






20220210-MK非参数检验

(刘烁楠. 变化环境下月水量平衡模型参数时变特征研究[D]. 2019.)
通过UP主视频里的详细EXCEL过程,理解了MK具体的检验过程,以及各计算步骤;
B站视频学习(数理统计21-非参数检验初步_哔哩哔哩_bilibili)

MK突变检验(为什么UF与UB交点代表突变点?):
对于最后结果的显著性分析:
- 检验分单侧和双侧,双侧有两个拒绝域两个临界值,即如果出现了>或者<的任意情况,就可以拒绝原假设;而单侧,就是当假设问题带有方向性,一些问题我们希望越大越好,比如灯泡的寿命等,另一些问题我们希望越小越好,比如废品率,这时候我们就要用单侧。单侧检验显著性水平0.05对应的标准正态分布的分位数为1.645,而双侧检验的标准正态分布的0.025分位数是1.96(双侧检验的p值和单侧检验_参数检验_云山雾村的博客-CSDN博客)
20220211—MK趋势检验+Sen斜率分析:
参考以下博文(博文中详细的介绍了回归的相关方法,比如稳健回归):
MK趋势检验+Kendalls taub等级相关+稳健回归(Sens slope estimator等)_UCAS_Leon的博客-CSDN博客_森斜率 matlab实现MK计算Z值并且利用SEN回归方法计算斜率;源码(matlab实现m-k突变的,用matlab进行mk趋势分析与突变检验.pdf_weixin_39662721的博客-CSDN博客);自己在此基础上修改了一点点,有八十几个网格,所以多加了循环;
zz=[];
sss=[];
for i=1:length(a1)
y1=a1(i,:);
y=y1(:);
n=length(y);
s=0;
for j=1:n-1
s= s + sum(sign(y(j+1:n) - y(j)));
end
vars=n*(n-1)*(2*n+5)/18;
if s>0
z=(s-1)/sqrt(vars);
else
z=(s+1)/sqrt(vars);
end
zz=[zz;z];
ndash=n*(n -1)/2;
slope1= zeros( ndash, 1 );
m=0;
for k = 1:n-1
for l= k+1:n
m=m+1;
slope1(m) = ( y(l) - y(k) ) / (x(l) - x(k) ) ;
end
end
slope= median( slope1 );
sss=[sss;slope];
endMK中的Z值计算出后,有**%的置信水平,大于0表明上升趋势显著,小于0表明下降趋势显著;利用SEN回归方法得到斜率后,上述Z值的显著性和斜率的显著性是否有关系?
一般的,如果通过拟合函数计算出斜率,进行拟合优度分析,matlab里的自带的线性拟合工具可以进行拟合并且计算R^2:
Matlab计算决定性系数(拟合优度)R2_jerry003的博客-CSDN博客_拟合优度r2
机器学习之性能度量指标——决定系数R^2、PR曲线、ROC曲线、AUC值、以及准确率、查全率、召回率、f1_score_大黄蜂Fighting的博客-CSDN博客_决定系数r

对于用拟合函数求出的Y,拟合优度(决定系数)的具体代码:
a1=a(2,:);
a2=a1(:);
p = polyfit(x,a2,1);
f = polyval(p,x);
