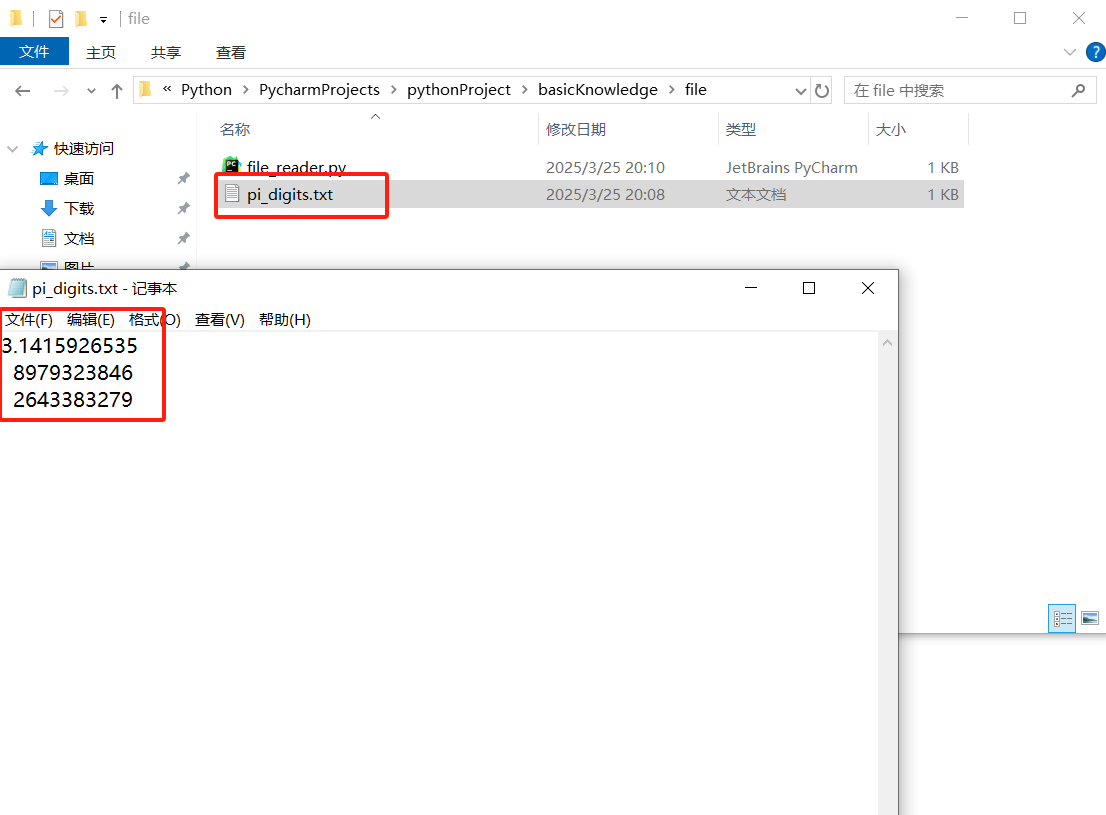
程序如下:
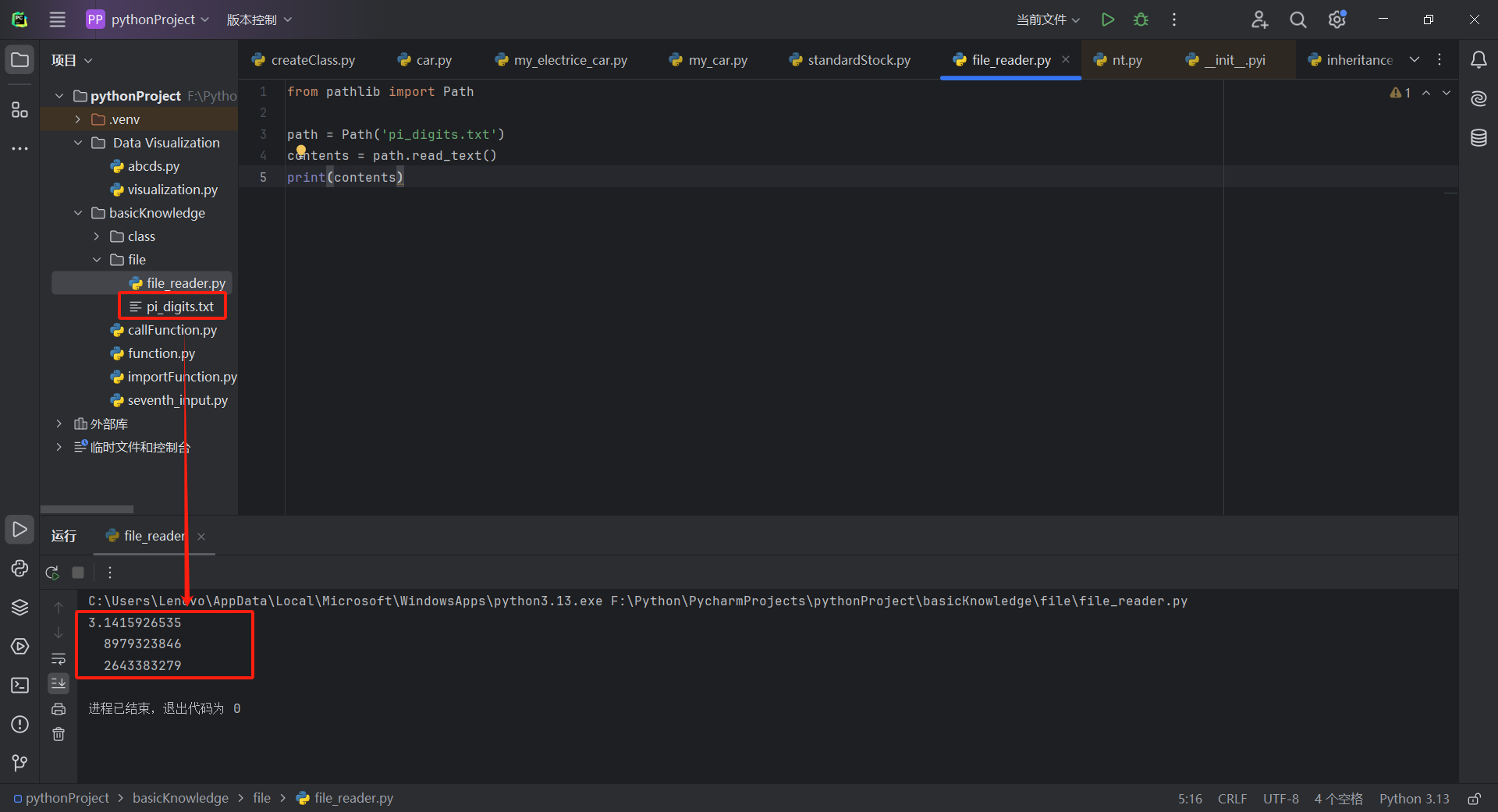
from pathlib import Path
path = Path('pi_digits.txt')
contents = path.read_text()
print(contents)
运行结果:
要使用文件中的内容,需要将其路径告诉Python,路径(path)指的是文件或文件夹在系统中的精确位置。Python提供了pathlib模块,让你能够更轻松地在各种操作系统中处理文件和目录。提供特定功能的模块通常称为库(library)。这就是这个模块被命名为pathlib的原因了。
这里首先从pathlib模块导入Path类。Path对象指向一个文件,可以用来做很多的事情。比如验证你在使用文件前核实它是否存在,读取文件的内容,以及将新数据写入文件。在上面的程序中,创建了一个pi_digits.txt的Path对象,并将其赋值给变量path。由于这个文件与当前编写的.py文件位于同一个目录中,因此Path只需要知道它的文件名就可以访问该文件的内容。
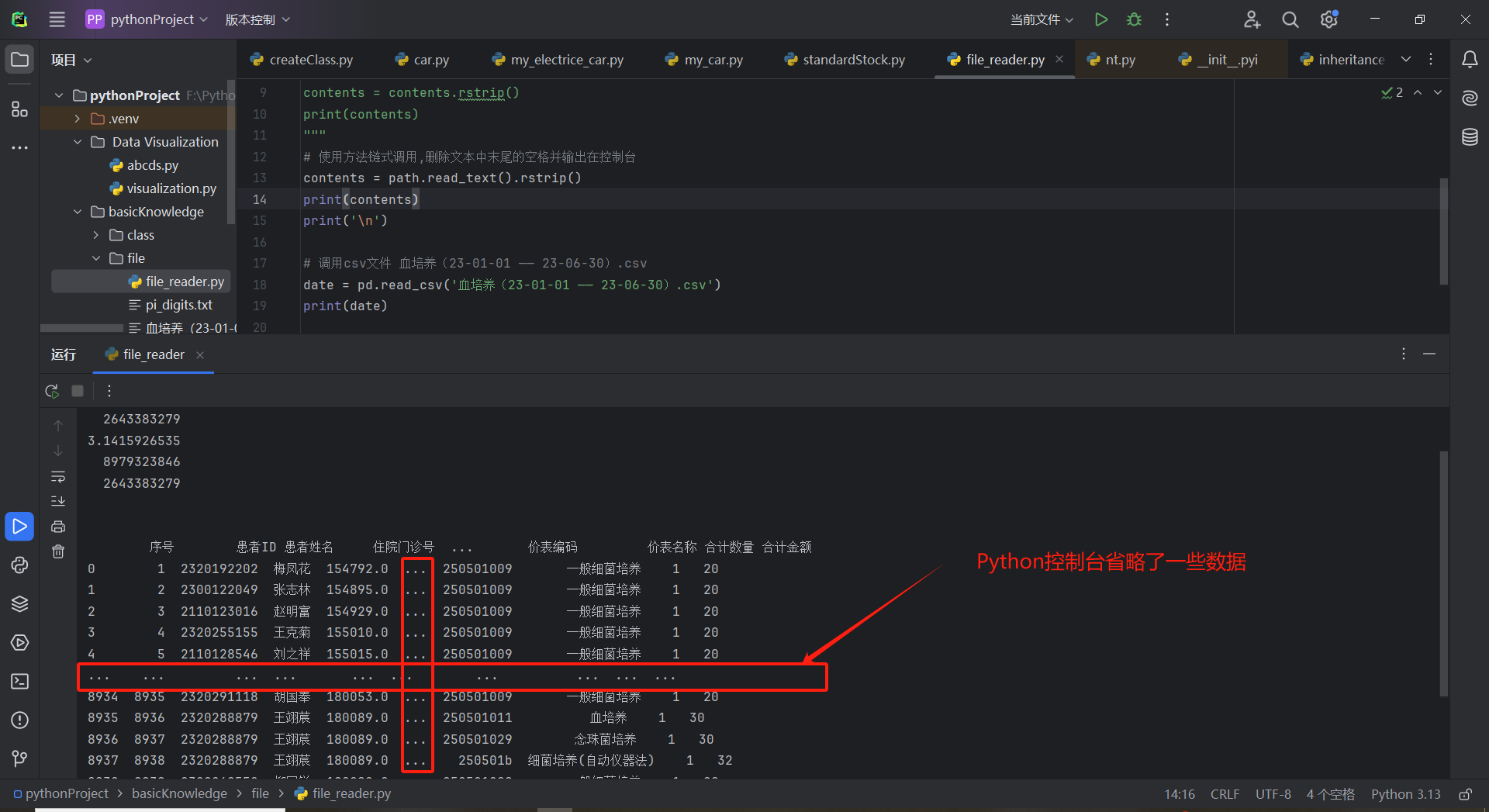
创建文件pi_digits.txt的Path对象后,使用read_text()方法来读取文件的全部内容。read_text()将该文件的全部内容作为一个字符串返回,我们将这个字符串赋给变量contents。在打印contents的值时,将显示这个文本文件的全部内容,如上图:
相比原始文件,该输出唯一不同的地方是末尾多了一个空行。为何会多出这个空行,是因为read_text()在到达文件末尾时会返回一个空字符串,而这个空字符串被现实一个空行。
如果要删除这个空行,可对字符串变量contents调用rstrip():
from pathlib import Path
import pandas as pd
path = Path('pi_digits.txt')
contents = path.read_text()
print(contents)
"""使用rstrip()方法能够删除字符串末尾的空白"""
"""
contents = contents.rstrip()
print(contents)
"""
# 使用方法链式调用,删除文本中末尾的空格并输出在控制台
contents = path.read_text().rstrip()
print(contents)
print('\n')
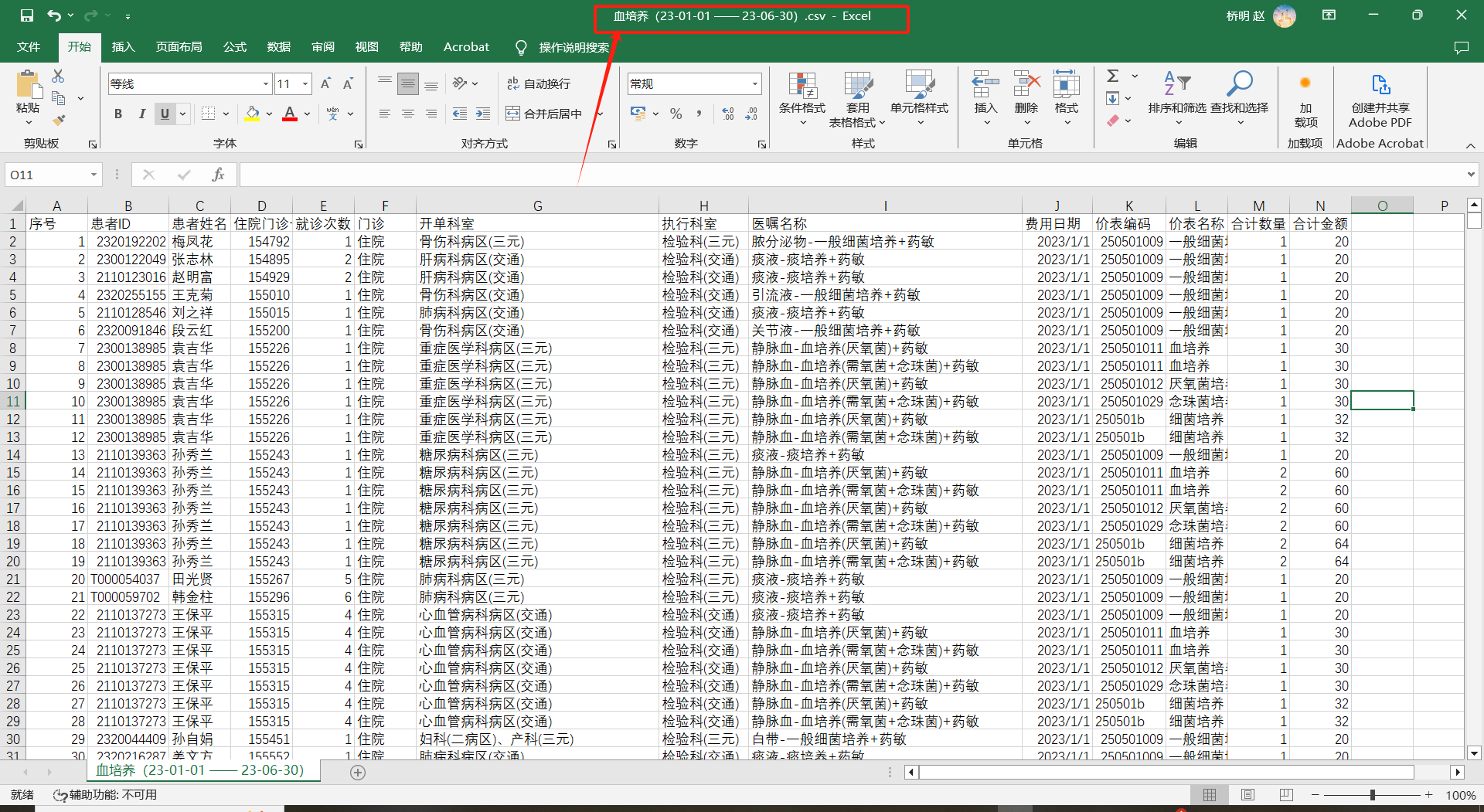
# 调用csv文件 血培养(23-01-01 —— 23-06-30).csv
date = pd.read_csv('血培养(23-01-01 —— 23-06-30).csv')
print(date)
csv文件内容:
输出结果:
10.1.2 相对文件路径和绝对文件路径
当将类似于pi_digits.txt这样的简单文件名传给Path时,Python将在当前执行的文件(即.py程序文件)所在的目录中查找。
根据你组织文件的方式,有时可能要打开不在程序文件所属目录中的文件。例如,你可能将程序文件存储在Google中,并且在文件夹Google中创建了一个名为text_files的文件夹,用于存储程序文件要操作的文本文件。虽然文件夹text_files在Google中,但仅想Path传递文件夹text_files中的文件名称是不可行的,因为Python只在文件夹Google中查找,而不会在子文件夹text_files中查找。要让Python打开不予程序文件位于同一个目录中的文件,则需要提供正确的路径。
在编程中,指定路径的方式有两种。首先,相对文件路径让Python到相对于当前运行程序的所在目录的指定位置去查找。由于文件夹text_files位于文件夹Google中,因此需要创建一个以text_files打头并以文件名结尾的路径,如下所示:
path = Path('text_files/filename.txt')
其次,可以将文件在计算机周的精确位置告诉Python,这样就不用管当前运行的程序存储在声明地方了,而这就成为绝对文件路径。在相对路径行不通时,就需要使用绝对文件路径。例如,如果text_files并不在文件夹Google中,而在文件夹other_files中,则向Path传递路径'text_files/ filename.txt'行不通,因为Python只在文件夹Google中查找该位置。为明确地指出你希望Python到哪里去查找,你需要提供完整的路径。
绝对文件路径通常比相对文件路径长,因为它们以系统的根文件夹为起点:
path = Path('/home/ehmatthes/other_files/text_files/filename.txt')
使用绝对路径,可读取系统中任何地方的文件。就目前而言,最简单的做法是,要么将数据存储在程序文件所在的目录中,要么将其存储在程序文件所在目录下的一个文件夹(如text_files)中。
注意:
在显示文件路径时,Windows系统使用反斜杠(\)而不是斜杠(/)。但是在代码中应该始终使用斜杠,即便是在Windows系统中也是这样的。在与你与其他用户的系统交互时,pathlib库会自动使用正确的路径表示方法。
10.1.3 访问文件中的各行
在使用文件时,经常需要检查文件中的每一行:①可能需要再文件中查找特定的信息;②或者以某种方式修改文件中的文本。例如,在分析天气时,可能要遍历一个包含天气数据的文件,并使用天气描述中包含sunny字样的行;在新闻报道中,可能要查找包含标记<headline>的行,并按特定的格式进行改写。
你可以使用splitlines()方法将冗长的字符串转换为一系列行,再使用for循环以每次一行的方式检查文件中的各行:
from pathlib import Path
path = Path('pi_digits.txt')
contents = path.read_text()
"""
使用splitlines()方法将冗长的字符串转换为一系列行,并将其转换成列表,后使用for循环以每次一行的方式检查文件中的各行
"""
lines = contents.splitlines()
print(f'使用splitlines()方法转换后的结果:{lines}。\n')
# 遍历列表
for line in lines:
print(line)
运行结果:
使用splitlines()方法转换后的结果:['3.1415926535', ' 8979323846', ' 2643383279 ']。
# 遍历列表
3.1415926535
8979323846
2643383279
使用whth以及open()来读取文件中的文本内容:
# 逐行读取大文件
with open('完美世界柳神特别篇.txt','r',encoding="utf-8") as f:
for line in f:
"""不进行换行"""
print(line.rstrip())
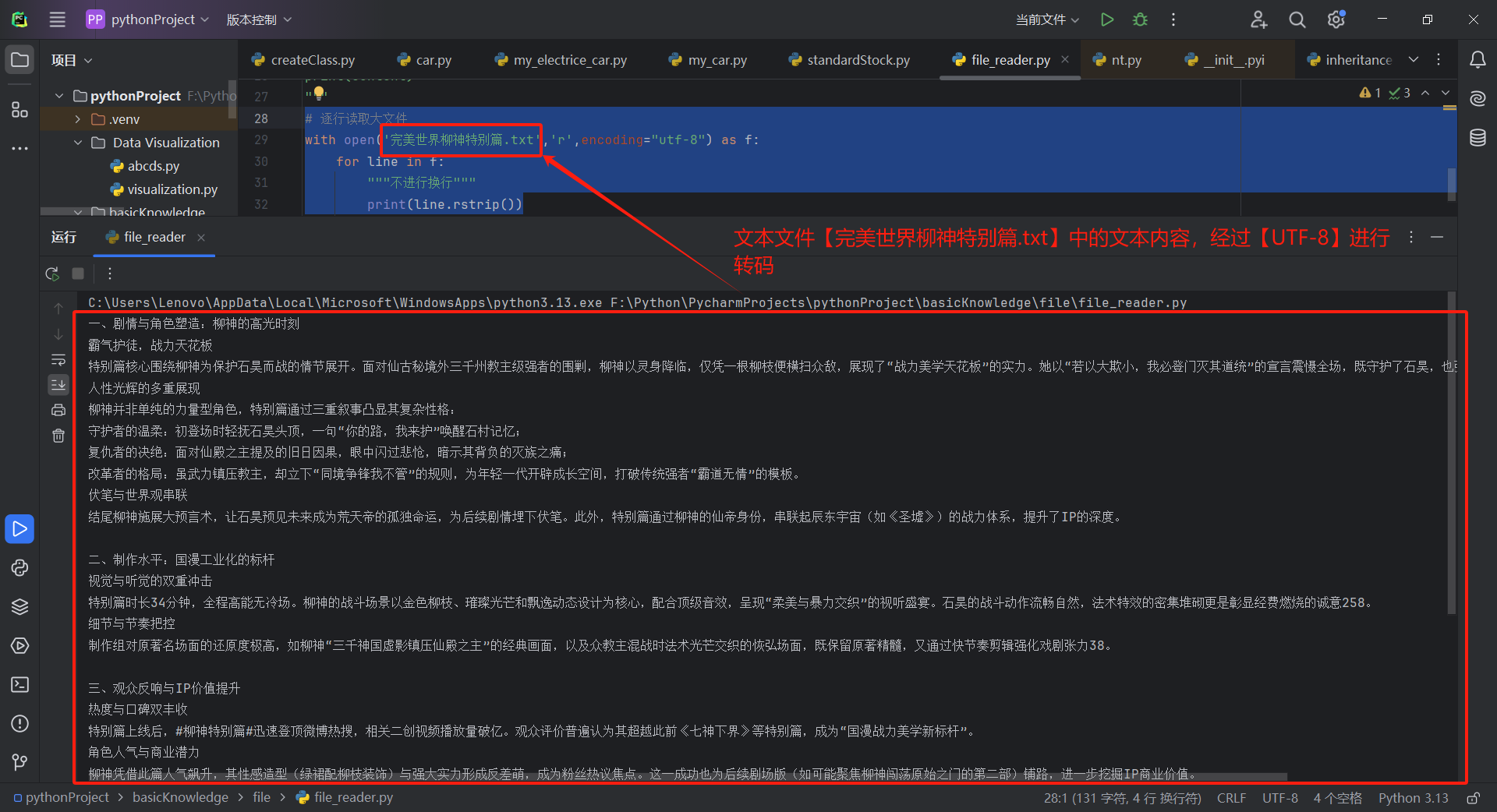
重点:
在 Python 中,splitlines() 方法和 with 语句是两种不同用途的工具,但它们在处理文件和多行文本时经常结合使用。以下是它们的核心作用及适用场景的详细说明:
1. splitlines() 方法的作用
splitlines() 是字符串对象的方法,用于将多行文本按行分割成列表。其特点是:
