







最小生成树
一个连通图的生成树包含图的所有顶点,并且只含尽可能少的边。对于生成树来说,若砍去它的一条边,则会使生成树变成非连通图;若给它增加一条边,则会形成图中的一条回路。
对于一个带权连通无向图 G = ( V , E ) {\rm G=(V,E)} G=(V,E) ,生成树不同,每棵树的权(即树中所有边上的权值之和)也可能不同。设 ℜ {\rm \Re} ℜ 为 G {\rm G} G 的所有生成树的集合,若 T {\rm T} T 为 ℜ {\rm \Re} ℜ 中边的权值之和最小的那棵生成树, 则 T {\rm T} T 称为 G {\rm G} G 的最小生成树( M i n i m u m − S p a n n i n g − T r e e , M S T {\rm Minimum-Spanning-Tree, MST} Minimum−Spanning−Tree,MST)。
不难看出,最小生成树具有如下性质:
1)最小生成树不是唯一的,即最小生成树的树形不唯一,
ℜ
{\rm \Re}
ℜ 中可能有多个最小生成树。当图
G
{\rm G}
G 中的各边权值互不相等时,
G
{\rm G}
G 的最小生成树是唯一的;若无向连通图
G
{\rm G}
G 的边数比顶点数少1,即
G
{\rm G}
G 本身是一棵树时,则
G
{\rm G}
G 的最小生成树就是它本身。
2)最小生成树的边的权值之和总是唯一的,虽然最小生成树不唯一,但其对应的边的权值之和总是唯一的,而且是最小的。
3)最小生成树的边数为顶点数减1
构造最小生成树有多种算法,但大多数算法都利用了最小生成树的下列性质:假设 G = ( V , E ) {\rm G=(V,E)} G=(V,E) 是一个带权连通无向图, U {\rm U} U 是顶点集 V {\rm V} V 的一个非空子集。若 ( u , v ) {\rm (u,v)} (u,v) 是一条具有最小权值的边,其中 u ∈ U , v ∈ V − U {\rm u \in U,v \in V-U} u∈U,v∈V−U ,则必存在一棵包含边 ( u , v ) {\rm (u,v)} (u,v) 的最小生成树。
基于该性质的最小生成树算法主要有 P r i m {\rm Prim} Prim 算法和 K r u s k a l {\rm Kruskal} Kruskal 算法,它们都基于贪心算法的策略。 对这两种算法应主要掌握算法的本质含义和基本思想,并能够手工模拟算法的实现步骤。
1.Prim算法
P r i m {\rm Prim} Prim(普里姆)算法的执行非常类似于寻找图的最短路径的 D i j k s t r a {\rm Dijkstra} Dijkstra 算法。
P r i m {\rm Prim} Prim 算法构造最小生成树的过程如下图所示。初始时从图中任取一顶点(如顶点1)加入树 T {\rm T} T ,此时树中只含有一个顶点,之后选择一个与当前 T {\rm T} T 中顶点集合距离最近的顶点,并将该顶点和相应的边加入 T {\rm T} T ,每次操作后 T {\rm T} T 中的顶点数和边数都增 1。以此类推,直至图中所有的顶点都并入 T {\rm T} T ,得到的 T {\rm T} T 就是最小生成树。此时 T {\rm T} T 中必然有 n − 1 {\rm n-1} n−1 条边。