up=(a2-f).^2;
down=(a2-mean(a2)).^2;
r2=1-( sum(up)/sum(down) );和前述滑动平均法去除异常点影响后的数据结合,拟合后求R2:
e=[];
d=[];
r=[];
for i=1:length(a)
d1=smooth(a(i,:),3);
d=[d d1];
e1=polyfit(x,d1,1);
e=[e e1(1)];
f = polyval(e1,x);
up=(d1-f).^2;
down=(d1-mean(d1)).^2;
r2=1-( sum(up)/sum(down) );
r=[r r2];
slope=e(:);
r2_t=r(:);
end【变量之间有无关系——显著性检验:】
通过显著性检验检测科学实验中实验组与对照组之间是否有差异以及差异是否显著(参考以下博文:)1.什么是显著性检验? 2.为什么要做显著性检验? 3.怎么做显著性检验?_taoy86的博客-CSDN博客_显著性分析是为了说明什么问题
【Matlab进行方差检验:】
关于显著性检验,你想要的都在这儿了!!(基础篇)_weixin_33796205的博客-CSDN博客
20220212—MATLAB做箱型图
boxplot函数,借助官方网站查看帮助;
(boxplot(x) 创建 x 中数据的箱线图。如果 x 是向量,boxplot 绘制一个箱子。如果 x 是矩阵,boxplot 为 x 的每列绘制一个箱子。
在每个箱子上,中心标记表示中位数,箱子的底边和顶边分别表示第 25 个和 75 个百分位数。须线会延伸到不是离群值的最远端数据点,离群值会以 '+' 符号单独绘制。
boxplot(x,g) 使用 g 中包含的一个或多个分组变量创建箱线图。boxplot 为具有相同的一个或多个 g 值的各组 x 值创建一个单独的箱子
boxplot(ax,___) 使用坐标区图形对象 ax 指定的坐标区和任何上述语法创建箱线图。
boxplot(___,Name,Value) 使用由一个或多个 Name,Value 对组参数指定的附加选项创建箱线图。例如,您可以指定箱子样式或顺序)
绘图中(xlabel、ylabel、xticklabel等函数应用)
参考Matlab中指定坐标轴刻度值和标签_jk_101的博客-CSDN博客_matlab设置x轴刻度标签
MATLAB - 坐标显示范围、刻度、标签图例等设置_罗伯特祥的博客-CSDN博客_matlab 坐标轴刻度显示
a=xlsread('gai-maizey.xls','gai-maizey');
a1=a(:,4:28);
figure
axis normal
subplot(2,1,1)
boxplot(a1)
xlabel('年份')
ylabel('京津冀地区夏玉米单产(万吨/公顷)')
title('京津冀地区夏玉米单产箱型图')
set(gca,'xticklabel',{'1990','','','','','1995','','','','','2000','','','','','2005',...
'','','','','2010','','','','2014'})(boxplot函数中,尝试了很多次,不能自己定义X轴绘制范围,不晓得为啥子?)
