







目录
1.《FCNs in the Wild- Pixel-level Adversarial and Constraint-based Adaptation》
2.《Learning to adapt structured output space for semantic segmentation》
3.《ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation》编辑
4.《Bidirectional Learning for Domain Adaptation of Semantic Segmentation》
迁移分割的背景介绍
语义分割面临的两大问题是
- 缺少有标签的数据集
- 语义分割还需要覆盖现实世界的数据集。但实际情况是,它很难覆盖所有的情况,比如不同的天气,不同地方,建筑的不同风格,这都是语义分割要面临的问题。
除了要从数据集上来解决,他们发现可以通过计算机图形学等技术通过合成出模拟的数据集代替真实世界的这些数据集,从而降低标注的成本。 因此目标就是通过研究出来的迁移算法解决在源域训练的模型在目标域上性能降低的问题。
一.基于对抗学习:通过强制来自不同域的特征来混淆判别器减少域偏移。
1.《FCNs in the Wild- Pixel-level Adversarial and Constraint-based Adaptation》
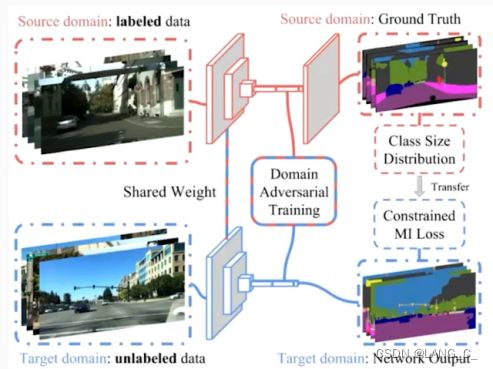
首次将语义分割应用在迁移学习的文章, 迁移学习需要最小化源数据和目标数据表示特征之间的域转移差异,通过对语义分割的特征提取器提取出来的特征送入到这个判别器里面,然后通过对齐全局的信息,完成分割任务上的迁移。
训练判别器,就能让它区分输入进来的图片到底是真还是假。在这个过程中,需要用判别器区分输入的特征是源域还是目标域。得到一个能够区分特征是源域和目标域的判别器之后,固定判别的参数不变,去训练分割网络的特征提取器。如何训练呢:让这个特征提取器来混淆这个判别器。那么特征提取器又怎么来混淆判别器呢?无论是提取源域还是目标域的特征,都要把这两个特征的分布对齐,这样的话就相当于对这两个域的特征,使这个判别器区分不出来,那么就完成了“混淆”的任务。一旦完成了“混淆”任务,就说明特征提取器提取到了这个“域不变”的信息。提取到“域不变”的信息,实际上就是在做一个迁移过程。因为网络有了提取“域不变”信息的功能,那么无论是源域还是目标域都能提取出来一个非常好的特征。
核心思想:在特征提取器上提取的特征做对抗训练来提取域不变信息。