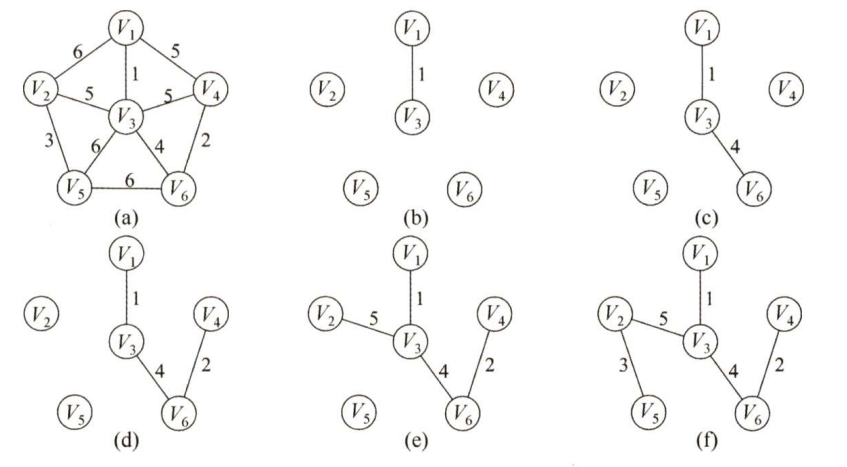
P
r
i
m
{\rm Prim}
Prim 算法的步骤如下:
假设
G
=
{
V
,
E
}
{\rm G= \{ V,E \}}
G={V,E} 是连通图,其最小生成树
T
=
{
U
,
E
T
}
{\rm T= \{ U,E_T \}}
T={U,ET} ,
E
T
{\rm E_T}
ET 是最小生成树中边的集合。
初始化:向空树
T
=
{
U
,
E
T
}
{\rm T= \{ U,E_T \}}
T={U,ET} 中添加图
G
=
{
V
,
E
}
{\rm G= \{ V,E \}}
G={V,E} 任一顶点
u
0
{\rm u_0}
u0 ,使
U
=
{
u
0
}
{\rm U= \{ u_0 \}}
U={u0} ,
E
T
=
∅
{\rm E_T= \emptyset }
ET=∅ 。
循环(重复下列操作直至
U
=
V
{\rm U=V}
U=V ):从图
G
{\rm G}
G 中选择满足
{
(
u
,
v
)
∣
u
∈
U
,
v
∈
V
−
U
}
{\rm \{ (u,v)|u \in U, v \in V-U \}}
{(u,v)∣u∈U,v∈V−U} 且具有最小权值的边
(
u
,
v
)
{\rm (u,v)}
(u,v) ,加入树
T
{\rm T}
T ,置
U
=
U
∪
{
v
}
,
E
T
=
E
T
∪
{
(
u
,
v
)
}
{\rm U=U \cup \{ v \} , E_T=E_T \cup \{ (u,v) \}}
U=U∪{v},ET=ET∪{(u,v)}。
P
r
i
m
{\rm Prim}
Prim 算法的具体实现:
P
r
i
m
{\rm Prim}
Prim 算法需要实现两个关键的概念,即树
T
{\rm T}
T 的实现、顶点
V
i
(
0
≤
i
≤
n
−
1
)
{\rm V_i(0 \le i \le n-1)}
Vi(0≤i≤n−1) 与树
T
{\rm T}
T 的最短距离。
1)树
T
{\rm T}
T 的实现,即使用一个bool型数组visited[]表示顶点是否已被访问。其中visited[i]==true表示顶点
V
i
{\rm V_i}
Vi 已被访问,visited[i]==false则表示顶点
V
i
{\rm V_i}
Vi 未被访问。
2)不妨令int型数组d[]来存放顶点
V
i
(
0
≤
i
≤
n
−
1
)
{\rm V_i(0 \le i \le n-1)}
Vi(0≤i≤n−1) 与树
T
{\rm T}
T 的最短距离。初始时除了起点s的d[s]赋为0,其余顶点都赋为一个很大的数来表示INF,即不可达。
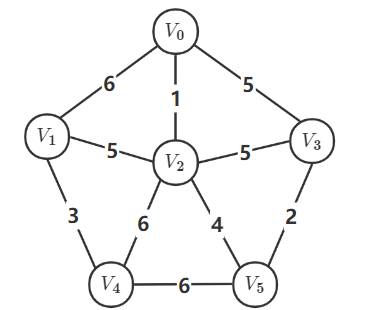
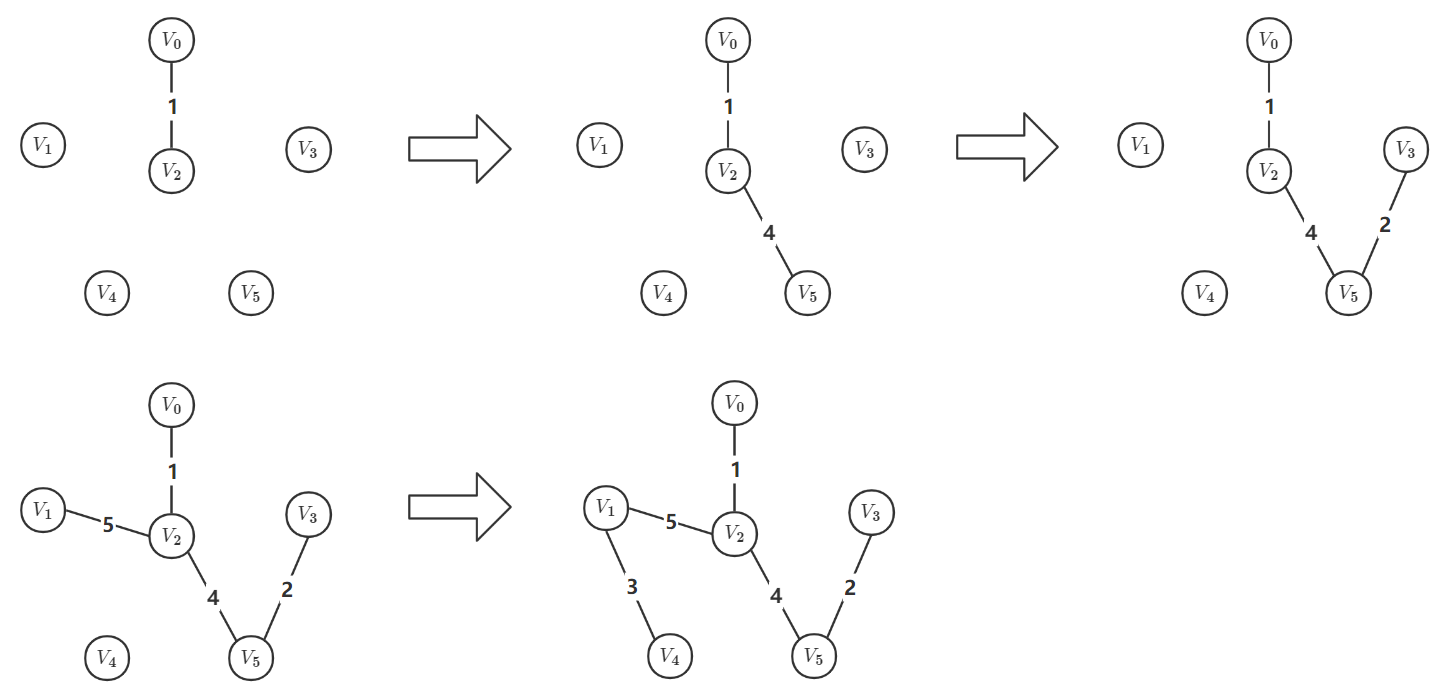
以下面的带权连通无向图为例,给出使用邻接矩阵的 P r i m {\rm Prim} Prim 算法代码:
#include <iostream>
#include <vector>
using namespace std;
#define MaxVertexNum 100 //顶点数目的最大值
#define INF 1000000000 //设INF为一个很大的数
struct Edge { //图中一条边的结构
int u, v; //两个顶点
