






如何设计一个关系型数据库

为什么需要索引?
快速查询数据
什么样的信息能成为索引?
主键、唯一键以及普通键等
索引的数据结构
- 生成索引,建立二叉查找树进行二分查找
- 生成索引,建立Bv名 Tree结构进行查找
- 生成索引,建立B±Three结构进行查找
- 生成索引,建立Hash结构进行查找
密集索引和稀疏索引的区别
密集索引:文件中的每个搜索码值都对应一个索引值,就是叶子节点保存了整行, innodb只有一个
稀疏索引:文件只为索引码的某些值建立索引项, 比如 innodb的其他索引只存了键位信息和主键, myisam的所有索引都是
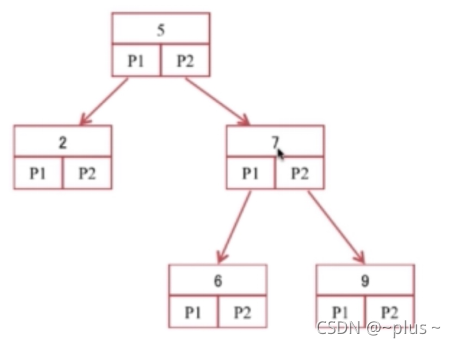
优化你的索引 – 运用二叉查找树

优化你的索引 – 运用B树
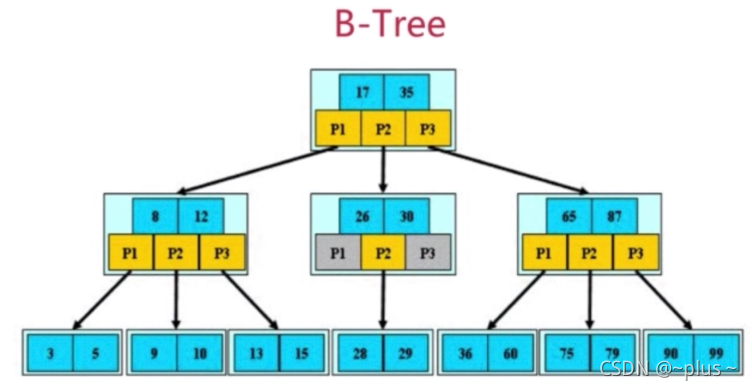
B-Tree定义:
(1)根节点至少包含两个孩子
(2)树中每个节点最多含有m个孩子(m >= 2)
(3)除了根节点和叶子节点外,其他每个节点至少有ceil(m/2)个孩子
(4)所有叶子节点都位于同一层
(5)假设每个非终端节点中包含有n个关键字信息,其中
a)Ki(i=1…n)为关键字,且关键字按顺序K(i-1)< Ki
b)关键字的个数n必须满足:[ceil(m/2)-1]<=n<=m-1
c)非叶子节点的指针:P[1],P[2],….P[M]:其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1],K[i])的子树
优化你的索引 – 运用B+树
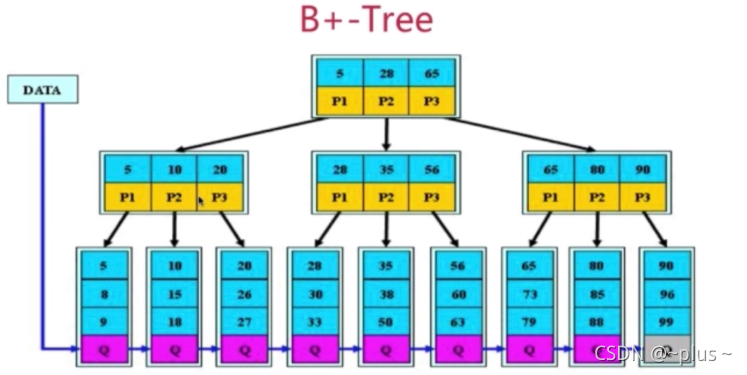
B+ -Tree定义:
B+树是B树的变体,其定义基本与B树相同,除了:
(1)非叶子节点的子树指针与关键字个数相同
(2)非叶子节点的子树指针P[i],指向关键字值[K[i],K[i+1]]的子树
(3)非叶子节点仅用来索引,数据都保存在叶子节点中
(4)所有叶子节点均有一个指针指向下一个叶子节点
注意结论:B+ -Tree更适合用来做存储索引
1)B+树的磁盘读写代价更低
2)B+树的查询效率更加稳定
3)B+树更有利于对数据库的扫描
优化您的索引 – 运用Hash以及BitMap
hash索引
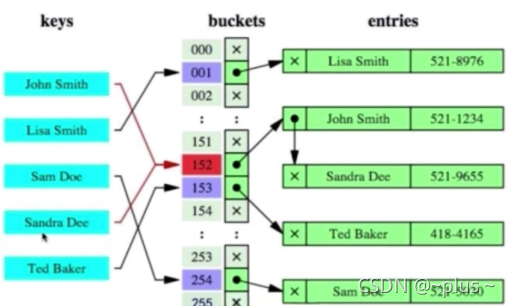
hash缺点:
1)仅仅能满足”=” ,”IN”,不能使用范围查询
2)无法被用来避免数据排序操作
3)不能利用部分索引键查询
4)不能避免表扫描
5)遇到大量hash值相等的情况后性能并不一定就会比B-Tree索引高
obitmap索引
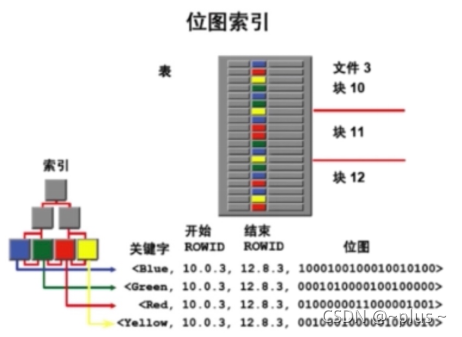
只有oracle数据库支持.
密集索引和稀疏索引的区别
密集索引文件中的每个搜索码值对应一个索引值
稀疏索引文件只为索引码的某些值建立索引项
额外知识
InnoDB
若一个主键被定义,该主键则作为密集索引
若没有主键被定义,该表的第一个唯一非空索引则作为密集索引
若不满足以上条件,innodb内部会生成一个隐藏主键(密集索引)
非主键索引存储相关键位和其对应的主键值,包含2次查找
MyISam
只有稀疏索引
InnoDB: 支持事务安全的引擎,支持外键、行锁、事务是他的最大特点。如果有大量的update和insert,建议使用InnoDB,特别是针对多个并发和QPS较高的情况。
MyISAM: 默认表类型,它是基于传统的ISAM类型,ISAM是Indexed Sequential Access Method (有索引的顺序访问方法) 的缩写,它是存储记录和文件的标准方法。不是事务安全的,而且不支持外键,如果执行大量的select,insert MyISAM比较适合。















 42万+
42万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