- 智能分割:自动识别不同操作系统的换行符(如
\n、\r\n、\r),而无需手动指定分隔符。 - 控制保留行尾符:通过参数
keepends=True可以保留每行的换行符(默认False会去除)。
示例代码
text = "第一行\n第二行\r\n第三行\r"
lines = text.splitlines()
# 输出:['第一行', '第二行', '第三行']
print(lines)
lines_with_ends = text.splitlines(keepends=True)
# 输出:['第一行\n', '第二行\r\n', '第三行\r']
print(lines_with_ends)
lines_split = text.split()
# 字符(包括\n\r\t\f和空格),将会丢弃
# 输出:['第一行', '第二行', '第三行']
print(lines_split)
适用场景
- 从文件或网络请求中读取的多行文本需要按行处理时。
- 需要统一处理不同换行符的场景(如跨平台数据解析)。
- 避免手动分割时因换行符不一致导致的错误(例如
split("\n")无法处理\r\n)。
2. with 语句的作用
with 语句用于资源管理,确保文件、网络连接等资源在使用后自动释放(如关闭文件),避免资源泄漏。其核心机制是通过上下文管理器的 __enter__ 和 __exit__ 方法实现。
示例代码
# 自动关闭文件,无需手动调用 f.close()
with open("data.txt", "r", encoding="utf-8") as f:
content = f.read()
适用场景
- 文件操作(读写文件)。
- 网络连接或数据库连接的打开与关闭。
- 需要确保资源释放的复杂操作(如线程锁
with threading.Lock())。
3. splitlines() 和 with 的结合使用场景
当需要从文件中读取多行文本并按行处理时,通常需要结合 with 和 splitlines():
- 使用
with安全地打开文件并读取内容。 - 用
splitlines()将读取的文本按行分割。
示例代码
with open('完美世界柳神特别篇.txt','r',encoding="utf-8") as f:
# 读取整个文件的内容
contents = f.read()
# 输出到控制台
print(contents + '\n')
# 按行分隔
lines = contents.splitlines()
print(lines)
# 逐行遍历列表lines
for i in lines:
print(i)
运行结果:
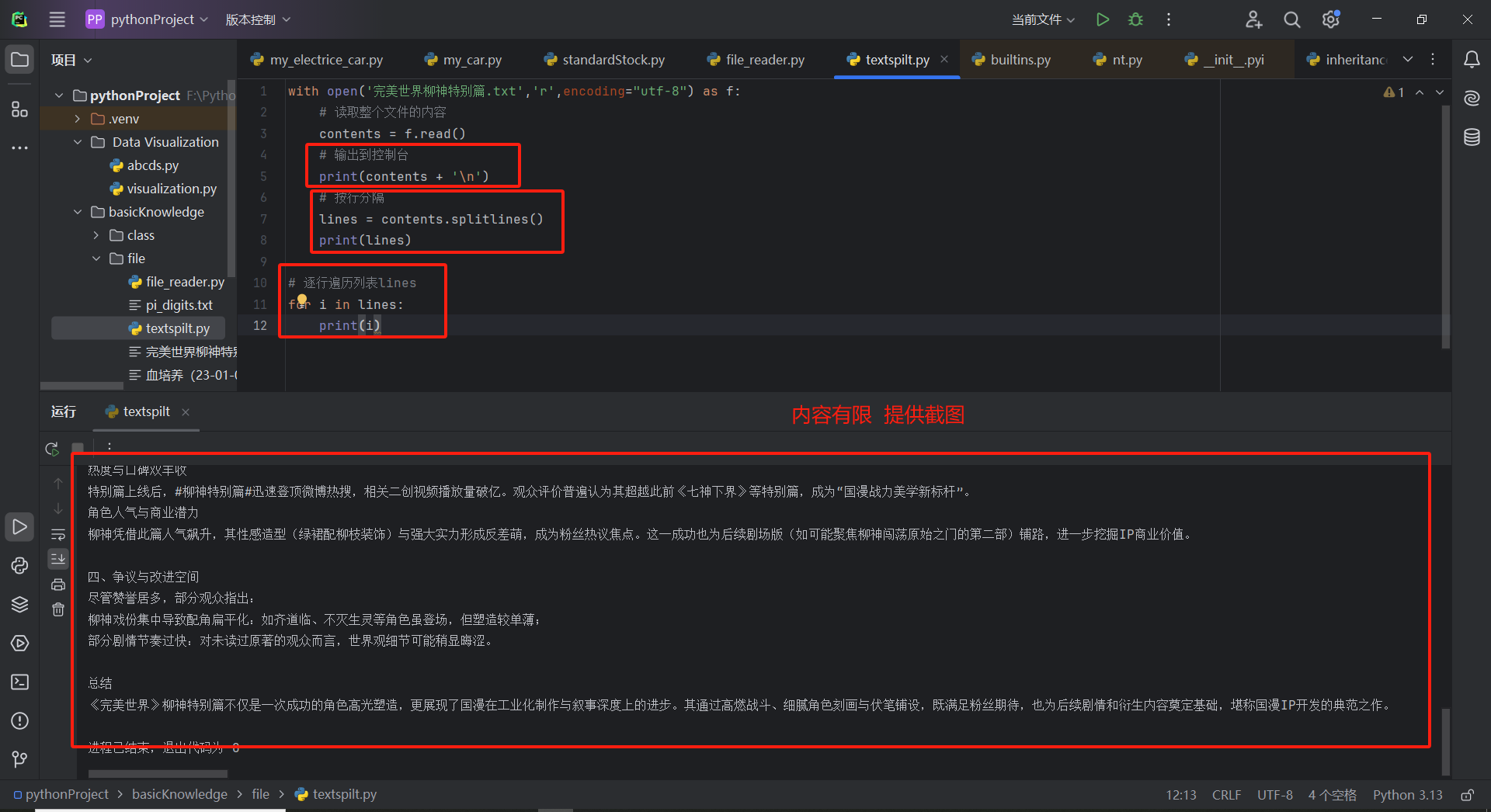
替代方案:逐行读取
如果文件较大,直接使用 splitlines() 可能占用过多内存。此时应结合 with 和文件对象的迭代特性逐行处理:
with open('完美世界柳神特别篇.txt','r',encoding = "utf-8") as f:
for line in f:
print(line.split())
4. 何时使用 splitlines() vs 直接逐行读取?
| 场景 | 使用 splitlines() | 直接逐行读取 |
|---|---|---|
| 文件较小 | ✔️ 适合(一次性加载到内存) | ✔️ 也适用 |
| 文件较大 | ❌ 内存可能不足 | ✔️ 逐行处理,内存友好 |
| 需要所有行同时处理 | ✔️ 方便(如统计行数、排序等) | ❌ 需额外存储到列表 |
| 跨平台换行符处理 | ✔️ 自动统一处理 | ✔️ Python 已自动处理(line 不带换行符) |
5. 总结
splitlines():用于将多行文本字符串按行分割为列表,适合需要统一处理换行符的场景。with语句:用于安全管理资源(如文件操作),确保资源释放。- 结合使用:在读取文件后需要按行处理时,先用
with打开文件,再用splitlines()分割内容;大文件则优先逐行读取。
10.1.4 使用文件的内容
将文件的内容读取到内存后,就能以任意方式使用这些数据了。比如'pi_digits.txt'存储了圆周率小数点后三十位,现在将它读出来,将这些数字按行读出,存储到列表中,如下:
from pathlib import Path
path = Path('pi_digits.txt')
# 读文本文件中的内容
content = path.read_text()
# 按行存储
lines = content.splitlines()
# 打印lines
print(f"按行分隔后的内容为:{lines}。\n")
# 定义一个空的字符串
str_line = ''
# 使用for循环遍历lines并存储到str_line中
for i in lines:
str_line += i
# 输出字符串str_line
print(str_line)
# 打印字符串的长度
print(len(str_line))
# 打印lines
按行分隔后的内容为:['3.1415926535', ' 8979323846', ' 2643383279 ']。
# 输出字符串str_line
3.1415926535 8979323846 2643383279
# 打印字符串的长度
38
但是对于上面的内容,我如何获得一个完整的精确到小数点后三十位的圆周率呢?它的输出结果如下:
按行分隔后的内容为:['3.1415926535', ' 8979323846', ' 2643383279 ']。
首先,看上面的数据结果,可以知道,有空格产生,为了删除这些空格,我们应该使用lstrip()左删除空格以及rstrip()右删除空格或者strip()来实现,我使用循环来实现,如下:
# 将空格删除
b = ''
for a in str_line:
b += a.strip()
print(b)
输出结果:
3.141592653589793238462643383279
注意:
在读取文本文件时,Python将其中的所有文本都解释为字符串。如果读取的是数,并且要将其作为数值使用,就必须使用int()函数将其转换为整数,或者使用float()函数将其转换为浮点数。
使用with来读取文件:
# 使用with来读取文本文件中的内容
with open('完美世界柳神特别篇.txt','r',encoding = 'utf-8') as line:
# 读取内容
content = line.read()
# 按行读取
contents = content.splitlines()
print(f"得到按行读取的内容:{contents}。")
# 定义一个字符串来存储contents中内容
str_content = ''
for i in contents:
str_content += i.strip()
print(str_content)
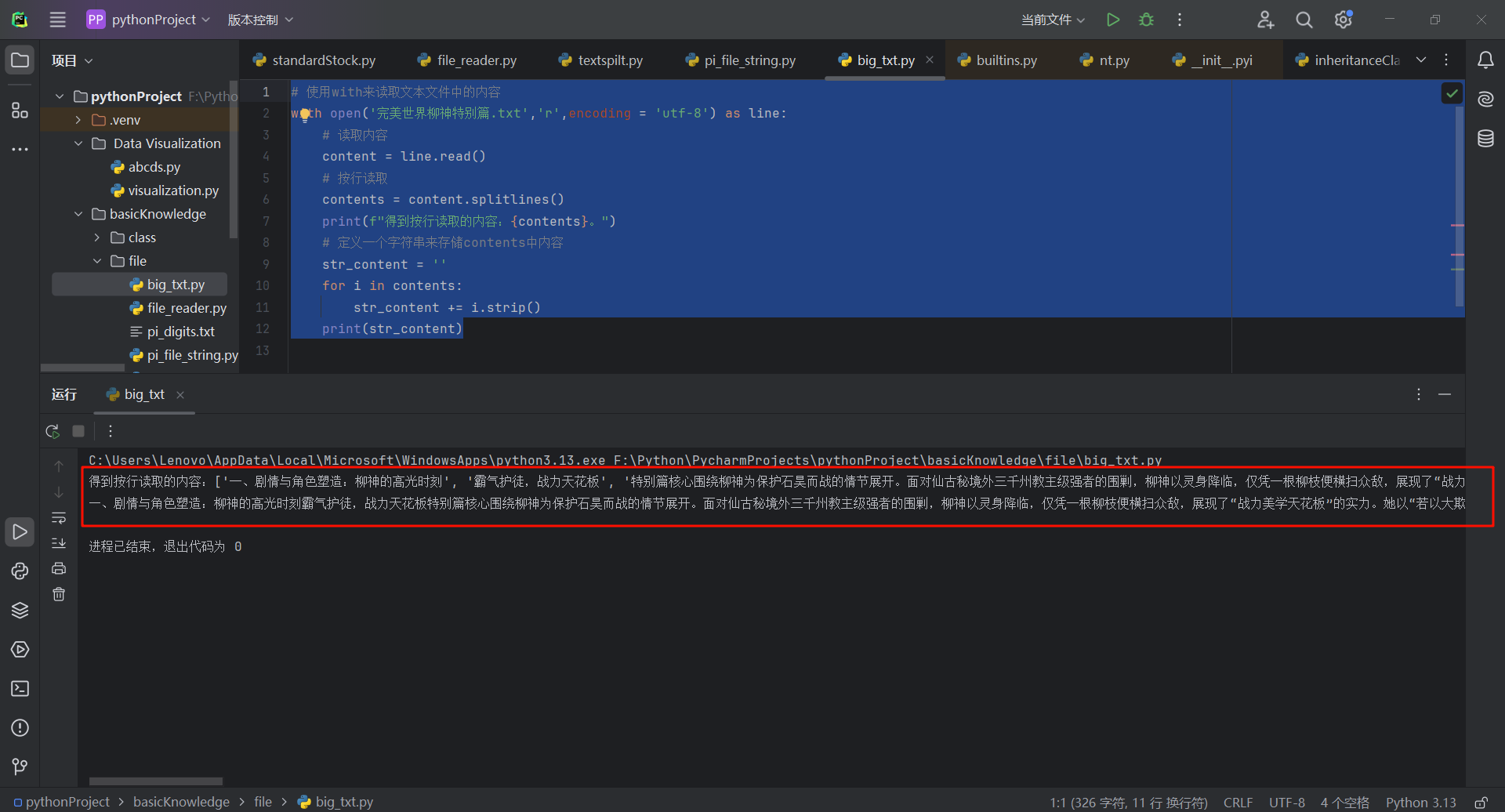
10.1.5 包含100万位的大型文件
对于上面的例子,我在控制台打印的内容太多,这样看起来就不美观,那我我想要得到一、剧情与角色塑造:柳神的高光时刻霸气护徒,战力天花板特别篇核心围绕柳神为保护石昊而战的情节展开.................的形式,又该怎么弄呢?如下:
# 使用列表进行截取
print(f"{str_content[:48]}.................")
