






 Viola-Jones算法是经典的目标检测方法,主要用于人脸识别。它结合了Adaboost算法和Haar-like特征,通过级联分类器实现高效检测。然而,该方法对遮挡和姿态变化的处理能力有限,且易过拟合。积分图技术的引入加速了特征计算,而级联检测结构允许快速排除背景区域。尽管存在局限性,但该算法在当时开创了实时人脸识别的先河。
Viola-Jones算法是经典的目标检测方法,主要用于人脸识别。它结合了Adaboost算法和Haar-like特征,通过级联分类器实现高效检测。然而,该方法对遮挡和姿态变化的处理能力有限,且易过拟合。积分图技术的引入加速了特征计算,而级联检测结构允许快速排除背景区域。尽管存在局限性,但该算法在当时开创了实时人脸识别的先河。
- VJ相关:
- 对应任务:目标检测:物体定位+物体分类
- 传统目标检测方法的缺点:
- 特征难以设计
- 特征不鲁棒,效率存在瓶颈
- 滑动窗口提取策略繁琐
- 算法的基本流程:输入->候选框->特征提取->分类器判定目标 or背景 ->nms->输出
- NMS:非极大值抑制,计算置信度,进行候选框的合并、过滤,寻找最佳物体检测位置
- 这里写的应该两步法进行的目标检测)
- 一步法应该是特征提取+直接回归
- VJ算法最初用于检测正面的人脸图像
- VJ前,人脸检测的方法:
- 基于知识:利用先验知识将人脸看做器官特征的组合,根据器官的特征和相互之间的几何位置检测人脸,常用方法有模板匹配等
- 基于统计:将人脸看做一个整体的模式(二维像素矩阵),从统计的观点通过大量人脸图像样本构造人脸模式空间,根据相似度来判断人脸是否存在,常用的方法有PCA与特征脸等
- VJ框架在adaboost算法的基础上,使用haar-like小波特征和积分图技术来进行人脸检测
- VJ算法的创新点:
- 采用积分图像技术,加速对haar-like输入特征的计算
- 采用adaboost算法进行特征选择,选择出几个关键的视觉特征
- 采用检测级联提高准确率,允许图像的背景区域被很快丢弃,从而将更多的计算放在可能是目标的区域上,减少了计算开销
-
VJ算法的问题:
-
Haar-like特征是一种相对简单的特征,其稳定性较低
-
弱分类器采用简单的决策树,容易过拟合。对于解决正面的人脸效果好,对于人脸的遮挡,姿态,表情等特殊且复杂的情况,处理效果不理想
-
基于VJ-cascade的分类器设计,进入下一个分类器后,之前的信息都丢弃了,分类器评价一个样本不会基于样本在之前步骤中的表现,导致分类器的鲁棒性差。
-
- 补充知识记录:
- haar-like小波特征:
- Haar小波是最简单的小波函数,用于对信号进行均值、细节分解。
- 现有的Haar特征模板(包含边缘特征,线性特征,中心特征,对角线特征):
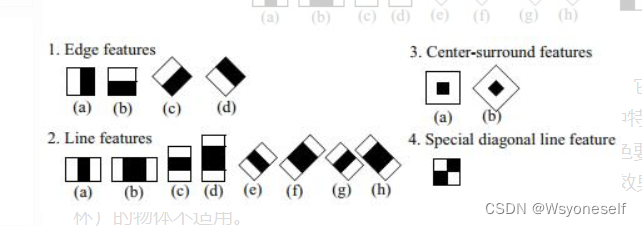 (图1)Haar-like特征定义为上图中白黑矩形区域像素之和的差值。它在灰度分布均匀的区域特征值趋近于0。Haar特征在一定程度上反应了图像灰度的局部变化,这种特征捕捉图像的边缘、变化等信息。
(图1)Haar-like特征定义为上图中白黑矩形区域像素之和的差值。它在灰度分布均匀的区域特征值趋近于0。Haar特征在一定程度上反应了图像灰度的局部变化,这种特征捕捉图像的边缘、变化等信息。 - 人脸的五官有各自的亮度信息,例如眼睛比周围区域的颜色要深,鼻梁比两侧颜色要浅。下图是通过AdaBoost算法自动筛选出来的对区分人脸和非人脸有用的Haar-like特征,基本符合人类的直观感受。
 (图2)
(图2) - 论文中提出的特征:
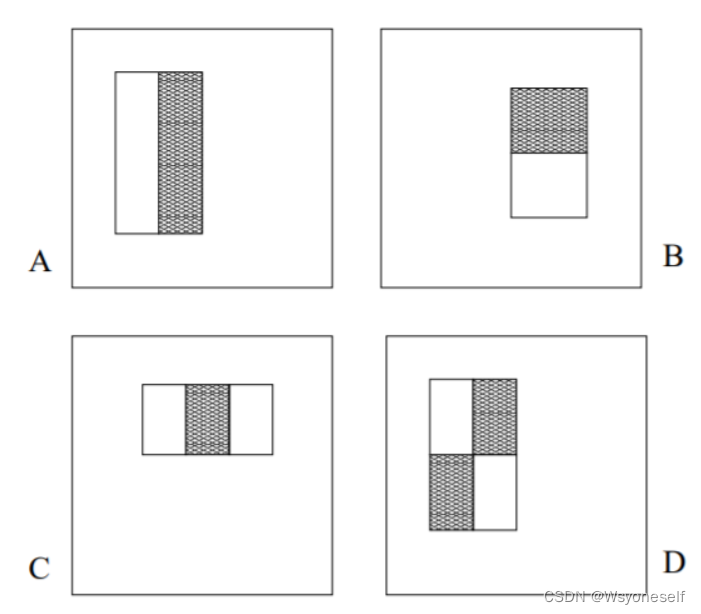 (图3)
(图3) - 特征提取过程:
-
从图3中选择一种,在图像中进行平移+放大(都是分别沿着x和y进行操作),但注意过程中要保持原始的颜色比例,重复过程,直到放大后的特征与检测窗口一样大,便得到了系列相关特征了。
-
当得到的特征维度远远高于本身的维度时,需要进行特征选择。
-
- 积分图技术:
- 积分图:是一种计算方法,以加快盒滤波或卷积过程。积分图像让vj检测器中每个窗口的计算复杂度与其窗口大小无关。
- 积分图构建算法:逐行扫描图像,递归计算每个像素行方向的累加和和积分图像的值(图中的f函数表示图像中像素值)(参考:(一)目标检测之 Viola-Jones_天青如水的博客-CSDN博客_violajones算法)