2.《Learning to adapt structured output space for semantic segmentation》
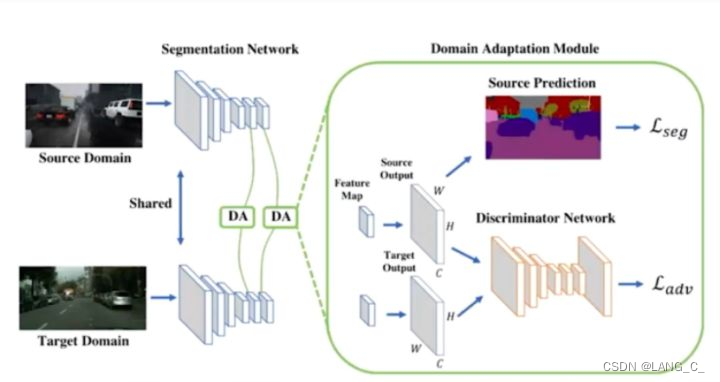
因为在分割任务中由于特征提取器提取到的特征维数会特别高(如2048),会产生大量冗余的信息,所以作者舍弃这一方法,从分类层入手,就是经过softmax之后的概率层,也叫做output space,实际上只有类别数的这样的一个维度,就是假如类别数c的话,它这个概率对于每个像素点就是c*1的一个向量。虽然是低维度空间,但是一整个图片的输出,实际上包含了场景、布局以及上下文这些丰富的信息。
核心思想:将output space的概率做对抗训练来提取域不变信息。作者还利用对多个层次的输出进行对抗,进一步提高了模型。论文作者认为不管图片来自于源域还是目标域,分割出来的结果在空间上,应该是具有非常强的相似性的。
如上图,其源域和目标域都是针对于自动驾驶来做的。很明显的一个观点是,中间大部分可能是路,上面一般是天,然后左右可能是建筑。这种场景上的分布是有非常强的相似性的,因此作者认为直接使用低维度的这个概率,就是softmax输出来进行对抗就能取得一个非常好的效果。
3.《ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation》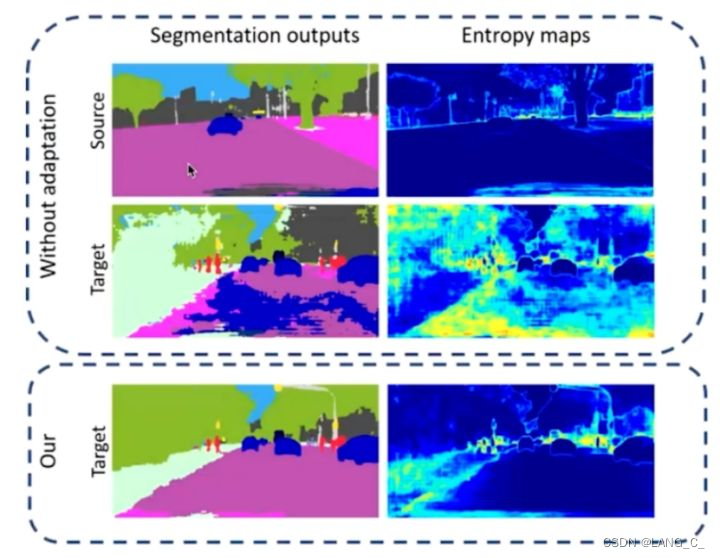
通过观察上图,作者发现了一个现象:在源域的分割图中得到熵值的分布,可以发现在这些类别的边缘部分,熵值是非常高的(颜色越深,代表熵值越低;颜色越浅,代表熵值越高)。那么对于目标域的那个图片,我们可以看到,其预测出来的结果,整张图片的颜色浅的部分是非常多的。因此,作者认为,因为源域上有太多没有用的熵值(因为存在一定噪声),通过减少目标率的熵值可以缩减源域和目标域之间的差距。
那么怎么去减少目标域的熵值呢?作者提出了两种方法,也即本文的算法创新点:
1、利用基于熵的损失函数,防止网络对目标域做出可信度较低的预测;
2、提出了一种基于熵的对抗学习方式,同时考虑熵减和两个领域的结构对齐。
利用对抗学习来最小化熵值,即得到一个图片总体的熵,直接通过梯度反向传播来优化总体的熵。但是作者认为如果直接做熵减的话,会忽略很多信息,就比如图片本身的语义结构信息等。因此作者借鉴上篇讲output space对抗的方式,其提出了一种利用对抗学习来做熵减的方法。