一、剧情与角色塑造:柳神的高光时刻霸气护徒,战力天花板特别篇核心围绕柳神为保护石昊而战的情节展开.................
10.2 写入文件
保存数据最简单的方式之一就是写入文件,通过将输出写入文件,即便关闭包含程序输出的终端窗口,这些输出也是依然存在的,既可以在程序运行结束后查看这些输出,也可以与他人共享输出的文件,还可以编写程序来将这些输出读取到内存中并进行处理。
10.2.1 写入一行
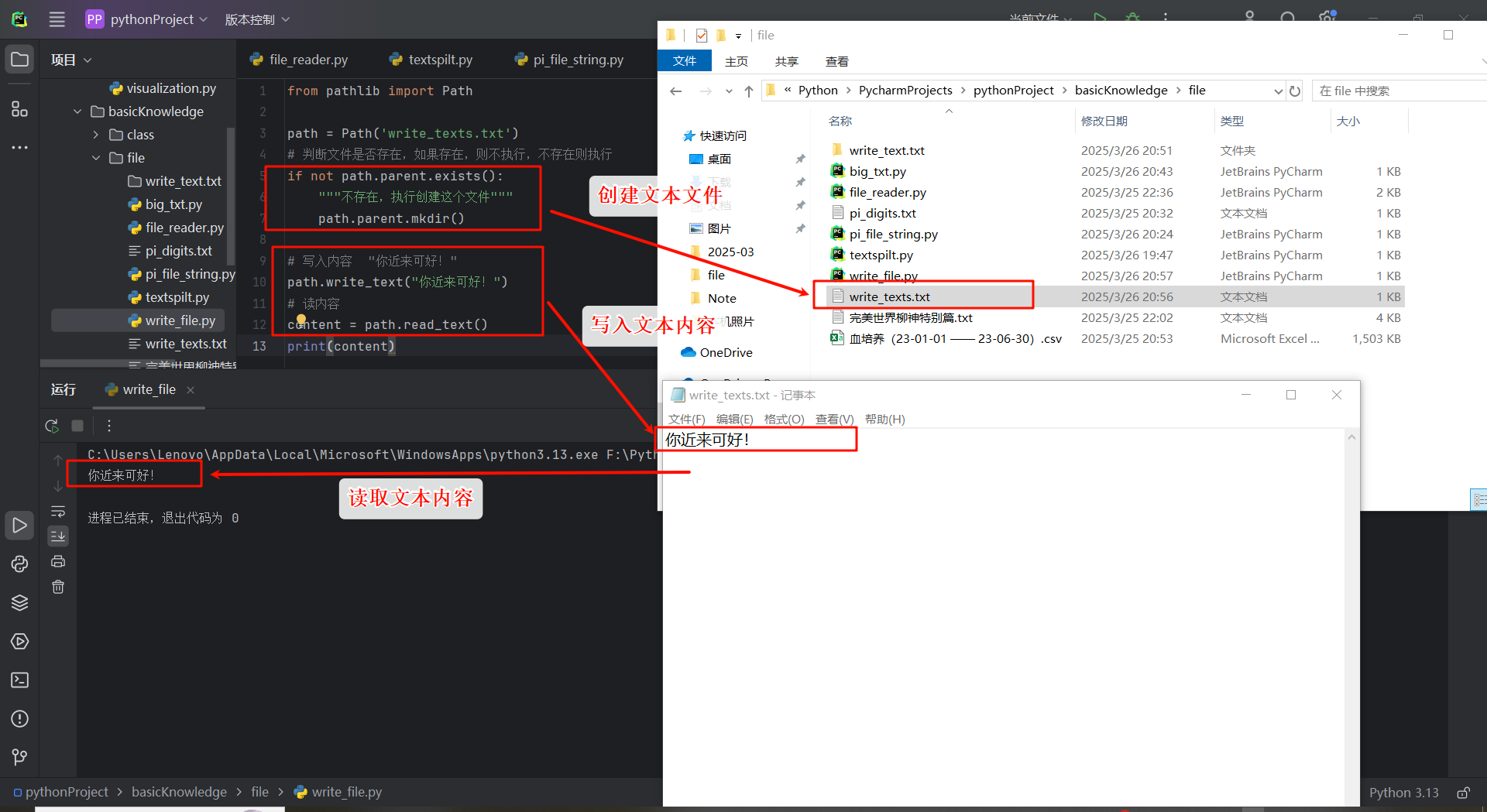
定义一个文件的路径后,便可以使用write_text()将数据写入文件中。如下:
from pathlib import Path
path = Path('write_texts.txt')
# 判断文件是否存在,如果存在,则不执行,不存在则执行
if not path.parent.exists():
"""不存在,执行创建这个文件"""
path.parent.mkdir()
# 写入内容 "你近来可好!"
path.write_text("你近来可好!")
# 读内容
content = path.read_text()
print(content)
10.2.1 写入多行
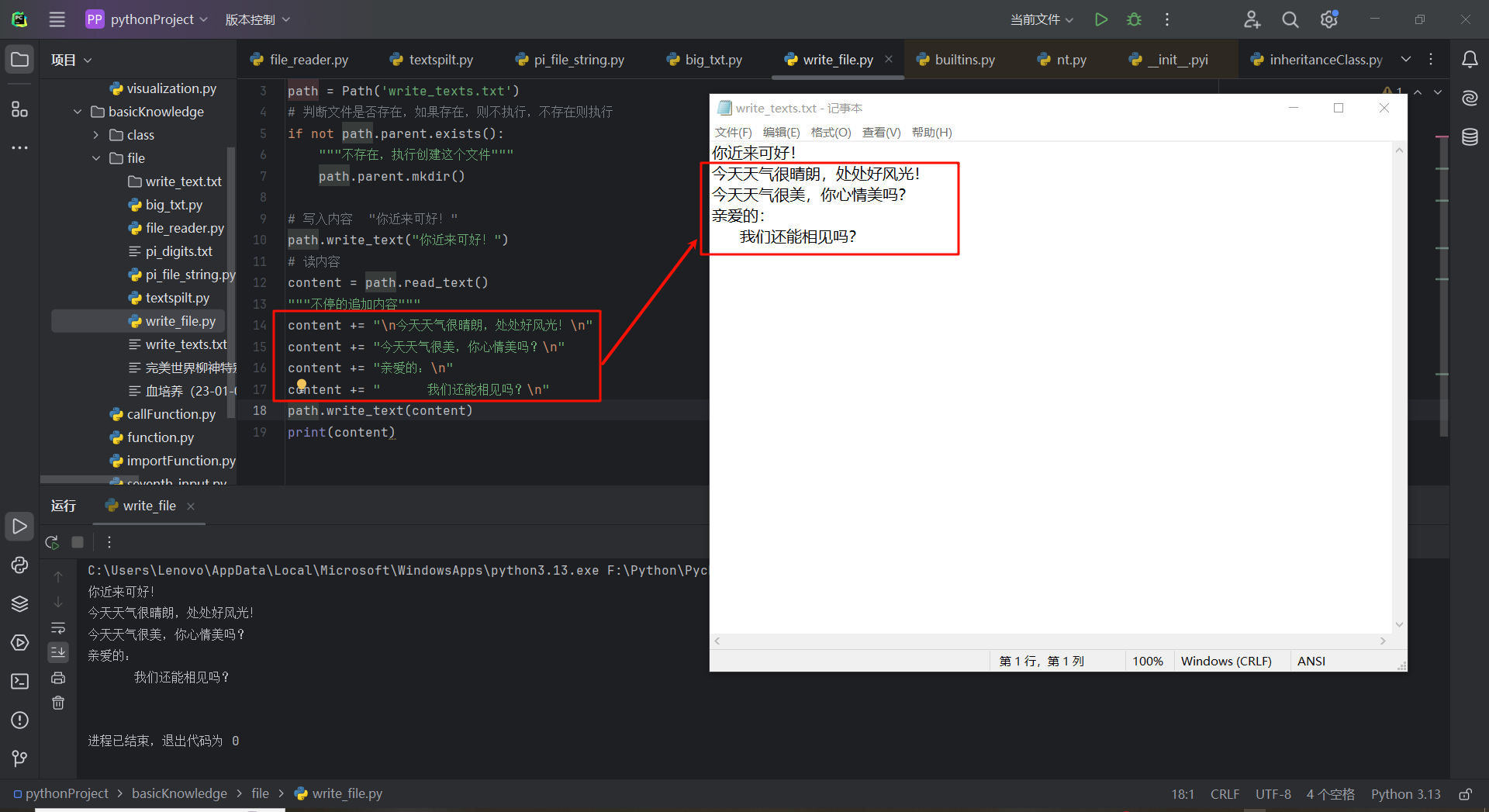
write_text()方法会在后台完成很多的工作。首先,如果path变量对应的路径指向的文件不存在,就创建它,其次将字符串写入文件,它会确保文件得以妥善的关闭。如果没有妥善的关闭文件,则可能会导致内容损坏或者丢失。
from pathlib import Path
path = Path('write_texts.txt')
# 判断文件是否存在,如果存在,则不执行,不存在则执行
if not path.parent.exists():
"""不存在,执行创建这个文件"""
path.parent.mkdir()
# 写入内容 "你近来可好!"
path.write_text("你近来可好!")
# 读内容
content = path.read_text()
"""不停的追加内容"""
content += "\n今天天气很晴朗,处处好风光!\n"
content += "今天天气很美,你心情美吗?\n"
content += "亲爱的:\n"
content += " 我们还能相见吗?\n"
path.write_text(content)
print(content)
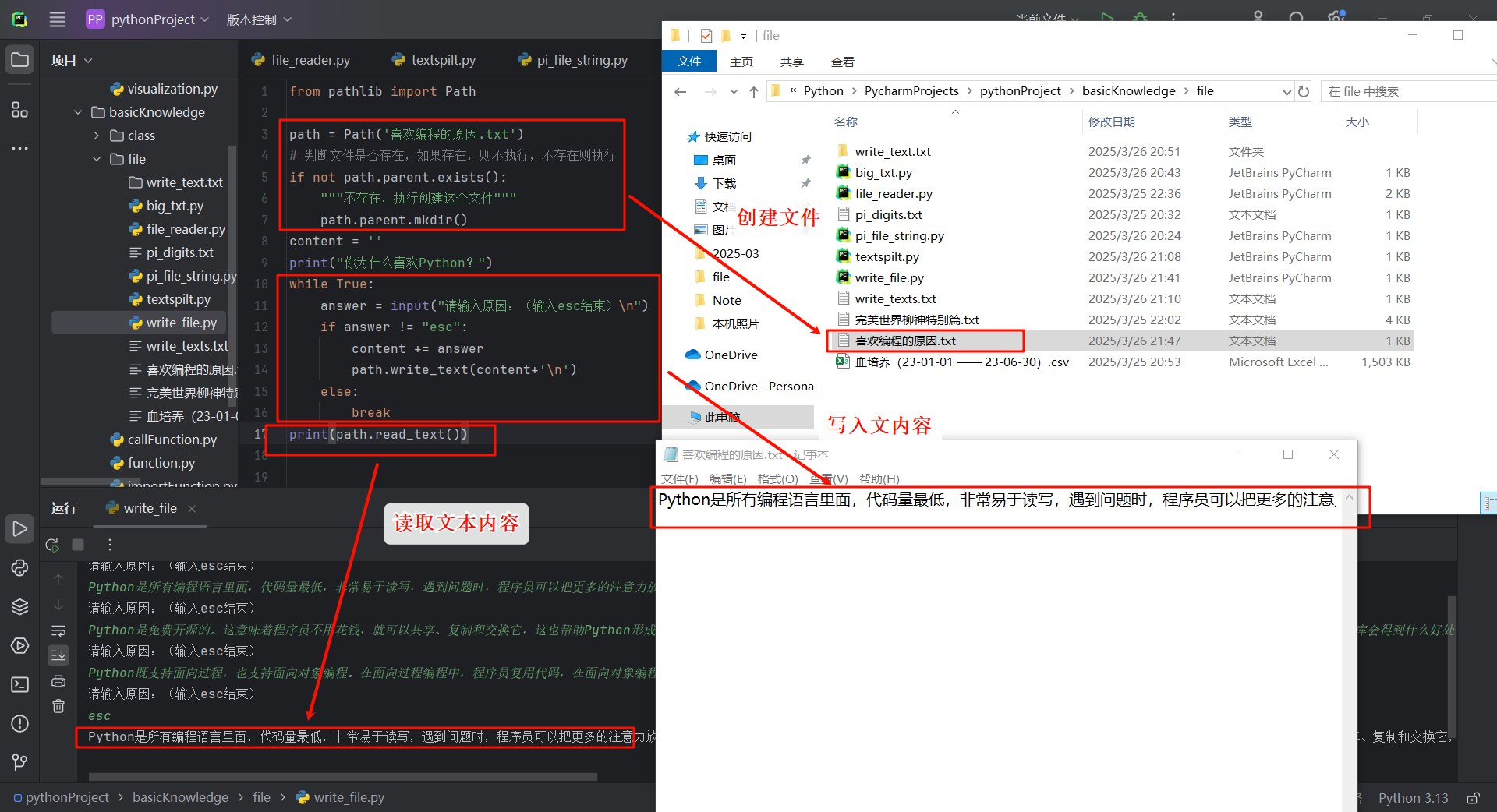
小试牛刀:
编写一个while循环,询问用户为何喜欢编程。每当用户输入一个原因后,都将其添加到一个存储所有原因的文件中。
from pathlib import Path
path = Path('喜欢编程的原因.txt')
# 判断文件是否存在,如果存在,则不执行,不存在则执行
if not path.parent.exists():
"""不存在,执行创建这个文件"""
path.parent.mkdir()
content = ''
print("你为什么喜欢Python?")