参考以下博主方法 :MATLAB绘图笔记——画箱形图_wokaowokaowokao12345的专栏-CSDN博客_matlab箱型图,也只是以标签的形式改变刻度所对应的值)

获取统计信息MATLAB绘图笔记——画箱形图_wokaowokaowokao12345的专栏-CSDN博客_matlab箱型图
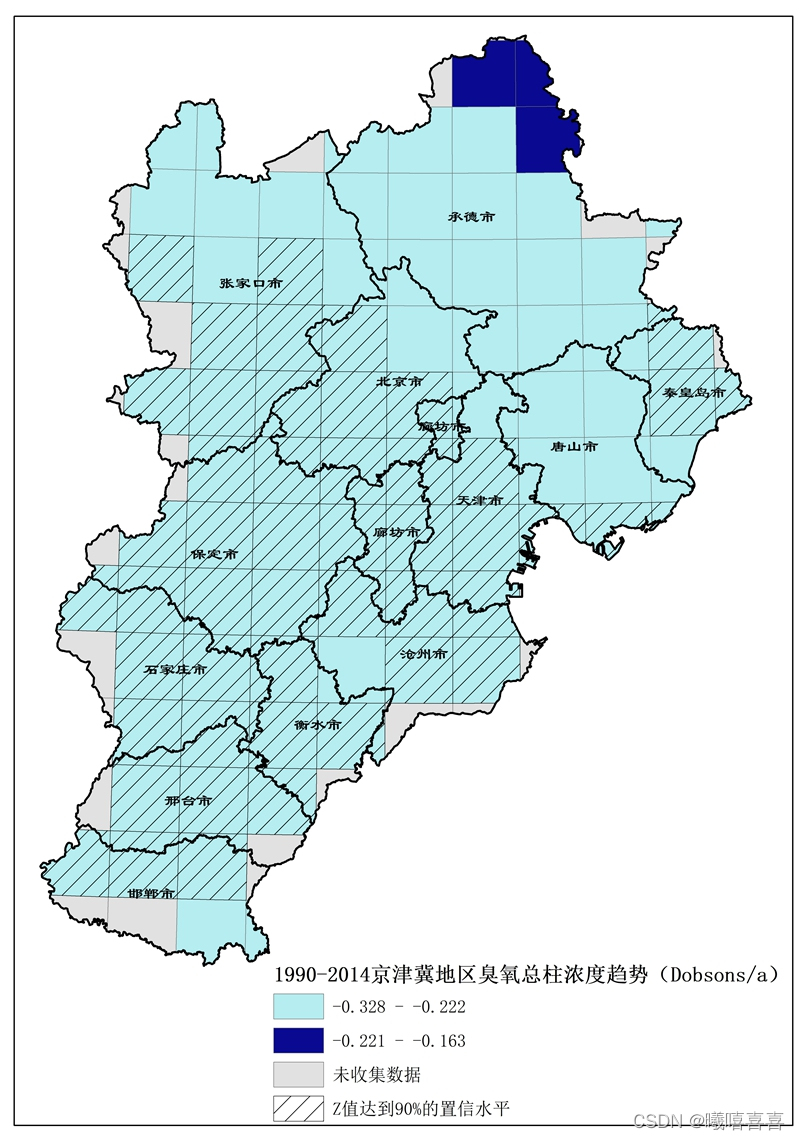
20220213—趋势分析图(GIS京津冀地区空间可视化&MATLAB总体25年的趋势)
a=xlsread('to3_1989.10-2014.09.xlsx','total.mean');
a1=a(2:85,:);
b=[];
for i=1:size(a1,2)
mid=median(a1(:,i));
b=[b;mid];
end
b2=polyfit(x,b,1);
b22=polyval(b2,x);
f=vpa(poly2sym(b2));
figure
axis normal
subplot(2,1,1)
boxplot(a1)
hold on
plot(x,b,'k*',x,b22,'r--');
h=text(18,295,'$$y=333-0.37x$$','Interpreter','latex')
xlabel('年份')
ylabel('京津冀地区夏玉米单产(万吨/公顷)')
title('京津冀地区夏玉米单产箱型图')
set(gca,'xticklabel',{'1990','','','','','1995','','','','','2000','','','','','2005',...
'','','','','2010','','','','2014'})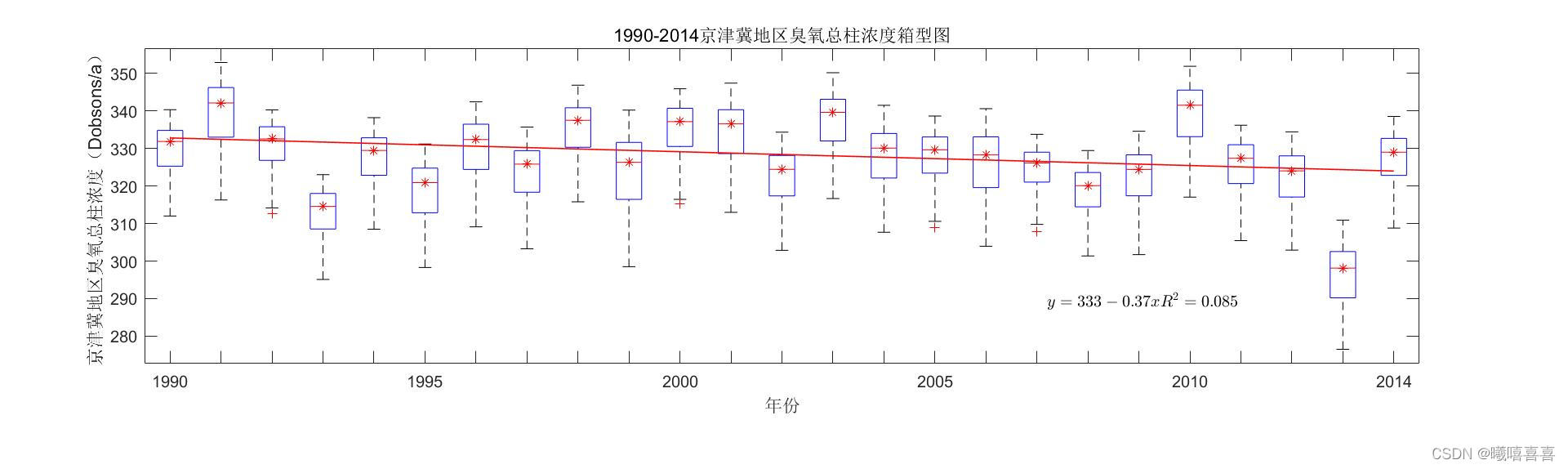
text函数的应用:(可参考以下博文)
【MATLAB】基本绘图 ( text 函数 | annotation 函数 | 绘制图像示例 )_让 学习 成为一种 习惯 ( 韩曙亮 の 技术博客 )-CSDN博客
[mtalab学习记录03]matlab中输入LaTeX公式_没头脑nao的博客-CSDN博客
继续学习数理统计相关知识:
昨天(平均值、中位数、众数)
20220214—1990-2014年各月份趋势变化—某几个月份年变化趋势
a=xlsread('to3_1989.10-2014.09.xlsx','Sheet1');
j=[];f=[];mr=[];ap=[];my=[];ju=[];jy=[];au=[];sep=[];oct=[];nov=[];dec=[];
for i=5:12:301
j1=a(2:85,i);
j1=median(j1)
j=[j;j1];
f1=a(2:85,i+1);
f1=median(f1)
f=[f;f1];
mr1=a(2:85,i+2);
mr1=median(mr1)
mr=[mr;mr1];
ap1=a(2:85,i+3);
ap1=median(ap1)
ap=[ap;ap1];
my1=a(2:85,i+4);
my1=median(my1)
my=[my;my1];
ju1=a(2:85,i+5);
ju1=median(ju1)
ju=[ju;ju1];
jy1=a(2:85,i+6);