可以看到,前面图片中源域的熵是非常低的,因此他认为如果能够用一个Discriminator来区分源域和目标域,从而使源域和目标域最终的输出的熵图非常相似的话,就可以减少目标域的熵。具体的做法就是和上一篇类似,只不过第一篇是直接把概率做到判别器里面,而第二篇是把熵送到判别器里面进行判别,从而完成整个过程。
4.《Bidirectional Learning for Domain Adaptation of Semantic Segmentation》
4.1介绍
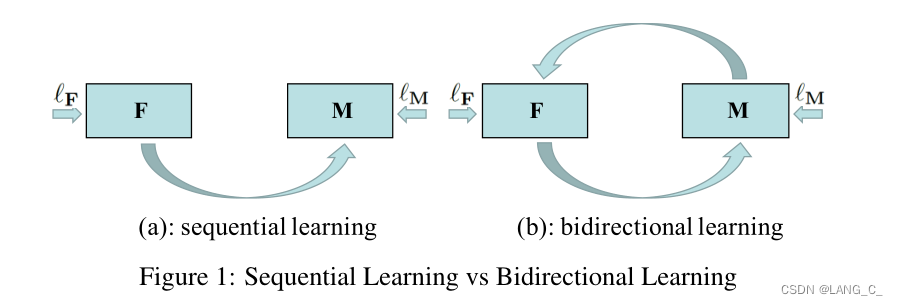
Figure1(a):之前的工作是这种单向的顺序训练,分为子网络F和子网络M,源图像S在F中转化到目标域F(S),它的标签还是S的标签,因为只转换了风格,再将F(S)送入M中去分割出目标,这种两阶段的好处如下
- F帮助减小域之间的差异;
- 当域之间的差异减小时,M很容易学习,从而导致更好的性能。 但是,该解决方案有一些限制。 一旦学习到F,就将其固定。 M没有反馈可以提高F的性能。此外,M的一次尝试学习似乎只是学习有限的可迁移知识。从图中可以看到
只负责更新F,
只负责更新M。
Figure1(b):我们提出的方法建立在(a)的基础上,利用双向学习来互相更新F和M。
4.2 双向学习
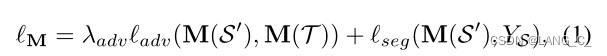
第一阶段就是一个正常的单向迁移,第一个损失是将真实的目标域图像T和伪目标域图像S'分割后得到的结果送入判别器中做对抗训练,得到对抗损失,使得真伪目标图像表示差异最小化。第二阶段是将伪目标域图像S'和其标签(源域标签)送入M中训练,得到分割损失。
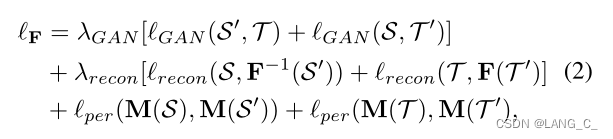
其中对称地计算三个损失,即S->T和T->S,以确保图像到图像的转换一致。 GAN损失强制S'和T之间的两个分布彼此相似。 T'=(T),其中
是F的反函数,它将图像从T映射回S。当从S'的图像转换回S时,损失
测量重建误差。
是维持S和S'之间或T和T'之间的语义一致性的感知损失。一旦得打理想的分割自适应模型M,无论S和S'还是T和T'都应具有相同的标签,即使S和S'之间或T和T'之间存在视觉差异。
后向更新基于更新后的 M,在 GAN 误差和图像重构误差的基础上,增加感知误差(目标识别预训练网络获取特征的距离)
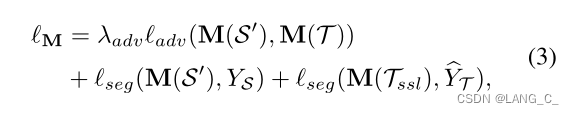
是属于T的,一开始是空的,慢慢增加。提升M的自监督训练损失,当训练好一个分割效果不错的M后,就可以通过自训练SSL的方式来给无标签的目标图像分配高置信度的伪标签了,然后重新自训练,还结合了一个对抗损失。
4.3整体框架
