







1、混淆矩阵
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。在人工智能中,混淆矩阵是可视化工具,特别用于监督学习。
混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。
|
| 预测值 | ||
| Positive | Negative | ||
| 真实值 | Positive | True Positive (TP) | False Negative (FN) |
| Negative | False Positive (FP) | True Negative (TN) | |
真阳性(True Positive, TP):样本的真实类别是正例,并且模型预测的结果也是正例
真阴性(True Negative, TN):样本的真实类别是负例,并且模型将其预测成为负例
假阳性(False Positive, FP):样本的真实类别是负例,但是模型将其预测成为正例
假阴性(False Negative, FN):样本的真实类别是正例,但是模型将其预测成为负例
2、混淆矩阵延伸出来的各个评价指标
|
| 公式 | 意义 |
| 准确率ACC |
| 在所有样本中,预测正确的样本占的比例 |
| 精确率PPV |
| 在所有预测为正例的样本中,预测正确为正例所占的比例 |
| 召回率/敏感度/真阳率TPR |
| 在所有实际为正例的样本中,预测正确为正例所占的比例 |
| 特异度TNR |
| 在所有实际为负例的样本中,预测正确为负例所占的比例 |
| 流行程度 |
| 在所有样本中,实际为正例所占的比例 |
| F1-Score |
| F1-Score就是精确率和召回率的调和平均值,F1-Score值认为精确率和召回率一样重要,其取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。 |
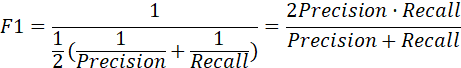
3、混淆矩阵的实例
当分类问题是二分问题是,混淆矩阵可以用上面的方法计算。当分类的结果多于两种的时候,混淆矩阵同样适用。
举例,如有150个样本数据,预测为1,2,3类各为50个。分类结束后得到的混淆矩阵如下:
|
| 预测 | |||
| 类1 | 类2 | 类3 | ||
| 实际
| 类1 | 43 | 2 | 0 |
| 类2 | 5 | 45 | 1 | |
| 类3 | 2 | 3 | 49 | |
第一行说明有43个属于第一类的样本被正确预测为了第一类,有2个属于第一类的样本被错误预测为了第二类。第一列说明有43个属于第一类的样本被正确预测为了第一类,有5个属于第二类的样本、2个属于第三类的样本被错误预测为了第一类。
![]()
以类1为例,计算其他指标
![]()
![]()

![]()
如果感觉不错,那就给我点个赞吧(^_−)☆















 1456
1456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