while True:
answer = input("请输入原因:(输入esc结束)\n")
if answer != "esc":
content += answer
# 写入文件中
path.write_text(content+'\n')
else:
break
# 读取文件中的内容
print(path.read_text())
运行结果如下:
10.3 异常
Python使用称为**异常(exception)**的特殊对象来管理程序执行期间发生的错误。每当发生让Python不知所措的错误时,它都会创建一个异常对象。如果你编写了处理该异常的代码,程序将继续运行;如果你未对异常进行处理,程序将停止,并显示一个traceback,其中包含有关异常的报告。
异常时使用try - except代码块进行处理的。try - except代码块让Python执行指定的操作,同时告诉Python在发生异常时应该怎么办。在使用try - except代码块时,即便出现异常,程序也将继续运行:显示你编写的友好错误信息,而不是令用户迷惑的traceback。
10.3.1 处理ZeroDivisionError异常
下面看一种导致Python引发异常的简单错误。如:将一个数除以零(0),Python会报怎样的错误呢?
print(5/0)
报错截图:
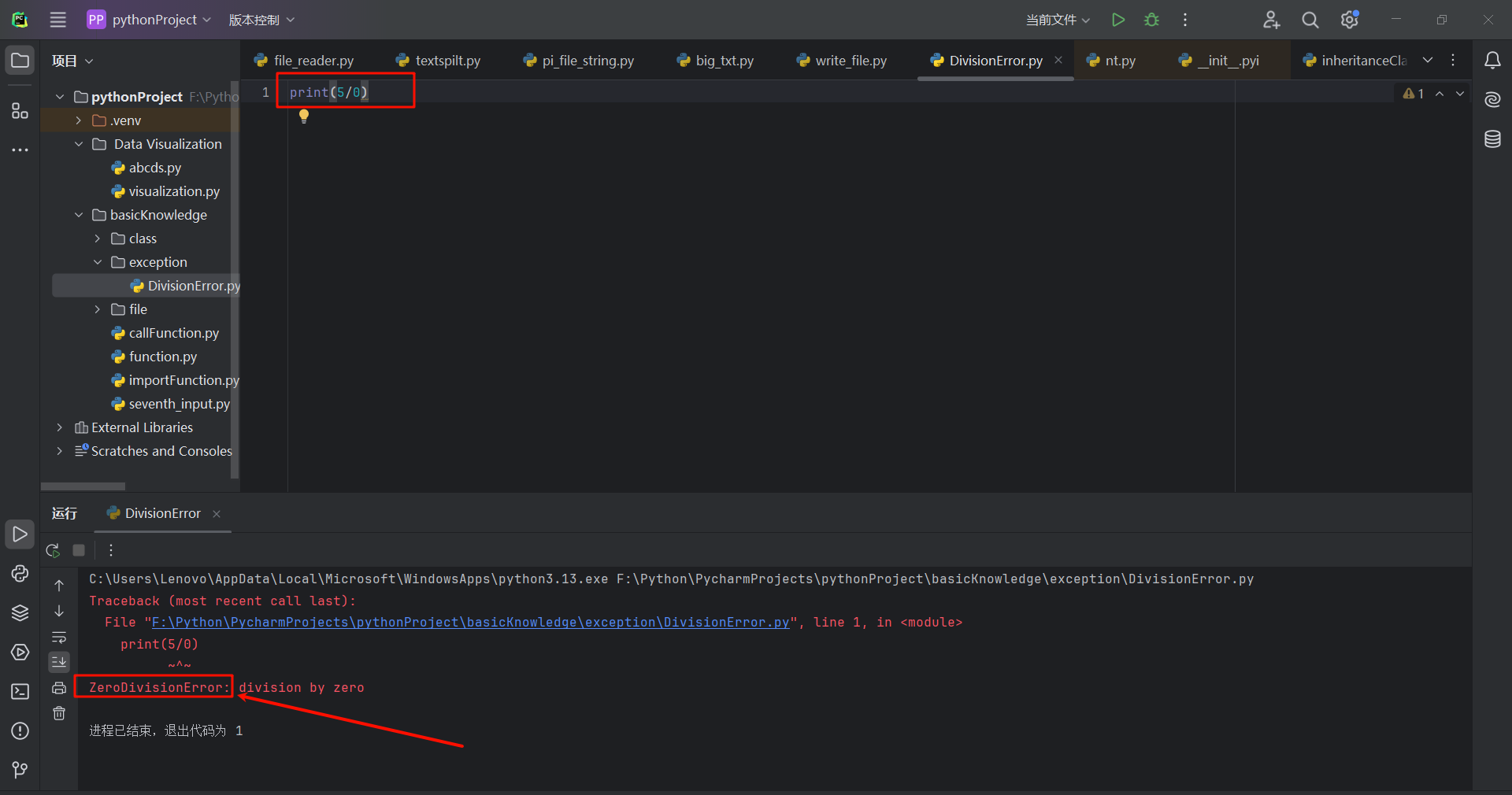
在上述·traceback·中,指出的错误ZeroDivisionError是一个异常对象。Python无法按你的要求做时,就会创建这种对象。在这种情况下,Python将停止运行程序,并指出引发了哪种异常,而我们可根据这些信息对程序进行修改。下面我们将告诉Python,发生这种错误时怎么办;这样,如果再次发生这样的错误,我们就有备无患了。
10.3.2 使用try - except代码块
当你认为可能发生错误时,可编写一个try - except代码块来处理可能引发的异常。你让Python尝试运行特定的代码,并告诉它如果这些代码引发了指定的异常,该怎么办。
try:
print(5/0)
except ZeroDivisionError:
print("你是怎么想的,竟然用零(0)做除数!!!!")
我们将导致错误的代码行print(5/0)放在了一个try代码块中。如果try代码块中的代码运行起来没有问题,Python将跳过except代码块;如果try代码块中的代码导致了错误,Python将查找这样的except代码块,并运行其中的代码,即其中指定的错误与引发的错误相同。
在这个示例中,try代码块中的代码引发了ZeroDivisionError异常,因此Python指出了该如何解决问题的except代码块,并运行其中的代码。这样,用户看到的是一条友好的错误消息,而不是traceback:
运行结果:
你是怎么想的,竟然用零(0)做除数!!!!
如果try-except代码块后面还有其他代码,程序将接着运行,因为已经告诉了Python如何处理这种错误。
10.3.3 使用异常避免崩溃
如果在错误发生时,程序还有工作没有完成,妥善地处理错误就显得非常的重要。这种情况经常出现在要求用户提供输入的程序中。如果程序能够妥善地处理无效输入,就能提示用户提供有效输入。而不至于崩溃。
下面来创建一个只执行除法运算的简单计算器:
print("请输入两个数,一个被除数,另一个除数:(按esc结束)")
while True:
first_number = input("请输入一个被除数:")
second_number = input("请输入第二个数:")
if second_number != 'esc':
"""强制转换为整形运行"""
answer = int(first_number) / int(second_number)
print(int(answer))
else:
break
上面是一个简单的计算器,但是对于一些特殊情况没有做特殊处理,也就是本届的重点异常,没有对异常进行处理。当用户第二个数输入0时就会报traceback错误了。
完善的写法如下:
print("请输入两个数,一个被除数,另一个除数:(按esc结束)")
while True:
first_number = input("请输入一个被除数:")
second_number = input("请输入第二个数:")
if second_number != 'esc':
"""强制转换为整形运行"""
try:
answer = int(first_number) / int(second_number)
print(answer)
except ZeroDivisionError:
print('第二个数是0,请重新输入:')
else:
break
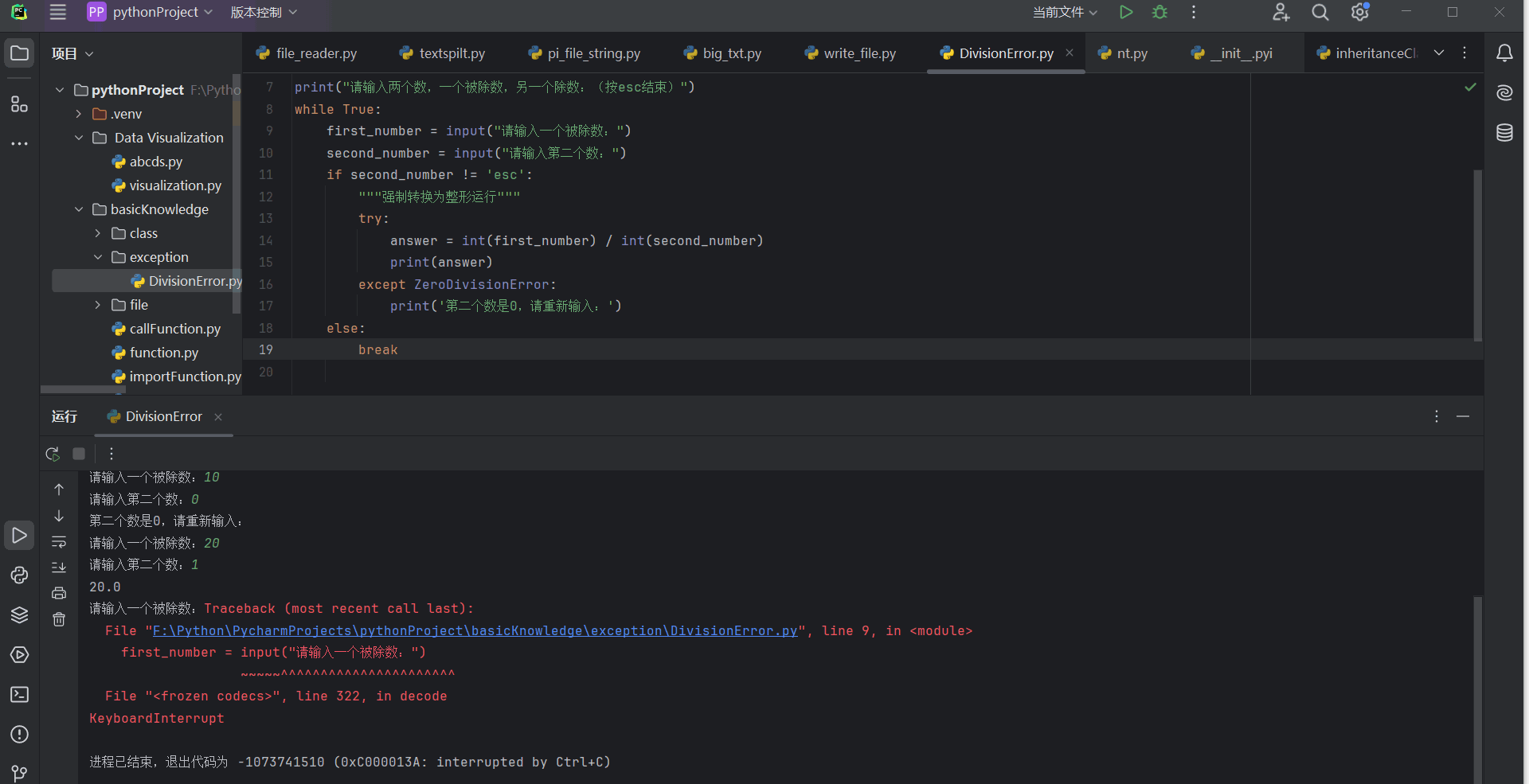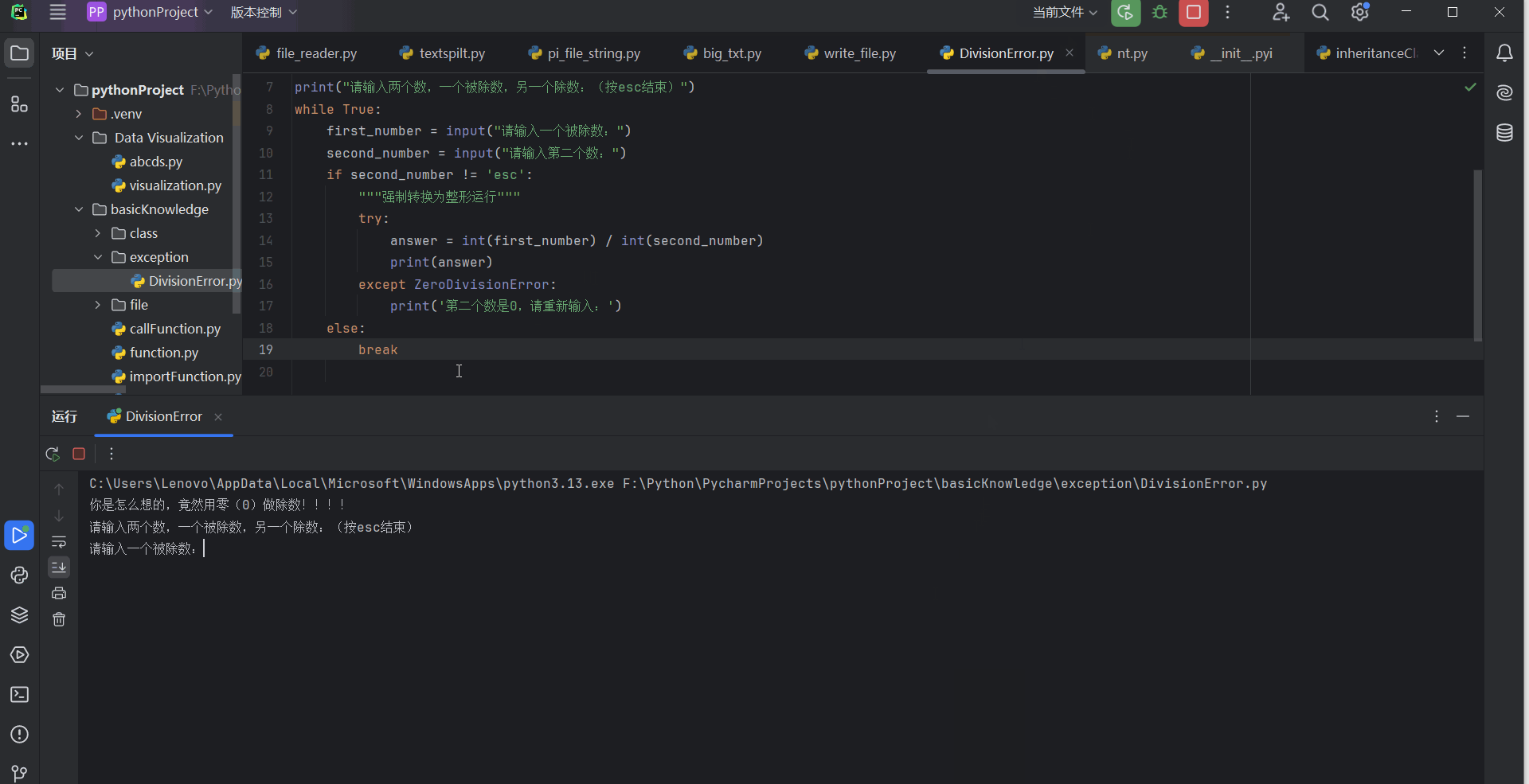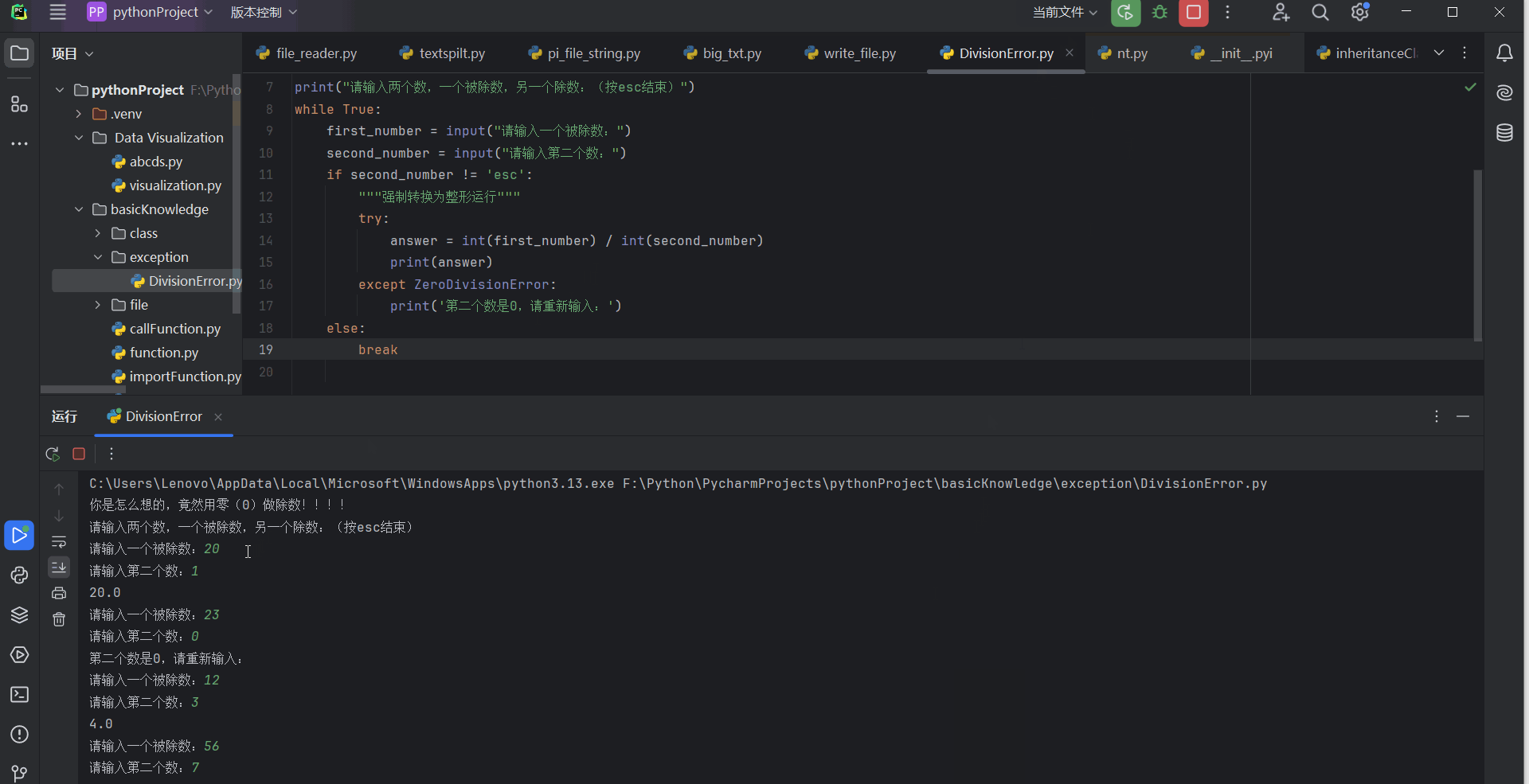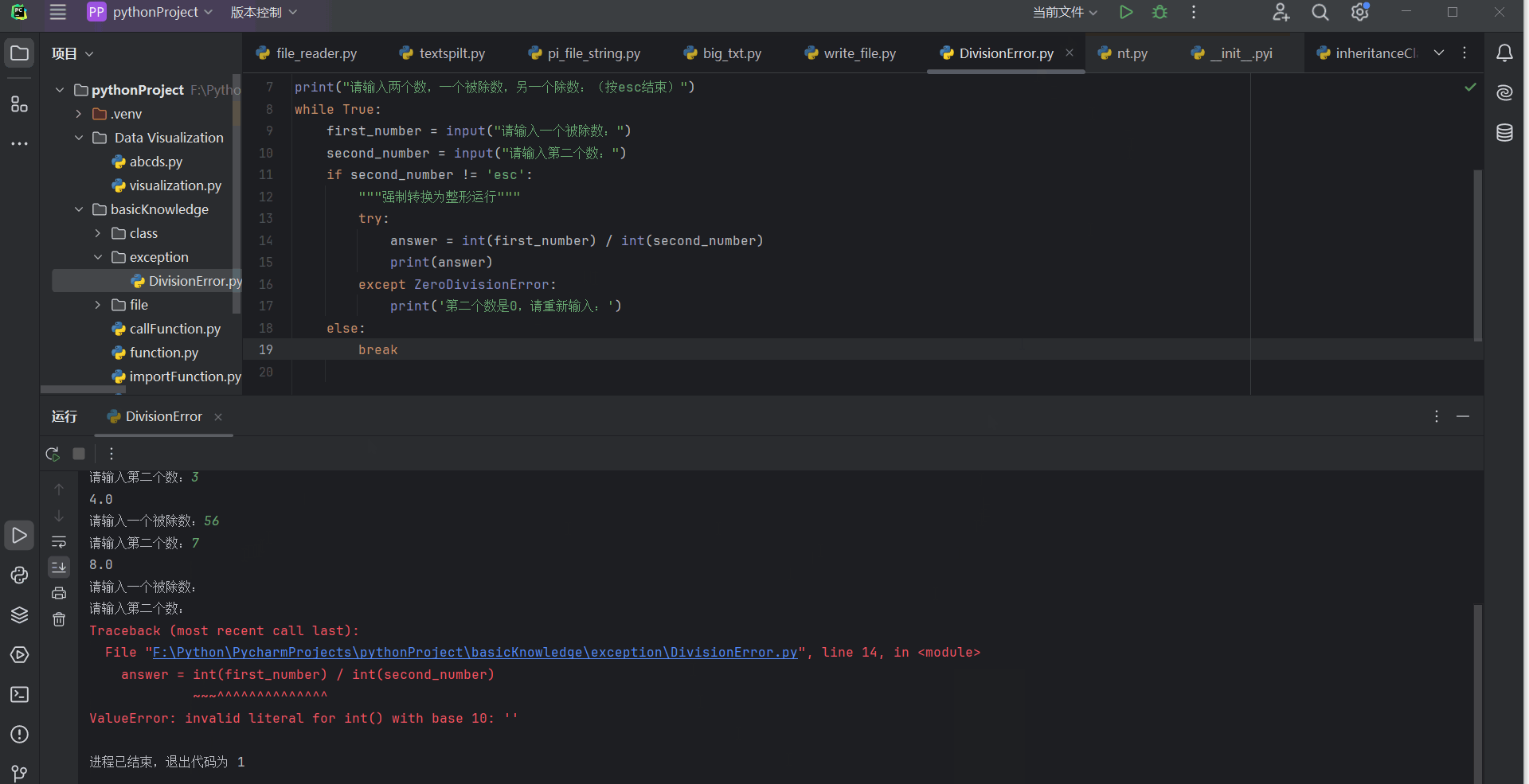
10.3.4 处理FileNotFoundError异常
在使用文件时,一种常见的问题是找不到文件:要查找的文件可能在其他地方,文件名可能不正确,或者使用这个文件根本就不存在。对应上面的所有情况都可以用try - except代码块来实现。
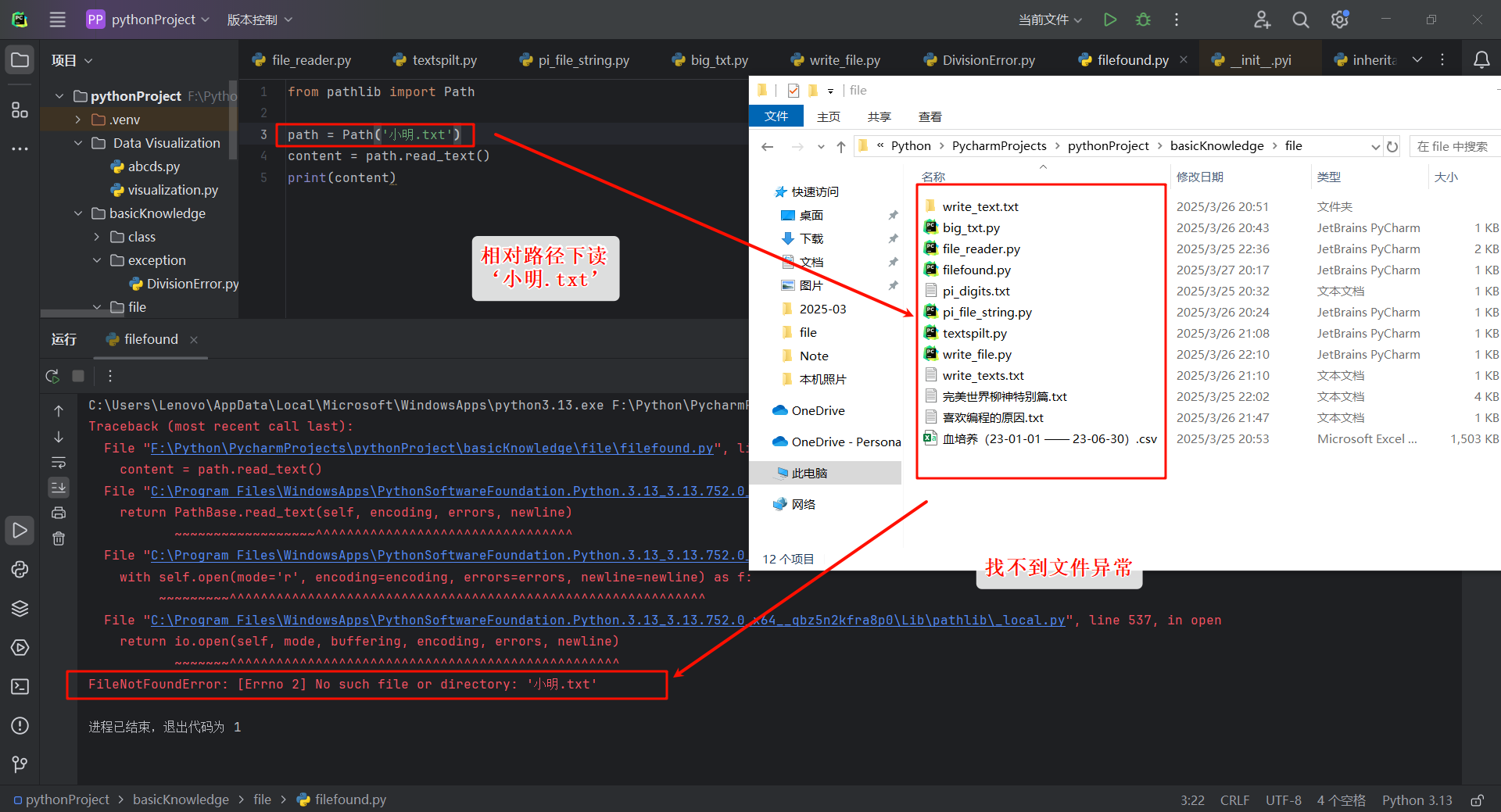
尝试来读一个不存的的文件,看会发生怎样的报错:
from pathlib import Path
path = Path('小明.txt')
content = path.read_text()
print(content)
Traceback (most recent call last):
File "F:\Python\PycharmProjects\pythonProject\basicKnowledge\file\filefound.py", line 4, in <module>
content = path.read_text()
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.13_3.13.752.0_x64__qbz5n2kfra8p0\Lib\pathlib\_local.py", line 546, in read_text
return PathBase.read_text(self, encoding, errors, newline)
~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.13_3.13.752.0_x64__qbz5n2kfra8p0\Lib\pathlib\_abc.py", line 632, in read_text
with self.open(mode='r', encoding=encoding, errors=errors, newline=newline) as f:
~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.13_3.13.752.0_x64__qbz5n2kfra8p0\Lib\pathlib\_local.py", line 537, in open
return io.open(self, mode, buffering, encoding, errors, newline)
~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
FileNotFoundError: [Errno 2] No such file or directory: '小明.txt'
针对上面的报错,如何看懂复杂的traceback呢?如上面的报错信息在报错末尾可以明显的看到FileNotFoundError: [Errno 2] No such file or directory: '小明.txt',从字面意思可以看出,是因为在相对路径下找不到文件小明.txt而引发的FileNotFoundError,即文件找不到异常。
再往上看其他的报错信息,比如File "F:\Python\PycharmProjects\pythonProject\basicKnowledge\file\filefound.py", line 4, in content = path.read_text() <module>报错定位到第四行。而接下来就是列出导致错误的代码行,traceback的其余部分列出了一些代码,它们来自打开以及读取文件涉及的库。通常也不需要详细的阅读和理解traceback中的这些内容。
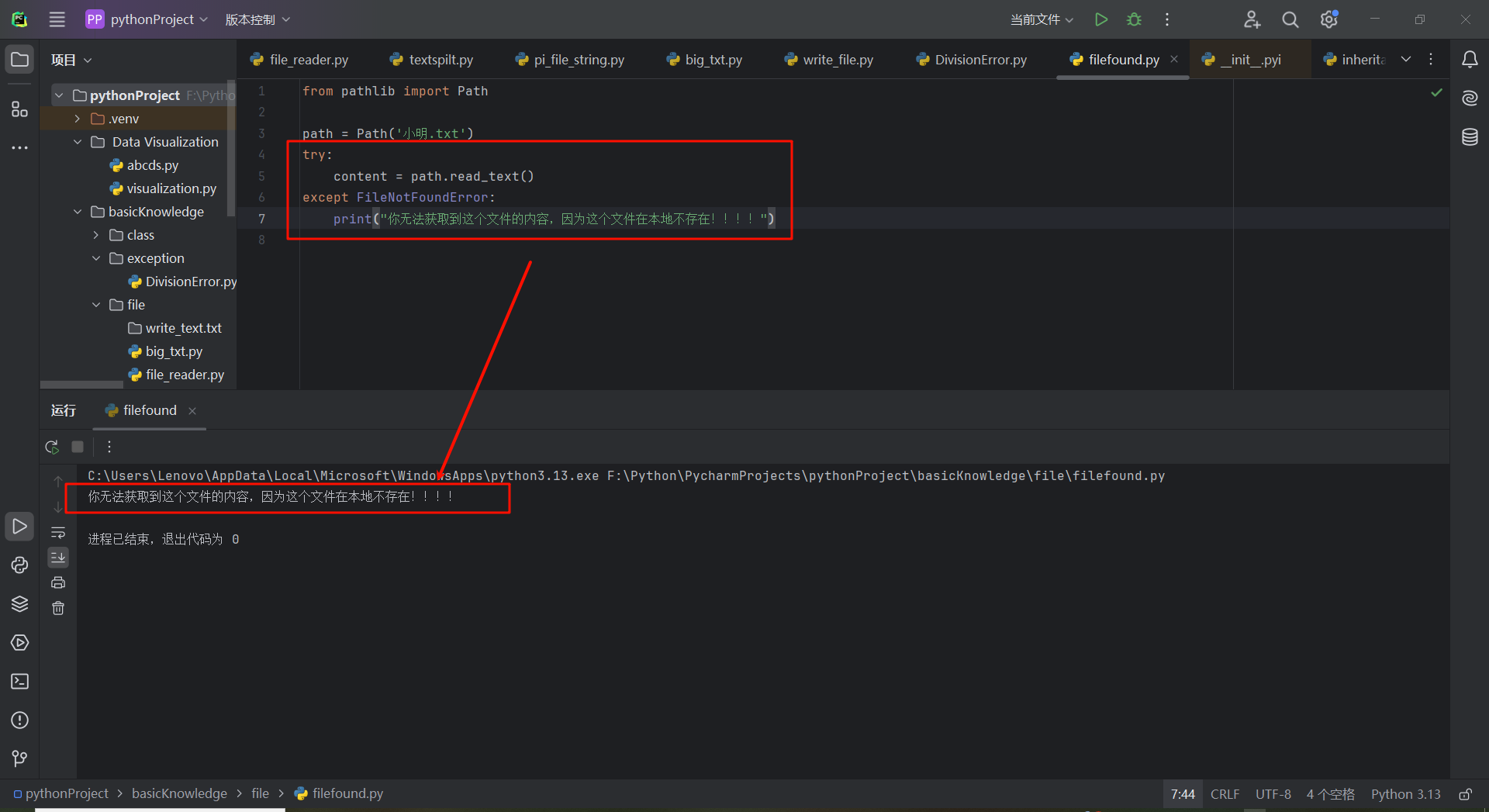
为了处理这个异常,应将traceback指出的存在问题的代码行放到try代码块中,而这里存在问题的是content = path.read_text()这行代码,那么应该这样写;
from pathlib import Path
path = Path('小明.txt')
try:
content = path.read_text()
except FileNotFoundError:
print("你无法获取到这个文件的内容,因为这个文件在本地不存在!!!!")