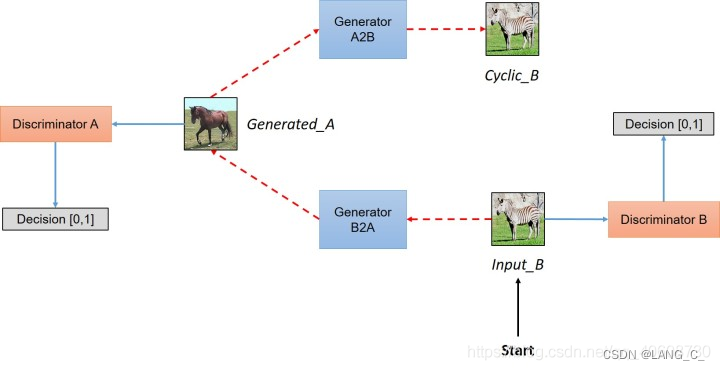
这里先引入了一个cyclegan的网络框架辅助理解,本文中的转换模型用的就是cyclegan。
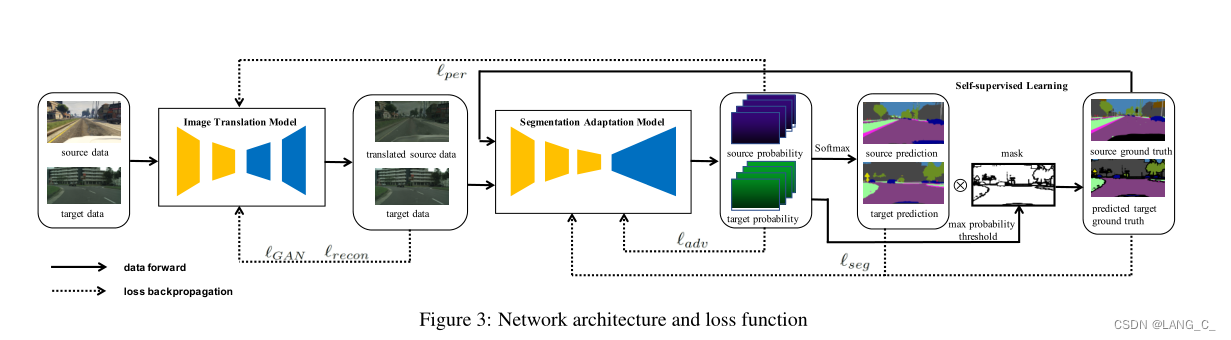
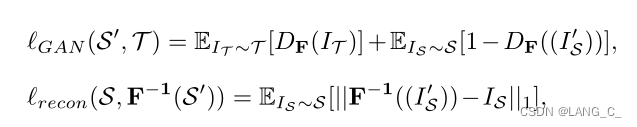
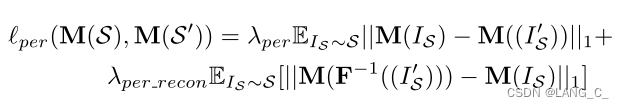
源域的图像和伪目标域的图像都送入M中,求loss,伪目标域反向后得到伪重建S再和源域一起送入M求loss。 得到感知损失
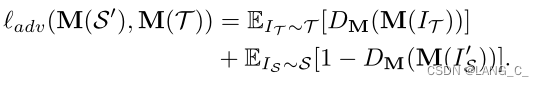
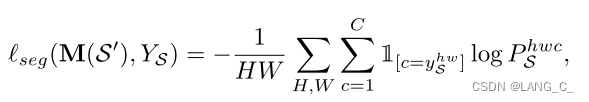
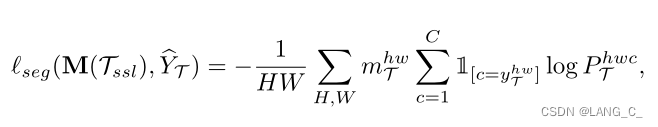
图中一共有5个损失,具体的话一共有6个,因为最后一个有俩,如上
4.4 算法

- Training CycleGAN with corresponding loss to get translated GTA images.
- BDL.py: Training segmentation network with translated GTA images and Cityscpes images
- SSL.py: Obtaining the pseudo labels for Cityscapes and fine-tuning the segmentation network
- Trainig CycleGAN with perceptual loss, while fixing the parameters of segmentation network.
4.5 实验结果
其中 ![]() 表示第 k 轮外循环(通过前向和后向更新 F 和 M)第 i 轮内循环(通过自监督更新 M)的结果。
表示第 k 轮外循环(通过前向和后向更新 F 和 M)第 i 轮内循环(通过自监督更新 M)的结果。
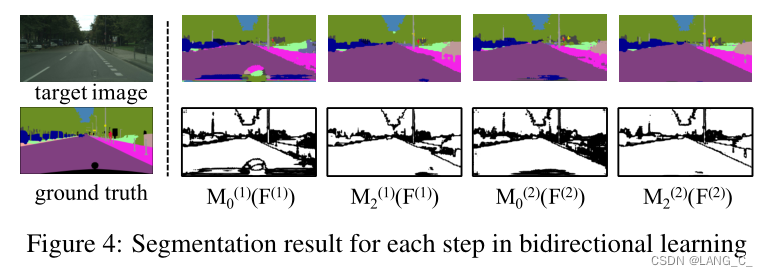
结论:图像到图像的转换和分割模块交替训练,每个模块都从另一个模块获得正反馈。分割网络得益于原始监督下类似目标的翻译源图像,而生成网络则借助预测器保持语义一致性。这种闭环结构有效地允许渐进适应,图像到图像的翻译质量和语义预测精度逐渐提高.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