jy1=median(jy1)
jy=[jy;jy1];
au1=a(2:85,i+7);
au1=median(au1)
au=[au;au1];
sep1=a(2:85,i+8);
sep1=median(sep1)
sep=[sep;sep1];
oct1=a(2:85,i-3);
oct1=median(oct1)
oct=[oct;oct1];
dec1=a(2:85,i-2);
dec1=median(dec1)
dec=[dec;dec1];
nov1=a(2:85,i-1);
nov1=median(nov1);
nov=[nov;nov1];
end
total=[j f mr ap my ju jy au sep oct nov dec];
boxplot(total)
xlabel('月份')
ylabel('京津冀地区臭氧总柱浓度(Dobsons)')
title('1990-2014期间各月份京津冀地区臭氧总柱浓度箱型图')
某几个月份年变化趋势
b=xlsread('aod_1989.10-2014.09.xlsx','Sheet1');
bb=b(2:end,2:end);
bm666=[];bm777=[];bm888=[];bm999=[];
for k=1:size(bb,1)
b1=bb(k,:);
bm6=[];bm7=[];bm8=[];bm9=[];
for j=9:12:300
bm66=b1(j);bm6=[bm6 bm66];
bm77=b1(j+1);bm7=[bm7 bm77];
bm88=b1(j+2);bm8=[bm8 bm88];
bm99=b1(j+3);bm9=[bm9 bm99];
end
bm666=[bm666;bm6];bm777=[bm777;bm7];bm888=[bm888;bm8];bm999=[bm999;bm9];
mean6=mean(bm666,1);mean7=mean(bm777,1);mean8=mean(bm888,1);mean9=mean(bm999,1);
end
x=[1990:2014];
figure
plot(x,mean6,'-r+');
hold on
plot(x,mean7,'-b*');
hold on
plot(x,mean8,'-ys');
hold on
plot(x,mean9,'-k^');
xlabel('年份')
ylabel('京津冀地区6-9各月份气溶胶光学厚度多年变化趋势')
title('1990-2014京津冀地区6-9各月份气溶胶光学厚度多年变化趋势')
legend('6月份AOD','7月份AOD','8月份AOD','9月份AOD');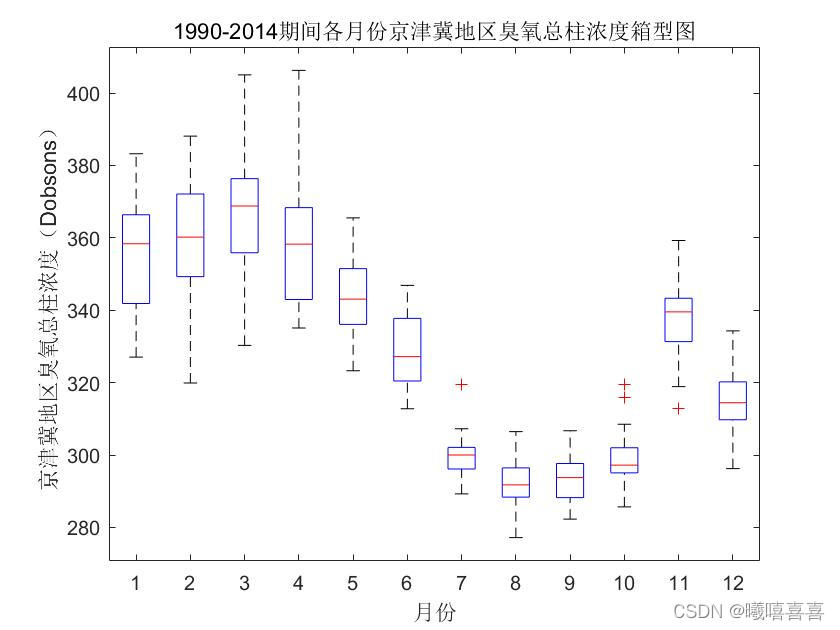
20220215—B站视频学习【统计学速成课】Statistics - [45集全/中英双语] - Crash Course Statistics_哔哩哔哩_bilibili
(正态分布)
20220223—B站视频学习【公开课-85集全】可汗学院:统计学(强烈推荐)_哔哩哔哩_bilibili
1.平均数、中位数、众数(数据集中趋势)
各自的应用情况不同,数据都比较均匀的平均水平、个别不均匀偏大偏小的中等水平、数据多部分出现偏大偏小的多数水平;