运行结果;
10.3.5 分析文本
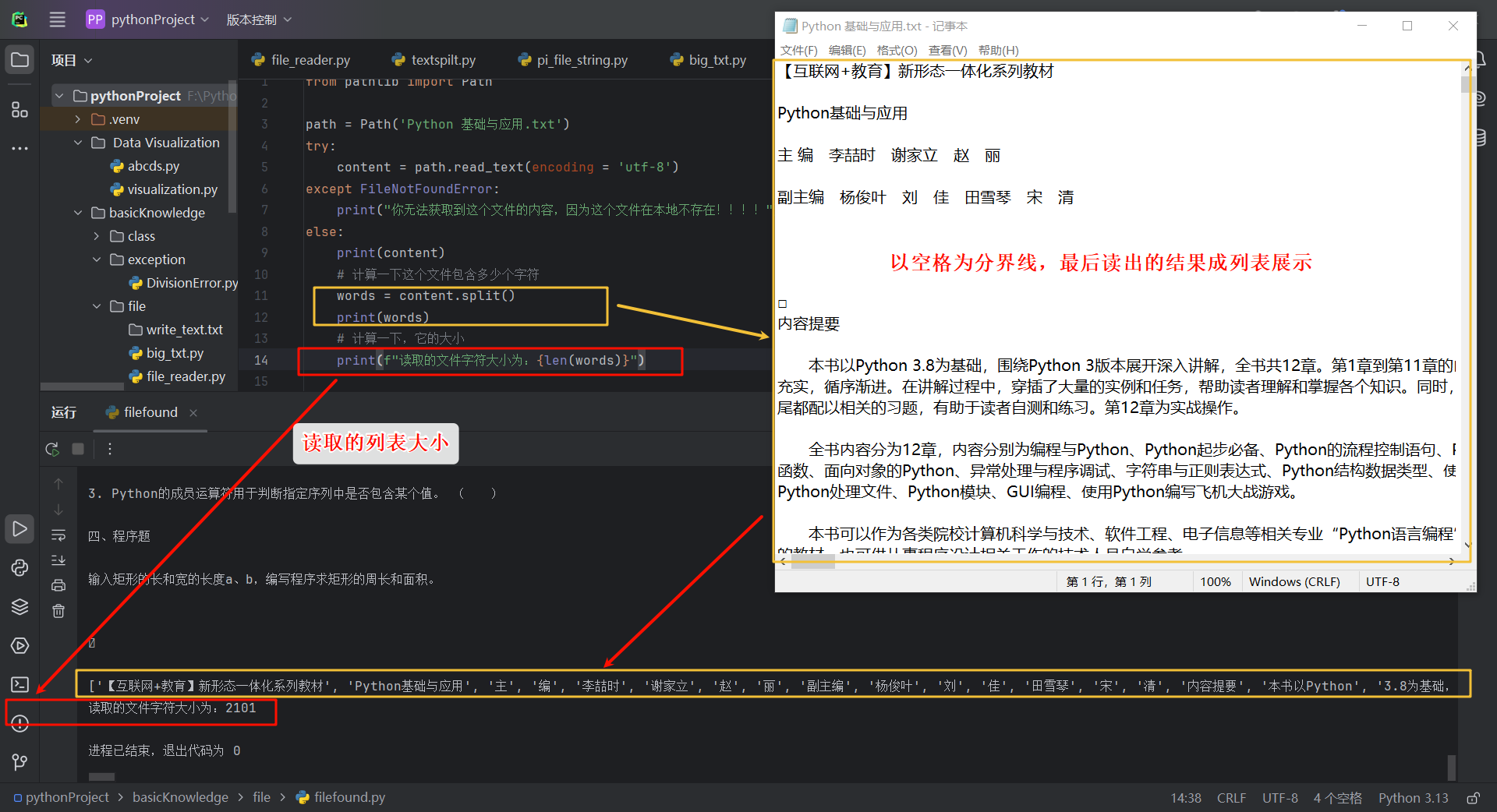
分析包含正本书的文本文件,如下图,我在本地存储了一个文本文件Python 基础与应用.txt,那么下面我就来读取这个文本文件:
如果不加以怎样的方式进行读取,那么就会报错,报错如下图:
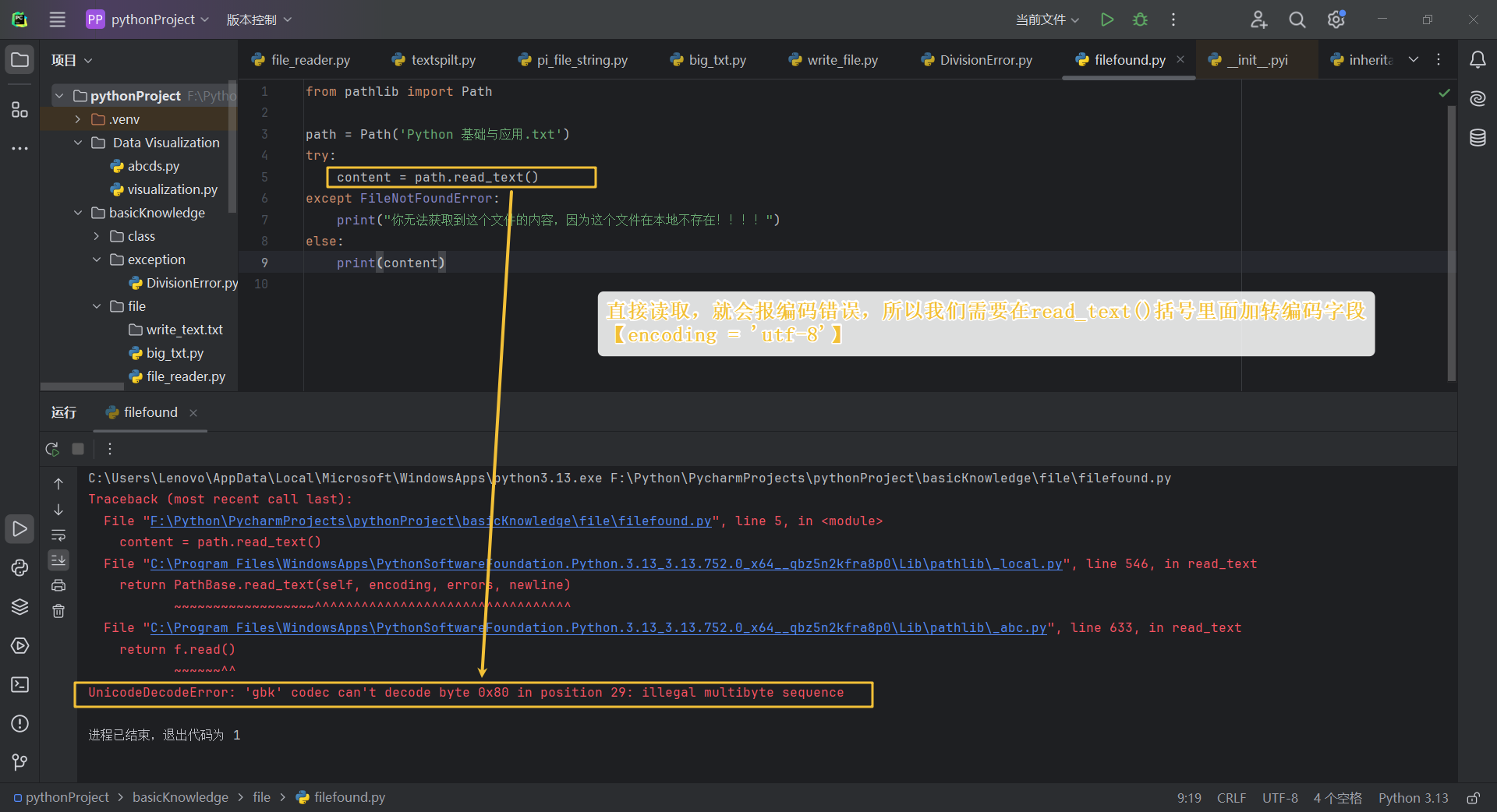
from pathlib import Path
path = Path('Python 基础与应用.txt')
try:
content = path.read_text(encoding = 'utf-8')
except FileNotFoundError:
print("你无法获取到这个文件的内容,因为这个文件在本地不存在!!!!")
else:
print(content)
运行结果:
我们使用split()方法,默认以空格为分隔符将字符串分拆成多个部分:
from pathlib import Path
path = Path('Python 基础与应用.txt')
try:
content = path.read_text(encoding = 'utf-8')
except FileNotFoundError:
print("你无法获取到这个文件的内容,因为这个文件在本地不存在!!!!")
else:
print(content)
# 计算一下这个文件包含多少个字符
words = content.split()
print(words)
# 计算一下,它的大小
print(f"读取的文件字符大小为:{len(words)}")
10.3.6 使用多个文件
写一个函数来存储上一节的代码,然后来读取多本书:
重新写一个文件,命名为filefound.py,在这个文件中写一个函数,代码如下:
from pathlib import Path
path = Path('Python 基础与应用.txt')
def read_texts(path):
"""读取多个文件,所写的函数"""
try:
content = path.read_text(encoding = 'utf-8')
except FileNotFoundError:
print(f"你无法获取到这个文件的内容,因为这个文件《{path}》在本地不存在!!!!")
else:
print(content)
# 计算一下这个文件包含多少个字符
words = content.split()
print(words)
# 计算一下,它的大小
print(f"读取的文件《{path}》,它的字符大小为:{len(words)}")
再新增一个文件,Python文件,命名为morepathon.py,以此来调用上面的Python文件filefound.py,程序如下:
# 获取读完文件的库
from pathlib import Path
# 导入模块中的方法 read_texts
from filefound import read_texts
# 定义一个列表,来存储需要读取的文本文件的文件名
filenames = ['完美世界柳神特别篇.txt','Scikit-learn Machine Learning in Python.txt','Python编程.txt','Python 基础与应用.txt']
# 使用for循环进行遍历
for filename in filenames:
file = Path(filename)
read_texts(file)
print("结束循环,已经读完全部文本文件!!!")
在这个实例中,使用try - except代码块,有两个显著的优点:第一个是避免用户看到traceback,另外一个就是让程序可以继续分析能够找到的其他文件。
由于有多个文件,那么我们可以调试这个程序,如果发现PyCharm点击Debug时报错,报错如下:
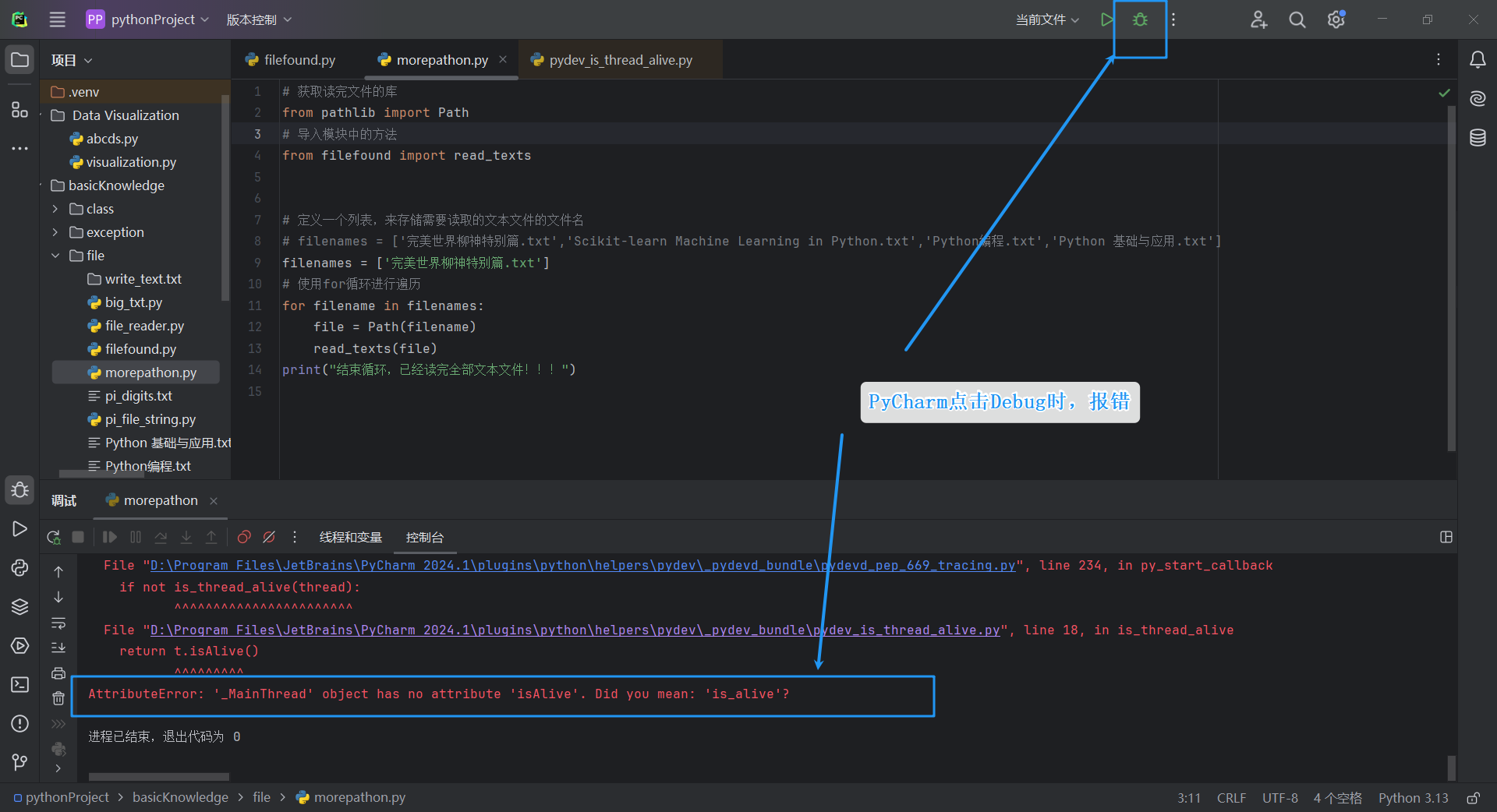
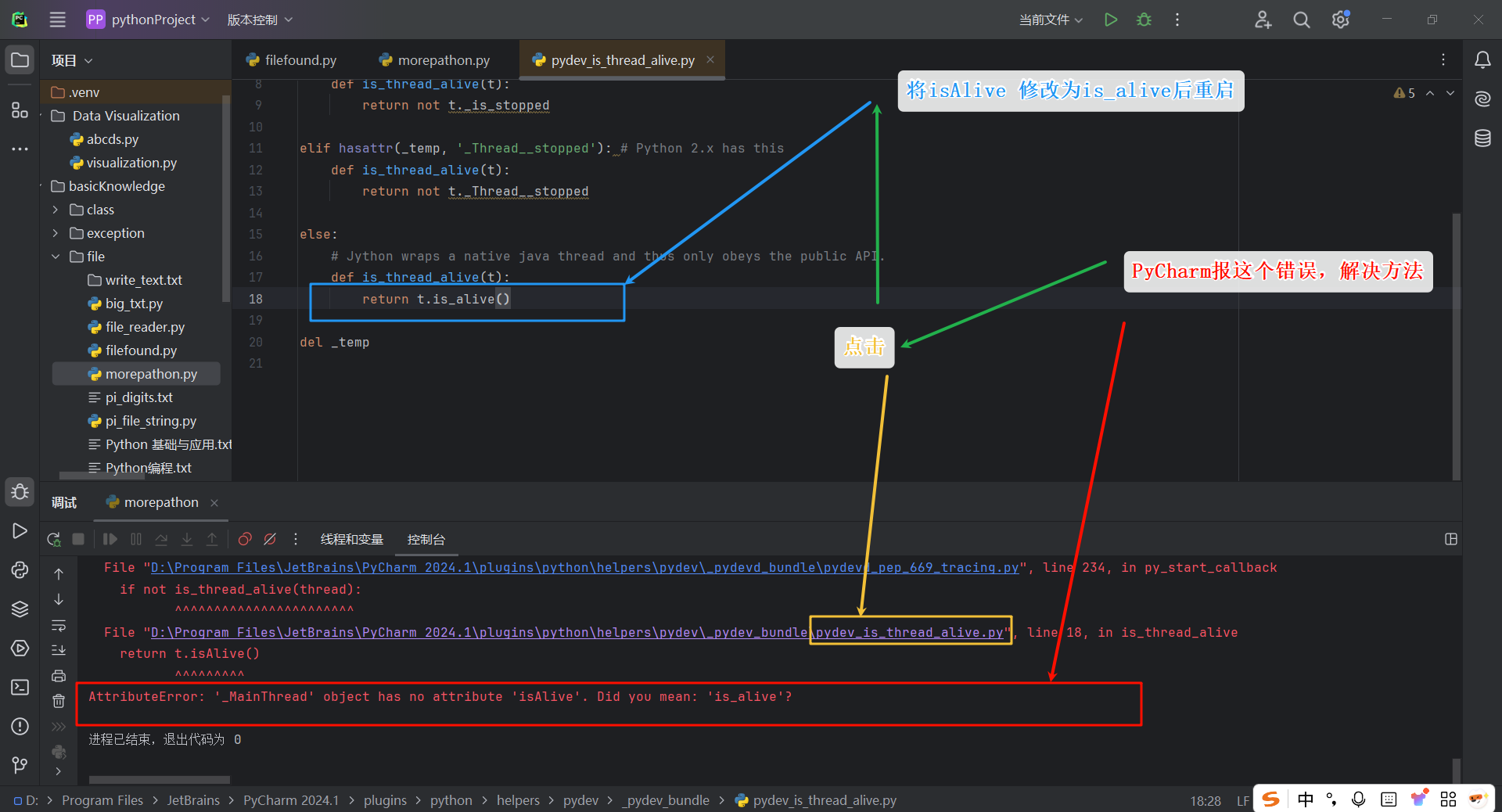
解决方法:
10.3.7 静默失败
在上面的实例中,我们告诉用户有一个文件找不到。但并非每次捕获异常都需要告诉用户,我们有一些时候希望发生异常的时候,让程序什么都不要发生,继续运行,直到运行出想要的结果,因为我们看到程序报一个错误,心里会觉得不舒服,为了避免这种不舒服的情况发生。我们可以使用pass,它可以让Python什么都不用做,继续往下运行。
我们在上一节中,在except FileNotFoundError:下面,增加一个pass,意思如果发现文件不存在,则让Python静默执行,不做任何提示以及报错。
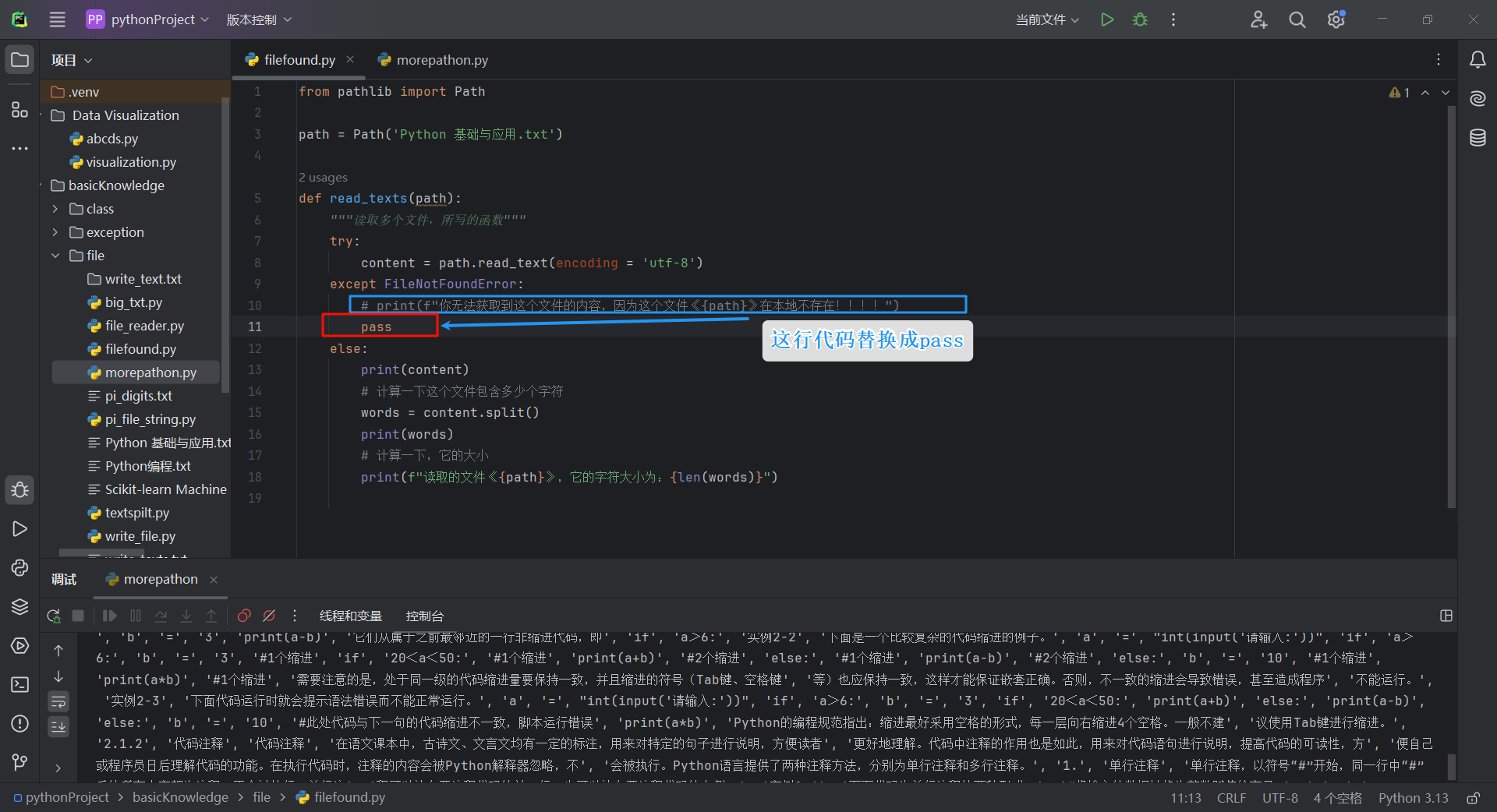