int weight; //权值
};
struct MST { //存储最小生成树
int totalWeight; //最小生成树边权的和
vector<Edge> edges; //最小生成树的边集合
};
// VertexType,顶点的数据类型
template<typename VertexType>
class MGraph {
private:
VertexType Vex[MaxVertexNum]; //顶点表
int adjacentMatrix[MaxVertexNum][MaxVertexNum]; //邻接矩阵,边表
int vexnum, arcnum; //图的当前顶点数和弧数
bool visited[MaxVertexNum]; //如果顶点i已被访问,则visited[i]==true。初值为false
Edge distance[MaxVertexNum]; //顶点i与树T的最短距离及对应的边
MST mst; //该图的最小生成树
int prim() {
int totalWeight = 0; //存储最小生成树边权的和
for (int i = 0; i < vexnum; i++) { //循环vexnum次,向最小生成树中加入vexnum个顶点
int u = -1, MIN = INF;
for (int k = 0; k < vexnum; k++) //找到与最小生成树距离最近的未访问顶点
if (visited[k] == false && distance[k].weight < MIN) {
u = k;
MIN = distance[k].weight;
}
//找不到距离小于INF的顶点,则剩下的顶点和树mst不连通
if (u == -1)
return -1;
visited[u] = true; //标记顶点u已被加入树mst
totalWeight += distance[u].weight;
if (u != 0) //不是起始顶点才向树mst中加入对应的边
mst.edges.push_back(distance[u]);
for (int k = 0; k < vexnum; k++) //刷新未访问顶点和树mst之间最短的距离及对应的边
if (visited[k] == false && adjacentMatrix[u][k] != 0 && adjacentMatrix[u][k] < distance[k].weight) {
distance[k].weight = adjacentMatrix[u][k];
distance[k].u = u;
}
}
return totalWeight;
}
public:
MGraph() {
//初始化visited数组、邻接矩阵、distance、mst
mst.totalWeight = 0;
for (int i = 0; i < MaxVertexNum; i++) {
visited[i] = false;
distance[i].v = i;
distance[i].weight = INF;
for (int k = 0; k < MaxVertexNum; k++)
adjacentMatrix[i][k] = 0;
}
distance[0].weight = 0; //直接将v0顶点加入最小生成树,设置其与最小生成树的距离为0
}
void create() {