2.极差(最大数-最小数);中程数(最大值最小值的平均值)
3.象形图、条形图(同一个对象不同时期比如分数的比较)、线形图(趋势变化)、饼图(占比)
多幅线形图中的刻度可能会给人误导;
4.茎叶图(茎代表十位数、叶代表个位数;说明球员成绩分布)
5.箱线图(与中位数有关)
中位数、上四分数、下四分数;须告诉最大值最小值;中位数离哪端较近;
20220224—B站视频学习
显著性检验
如何通俗地理解假设检验基本原理_R语言中文社区-CSDN博客(例子好懂)
R语言各种假设检验实例整理(常用) - ywliao - 博客园
【小记】显著性差异的计算_yaoyz105-CSDN博客_显著性差异如何计算
关于显著性检验,你想要的都在这儿了!!(基础篇)_weixin_33796205的博客-CSDN博客
6.统计学(描述性、推论性【样本——整体】)
20220225—B站视频学习,去趋势分析
时间序列去趋势分析
时间序列--去趋势_kylin_learn的博客-CSDN博客_时间序列怎么去趋势
参考以下博文,matlab操作夏玉米单产数据以及总柱臭氧数据线性去趋势
使用Matlab对数据进行去趋势(detrend)_wokaowokaowokao12345的专栏-CSDN博客_detrend
夏玉米单产:
a=xlsread('gai-maizey.xls','gai-maizey');
a1=a(:,4:28);
am=a1(1,:);
t=(1990:2014);
figure
plot(t,am);
legend('Original Data','Location','northwest');
xlabel('year');
ylabel('maize yield');
detrend_am= detrend(am);
trend = am - detrend_am;
mean(detrend_am)
hold on
plot(t,trend,':r')
plot(t,detrend_am,'m')
plot(t,zeros(size(t)),':k')
legend('Original Data','Trend','Detrended Data',...
'Mean of Detrended Data','Location','northwest')
xlabel('year');
ylabel('maize yield');
总柱臭氧去趋势:
b=xlsread('to3_1989.10-2014.09.xlsx','maize.mean1');
b1=b(2:83,:);
bm=b1(1,:);
figure
plot(t,bm);
legend('Original Data','Location','northwest');
xlabel('year');
ylabel('TO3');
detrend_bm= detrend(bm);
trend = bm - detrend_bm;
mean(detrend_bm)
hold on
plot(t,trend,':r')
plot(t,detrend_bm,'m')
plot(t,zeros(size(t)),':k')
legend('Original Data','Trend','Detrended Data',...