pass语句在这里不仅让Python静默执行,还充当了占位符,提醒Python在某个地方什么都不用做,或许将来程序员,会在这里添加其他代码。
10.4 存储数据
很多程序要求用户输入某种信息,比如让用户存储游戏首选项或者提供可视化的数据。不管专注点是什么,程序都会把用户提供的信息存储在列表和字典等数据结构中,当用户关闭程序时,几乎总是要保存他们提供的信息。一种简单的方式就是使用模块json来存储数据。
模块json让你能够将简单的Python数据结构转换为JSON格式的字符串,并在程序再次运行时从文件中加载数据。你还可以使用json在Python程序之间共享数据。更重要的是,JSON数据格式并不是Python专用的,这让你能够将以JSON格式存储的数据与使用其他编程语言的人共享。这是一种轻量级数据格式,不仅有用,而且也容易学习。
注意:JSON(JavaScript Object Notation)格式最初是为JavaScript开发的,但随后成了一种通用的格式,被包括Python在内的众多语言采用。
10.4.1 使用json.dump()和json.loads()
先编写一个存储一组数的程序,(这里我使用随机生成,利用循环追加到空列表中),之后编写一个将这些数读取到内存的代码。第一个程序将使用json.dump()来存储这组数,然后使用json.loads()来读取它们到内存中。
json.dump()函数将接受一个实参,即要转换成JSON格式的数据。这个函数返回一个字符串,这样你就可将其写入数据文件中,如下:
import json
from pathlib import Path
# 随机生成1到101之内的数字,每隔三个数
# numbers = range(1,101,3)
numbers = []
# 获取为JSON格式
path = Path('numbers.json')
# 检测本地是否存在numbers.json文件,如果不存在,则执行下面这句
if not path.parent.exists():
path.parent.mkdir()
# 使用循环来将生成的随机数追加到空列表中
for i in range(1,101,3):
# 将生成的随机数写入numbers中
numbers.append(i)
print(f"生成的随机数为:{numbers}。")
# 使用json.dumps()来存储数据
contents = json.dumps(numbers)
# 将使用json.dumps()存储的数据写入【numbers.json】
path.write_text(contents)
# 读取【numbers.json】中的数据
content = path.read_text()
# 使用number来存储读取到的数据
number = json.loads(content)
# 输出
print(f"从文件【numbers.json】读取到的内容为:{number}。")
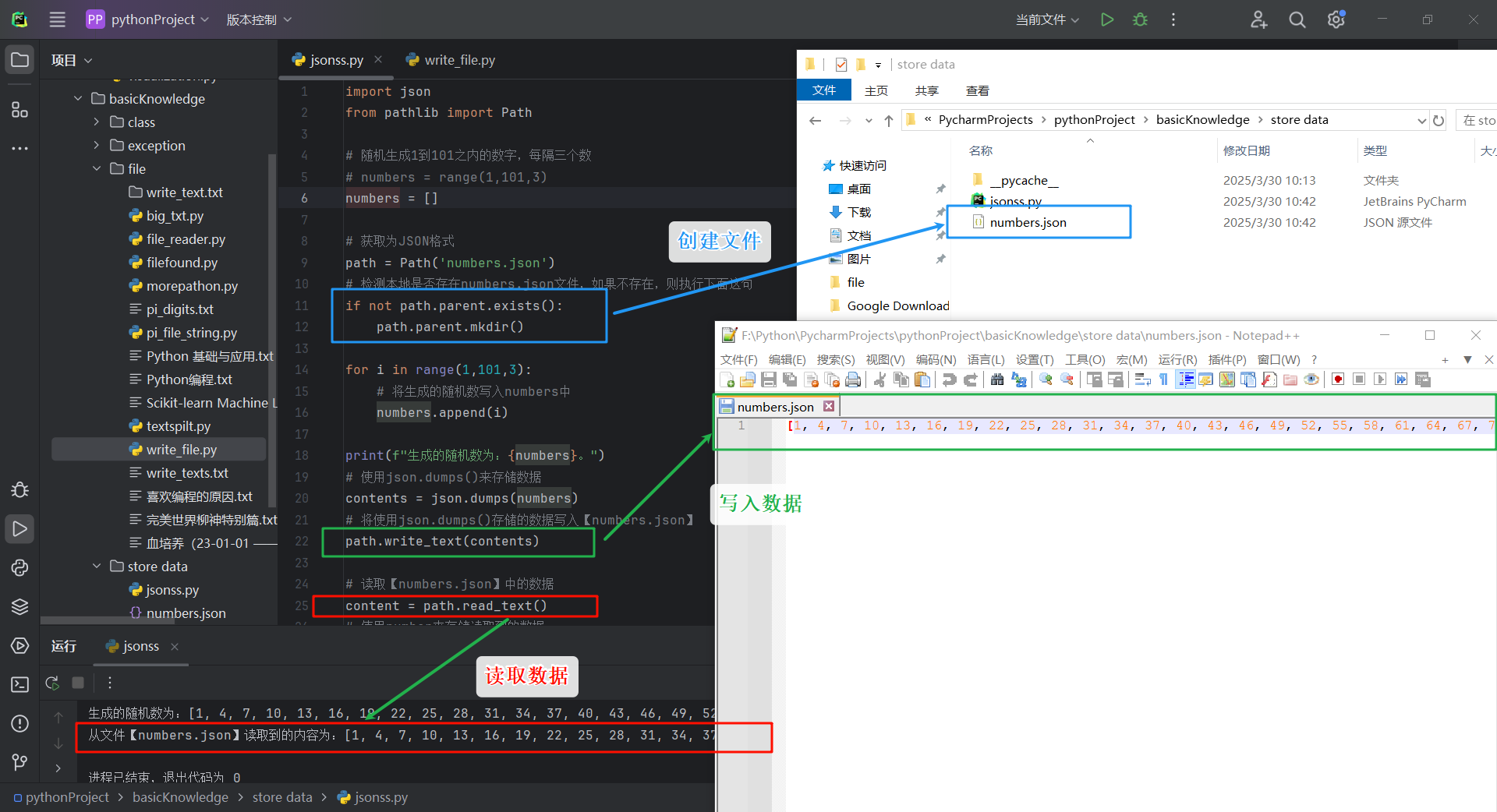
运行结果:
生成的随机数为:[1, 4, 7, 10, 13, 16, 19, 22, 25, 28, 31, 34, 37, 40, 43, 46, 49, 52, 55, 58, 61, 64, 67, 70, 73, 76, 79, 82, 85, 88, 91, 94, 97, 100]。
从文件【numbers.json】读取到的内容为:[1, 4, 7, 10, 13, 16, 19, 22, 25, 28, 31, 34, 37, 40, 43, 46, 49, 52, 55, 58, 61, 64, 67, 70, 73, 76, 79, 82, 85, 88, 91, 94, 97, 100]。
首先,我们需要导入两个包,一个Path和json,一个用来读取和写入数据,另一个用来存储数据以及将数据读取到内存中。
10.4.2 保存和读取用户生成的数据
使用json保存用户生成的数据,就变得非常的重要,因为如果不以某种方式进行存储用户的数据,那么整个程序就变得失去了意义,如下:
from pathlib import Path
import json
# 定义一个空列表
usernames = []
# 获取文件
path = Path('usernames.json')
# 验证本地是否存在json文件【usernames.json】
if not path.parent.exists():
# 如果不存在 就创建
path.parent.mkdir()
# 使用一个循环来获取用户写入的信息
while True:
username = input("请输入你的名字:(输入esc退出循序)!")
