






- 困惑度:用于评价语言模型的好坏。判断一个语言模型的好坏,一般有两种方法:
- 将模型应用到具体的问题中,如机器翻译、speech recognition、spelling corrector等。然后看这个语言模型在这些任务中的表现(extrinsic evaluation,or invivo evaluation)。但是,这种方法一方面难以操作,另一方面可能非常耗时,可能跑一个evaluation需要大量时间,费时难操作。
- 给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好
- 计算困惑度:
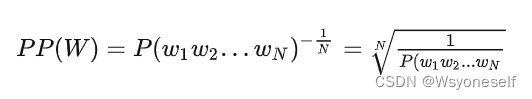 句子概率越大,语言模型越好,迷惑度越小。
句子概率越大,语言模型越好,迷惑度越小。 -
补充“语言模型":
-
语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率
-
原始计算概率的方法(所有单词的条件概率相乘(每个单词依赖于前面所有词汇))的缺陷:
-
參数空间过大:条件概率P(wn|w1,w2,..,wn-1)的可能性太多,无法估算,不可能有用;
-
数据稀疏严重:对于非常多词对的组合,在语料库中都没有出现,依据最大似然估计得到的概率将会是0。
-
- 马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。
- 一般来说,N元模型就是假设当前词的出现概率只与它前面的N-1个词有关。而这些概率参数都是可以通过大规模语料库来计算
-
困惑度---学习笔记

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