'Mean of Detrended Data','Location','northwest')
xlabel('year');
ylabel('TO3');
去趋势后夏玉米单产和总柱臭氧关系
a=xlsread('gai-maizey.xls','gai-maizey');
a1=a(:,4:28);
am=a1(1,:);
t=(1990:2014);
detrend_am= detrend(am);
b=xlsread('to3_1989.10-2014.09.xlsx','maize.mean1');
b1=b(2:83,:);
bm=b1(1,:);
detrend_bm= detrend(bm);
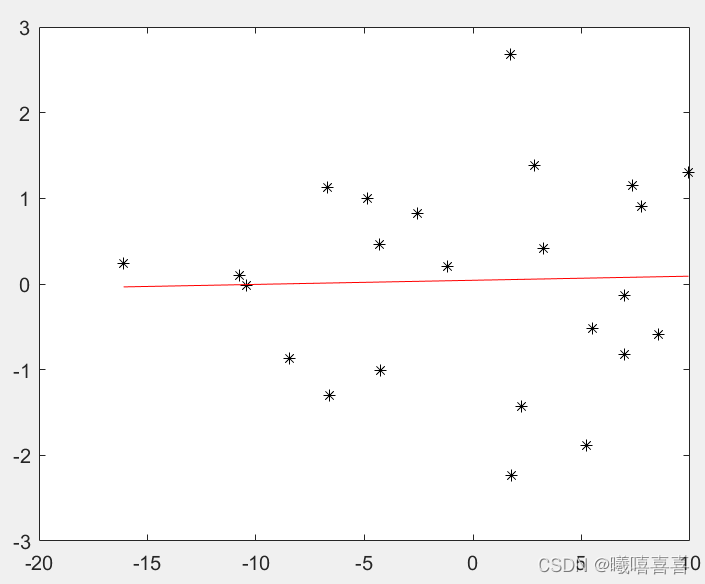
p = polyfit(detrend_bm,detrend_am,1);
f = polyval(p,detrend_bm);
up=(detrend_am-f).^2;
down=(detrend_am-mean(detrend_am)).^2;
r2=1-( sum(up)/sum(down) );
plot(detrend_bm,detrend_am,'k*',detrend_bm,f,'r-')
添加循环:
a=xlsread('gai-wheaty.xls','gai-wheaty');
a1=a(:,4:28);
b=xlsread('to3_1989.10-2014.09.xlsx','wheat.mean1');
b1=b(2:66,:);
cofr=[];
cofp=[];
for j=1:length(a1)
am=a1(j,:);
bm=b1(j,:);
avalue=[];
bvalue=[];
detrend_am= detrend(am);
detrend_bm= detrend(bm);
[r1,p1]=corrcoef(detrend_bm(:),detrend_am(:));
cofr=[cofr;r1(1,2)];
cofp=[cofp;p1(1,2)];
end
差分法去趋势的matlab实现
a=xlsread('gai-maizey.xls','gai-maizey');
a1=a(:,4:28);
am=a1(1,:);
avalue=[];
b=xlsread('to3_1989.10-2014.09.xlsx','maize.mean1');
b1=b(2:83,:);
bm=b1(1,:);
bvalue=[];
for i=1:length(am)-1
valuea = am(i+1) - am(i);
avalue=[avalue valuea];
valueb = bm(i+1) - bm(i);
bvalue=[bvalue valueb];
end
p = polyfit(bvalue,avalue,1);
f = polyval(p,bvalue);
up=(avalue-f).^2;
down=(avalue-mean(avalue)).^2;
r2=1-( sum(up)/sum(down) );
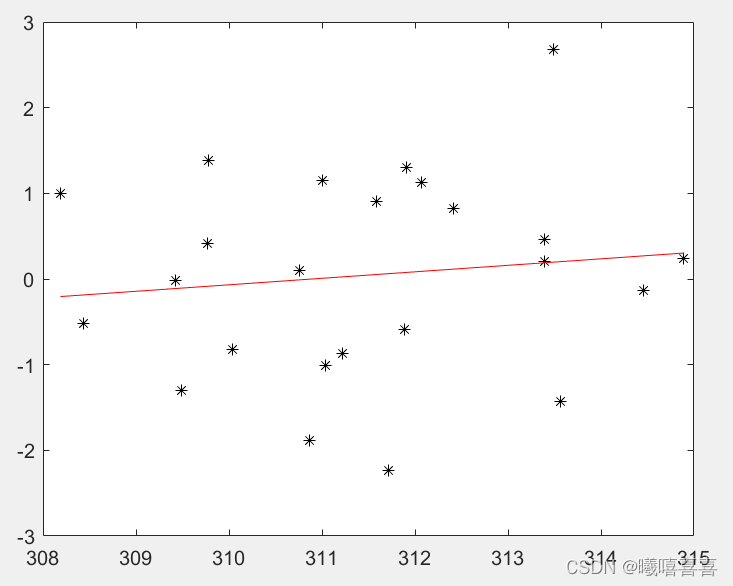
plot(bvalue,avalue,'k*',bvalue,f,'r-')两种方法最后求单产和臭氧浓度相关性时,相关性不高,R2太小















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