if username != 'esc':
usernames.append(username)
else:
break
# 使用json.dumps()存储数据
contents = json.dumps(usernames)
# 将存储的数据写入文件【usernames.json】中
path.write_text(contents)
# 读取这个数据
print(f"用户输入的名字有:{usernames}。")
运行结果:
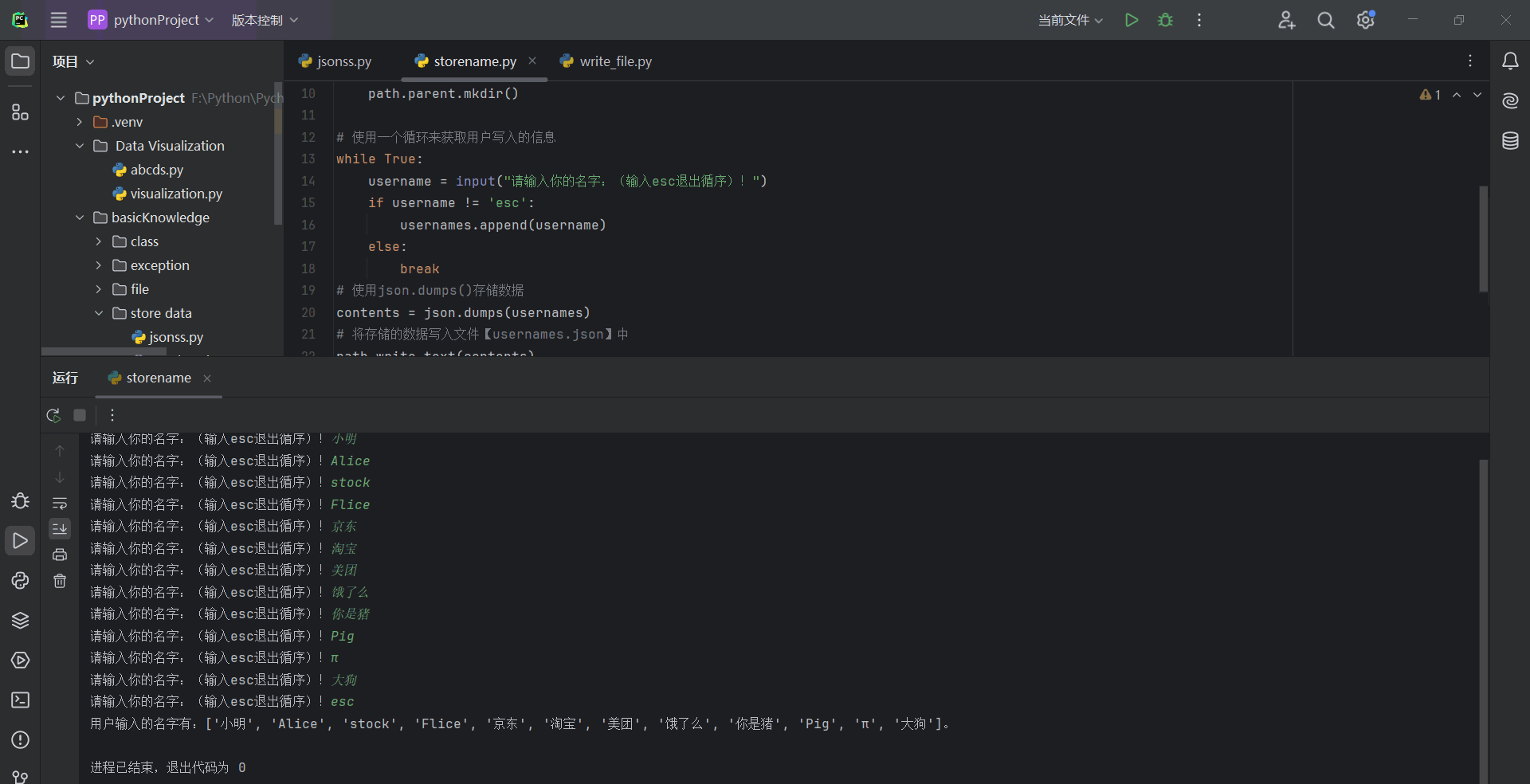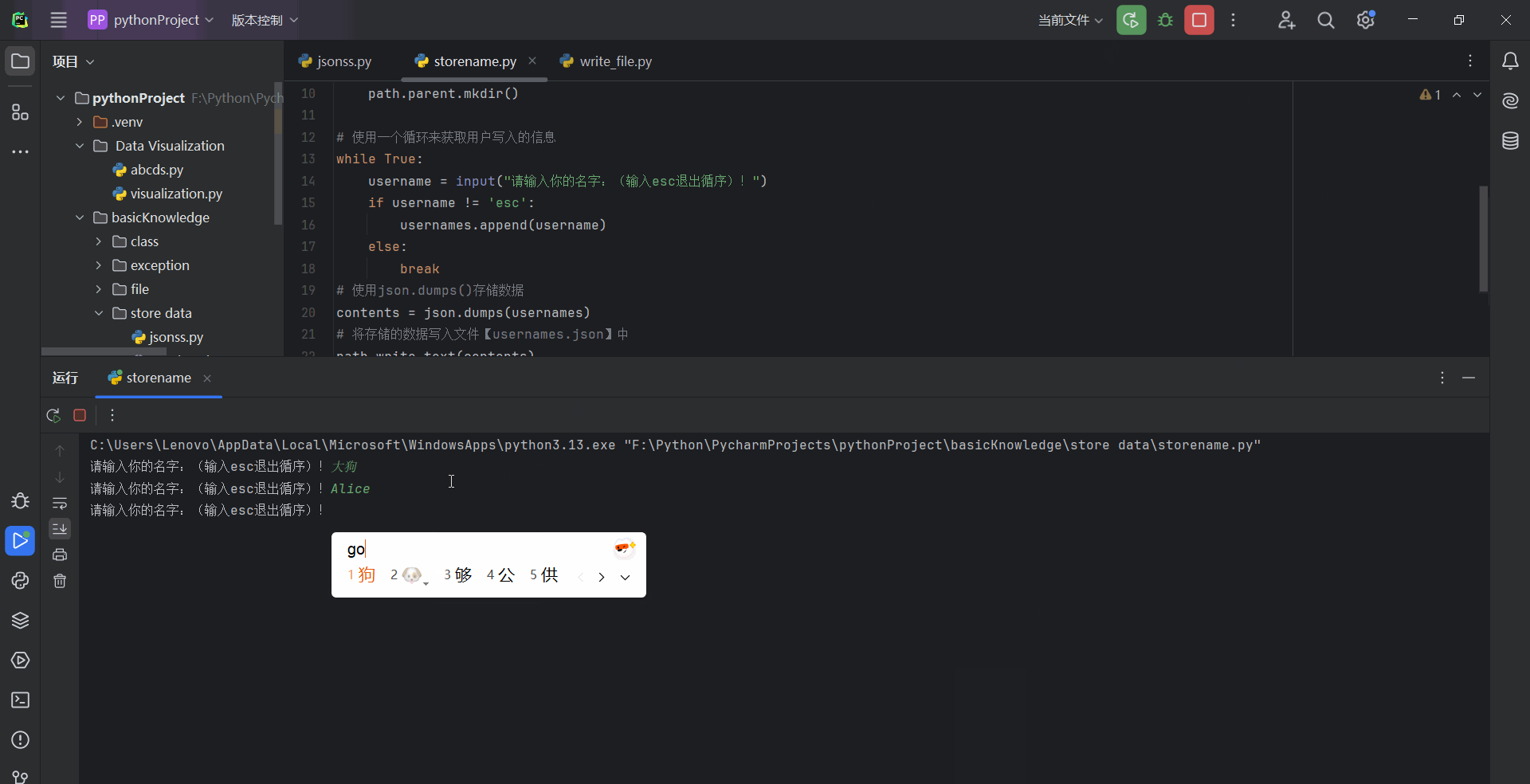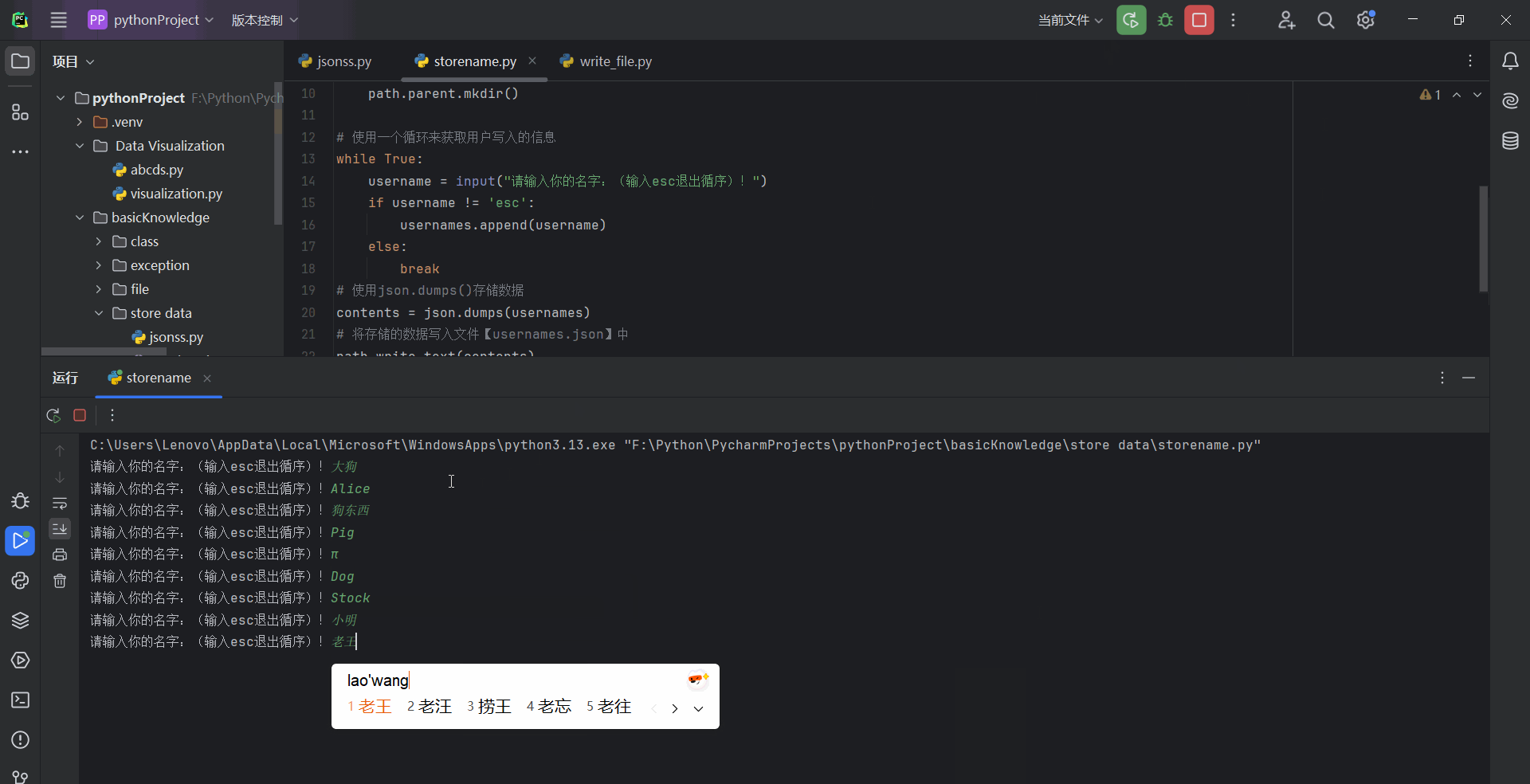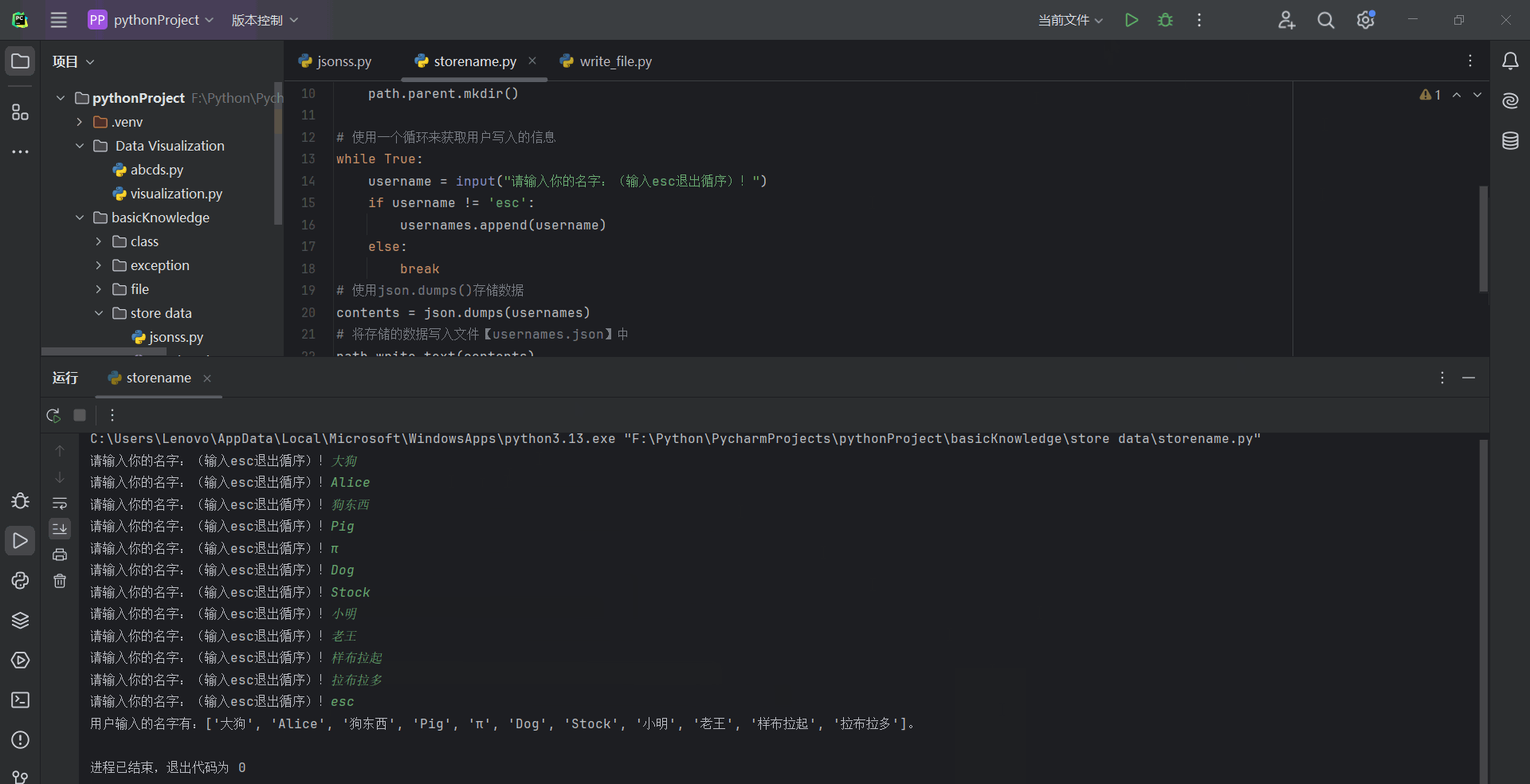
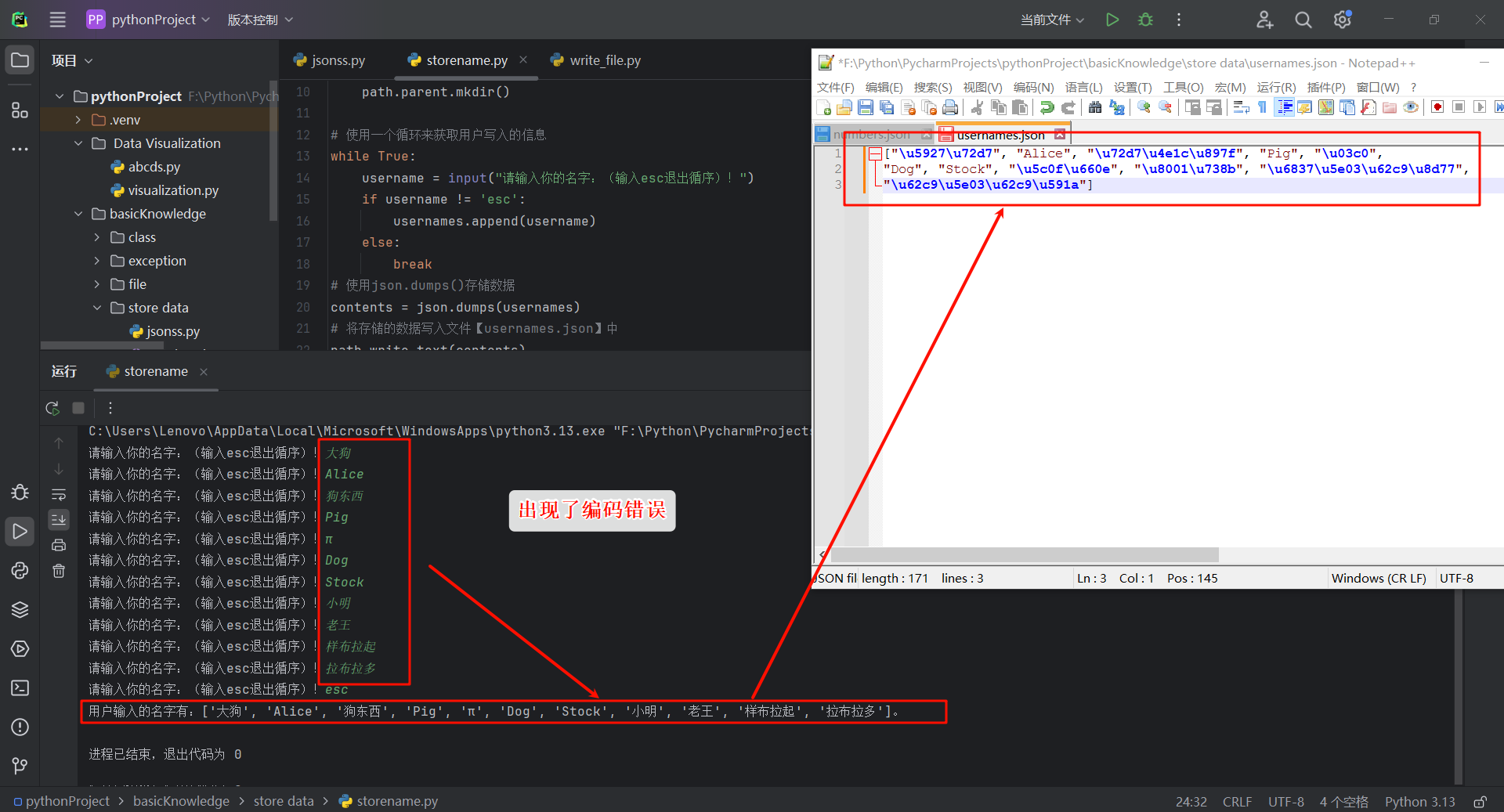
打开文件查看,汉字出现了编码错误:
判定文件是否存在本地,使用Path中的exists()方法。如果指定的文件或文件夹存在,则返回True,继续执行;否则,则返回False,中断执行,代码如下:
# 定义一个空的列表来存储用户输入的信息
users = []
# 另外一种好的方法 就是判定本地是否存在json文件
pats = Path('user_namess.json')
# 判定本地是否存在文件user_name.jsom
if not pats.parent.exists():
pats.parent.mkdir()
# 判定user_name.json是否存在内容,存在则继续执行,否则执行else部分
if pats.exists():
content = pats.read_text()
username = json.loads(content)
for a in username:
print(f"你好,{a}。")
else:
while True:
user_name = input("请输入你的名字:(输入esc退出)")
if user_name != 'esc':
# 将用户输入的用户名追加到列表users中
users.append(user_name)
# 将用户输入的用户名使用dumps()方法存储到json中
aa = json.dumps(user_name)
# 然后写入json文件中
pats.write_text(aa)
else:
break
# 将列表users中的列表内容以json存储到content1中
content1 = json.dumps(users)
# 读取content1中的内容
pats1 = json.loads(content1)
print(pats1)
# 遍历pats1中的内容
for b in pats1:
print(f"你好,{b}。")
10.4.3 重构
在实际编写代码的过程中,我们会遇到这样的情况,即:虽然代码能够正确的运行,但还可以将其划分为一系列完成具体工作的函数来进行改进,而这样的过程就称为重构。重构能够让代码更加清晰、更易于理解、更容易拓展。
10.5 小结
在本节中,学习了文件的一些知识,包含如下:
- 如何读取整个文件,如何读取文件中的各行;
- 如何将任意数量的文本内容写入文件中;
- 学习了异常的处理方法,
try - except代码块; - 如何使用
for、while以及条件测试语句实现高质量的代码; - 学习了
JSON文件的两个读取方法dumps()以及loads()方法; - 什么叫做
相对路径以及绝对路径; path和open()的区别以及用法;splitlines()方法和with语句的区别以及用法;
以上的内容,是本人自学Python,写的笔记,如有错误,请留言哦!!!本人会在第一时间及时更正。


















 657
657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