- 因为积分图像中的任何一点的值等于位于该点左上角所有像素之和,当获取积分图像后,求取任意一个矩形区域的像素和只需要知道该矩形区域四个边角点的值即可
- adaboost算法:
- 是一种迭代算法
- 核心思想:针对同一个训练集训练不同的分类器(弱分类器),再将这些弱分类器集合起来,构成一个更强的最终分类器
-
adaboost可同时进行特征选择和分类器训练
-
使用adaboost算法从一组巨大的随机特征池(就是前面提出出来的haar-like特征)中选择一组对人脸检测最有帮助的特征
-
算法流程:
-
给定示例图像(x_1,y_1),…(x_n,y_ n),其中y=0,1分别用于负示例和正示例
-
对于y_ i=0,1,分别初始化权重w_=(1,i)=1/2m · 1/2L,其中m和L分别是负和正的数字。for t=1,... ,T:
-
权重归一化:每个权重除以所有权重之和,使得w_ t是概率分布。
-
对于每个特征j,训练分类器h_ j,该分类器仅限于使用单个特征。
-
相对于w_ t评估误差,

-
选择误差ε_ i最小的分类器h_t
-
更新权重:
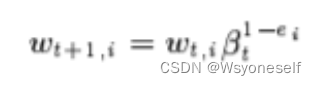
-
其中,如果示例x_ i分类正确,则e_t=0,否则e_t=1
-
最后的强分类器是 :
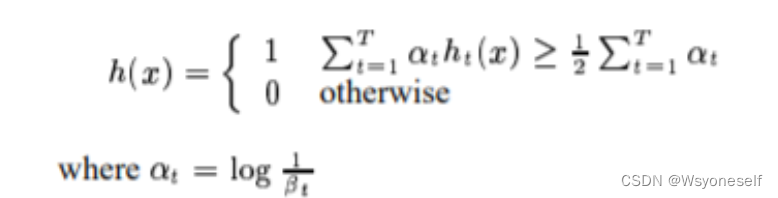
-
-
- 级联检测:
-
级联检测通过增加分类器个数可以在提高强分类器检测率的同时降低误识率
-
原因:用简单的强分类器在初期快速排除掉大量的非人脸窗口,同时保证高的召回率。
-
使最终可以通过所有级强分类器的样本数很少。
-
依据:检测图像中,绝大部分不是人脸而是背景,即人脸是一个稀疏事件。
级联检测的过程类似一个决策树,如下图,只有true才会触发下一级的检测,只要出现false则判断该窗口不包含目标。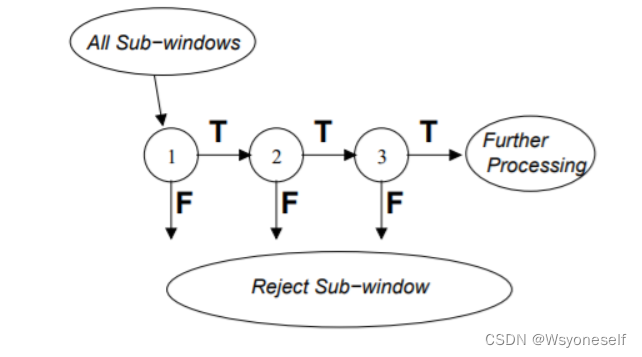
-
对每个子窗口应用一系列分类器。
-
初始分类器通过很少的处理消除了negative的example。
-
经过几个阶段的处理后,子窗口的数量已大幅减少。
-
-
- 级联分类器的训练过程要考虑以下两种平衡:
- 弱分类器的个数和计算时间的平衡(增加特征个数能提高检测率和降低误识率,但会增加计算时间)
- 强分类器检测率和误识率之间的平衡。
-
检测时,需要对图片中进行多区域、多尺度的检测:
-
多区域:对图片划分多块,对每个块进行检测。
-
多尺度检测机制一般有两种策略
-
不改变搜索窗口的大小,不断缩放图片,需要对每个缩放后的图片进行区域特征值的运算,效率不高
-
不断初始化搜索窗口size为训练时的图片大小,不断扩大搜索窗口,进行搜索,解决了第一种方法的弱势。在区域放大的过程中会出现同一个人脸被多次检测,这需要进行区域的合并。
-
VJ算法采用了第二种方法。无论哪一种搜索方法,都会为输入图片输出大量的子窗口图像,这些子窗口图像经过筛选式级联分类器会不断地被每一个节点筛选,抛弃或通过。
-
-
-
- haar-like小波特征:
Viola-Jones检测器(VJ)---学习笔记

于 2022-08-05 14:31:33 首次发布


















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