int row, col, weight;
cin >> vexnum >> arcnum; //输入实际图的顶点数和边数
for (int i = 0; i < vexnum; i++) //输入顶点信息
cin >> Vex[i];
for (int i = 0; i < arcnum; i++) { //输入边信息
cin >> row >> col >> weight;
adjacentMatrix[row][col] = weight;
adjacentMatrix[col][row] = weight;
}
}
//输出最小生成树
void displayMST() {
mst.totalWeight = prim();
if (mst.totalWeight == -1)
return;
//输出最小生成树的边权和以及对应的边
cout << "MST:" << endl;
cout << "totalWeight:" << mst.totalWeight << endl;
cout << "u\t" << "v\t" << "weight" << endl;
for (int i = 0; i < mst.edges.size(); i++)
cout << mst.edges[i].u << "\t" << mst.edges[i].v << "\t" << mst.edges[i].weight << endl;
}
};
int main() {
MGraph<string> G;
G.create();
G.displayMST();
return 0;
}
输入数据:
6 10
v0 v1 v2 v3 v4 v5
0 1 6
0 2 1
0 3 5
1 2 5
1 4 3
2 3 5
2 4 6
2 5 4
3 5 2
4 5 6
输出结果:
MST:
totalWeight:15
u v weight
0 2 1
2 5 4
5 3 2
2 1 5
1 4 3
P r i m {\rm Prim} Prim 算法的时间复杂度为 O ( ∣ V ∣ 2 ) {\rm O( \left | V \right | ^2 ) } O(∣V∣2) ,不依赖于 ∣ E ∣ {\rm {\left | E \right |} } ∣E∣ ,因此它适用于求解边稠密的图的最小生成树。
2.Kruskal 算法
与 P r i m {\rm Prim} Prim 算法从顶点开始扩展最小生成树不同, K r u s k a l {\rm Kruskal} Kruskal(克鲁斯卡尔)算法是一种按权值的递增次序选择合适的边来构造最小生成树的方法。
K
r
u
s
k
a
l
{\rm Kruskal}
Kruskal 算法的基本思想为:在初始状态时隐去图中的所有边,这样图中每个顶点都自成一个连通块。之后执行下面的步骤:
1)对所有边按边权从小到大进行排序。
2)按边权从小到大测试所有边,如果当前测试边所连接的两个顶点不在同一个连通块中,则把这条测试边加入当前最小生成树中;否则,将边舍弃。
3)执行步骤2,直到最小生成树中的边数等于总顶点数减1或是测试完所有边时结束。而当结束时如果最小生成树的边数小于总顶点数减1,说明该图不连通。
因此, K r u s k a l {\rm Kruskal} Kruskal 算法的思想简单说来就是:每次选择图中最小边权的边,如果边两端的顶点在不同的连通块中,就把这条边加入最小生成树中。
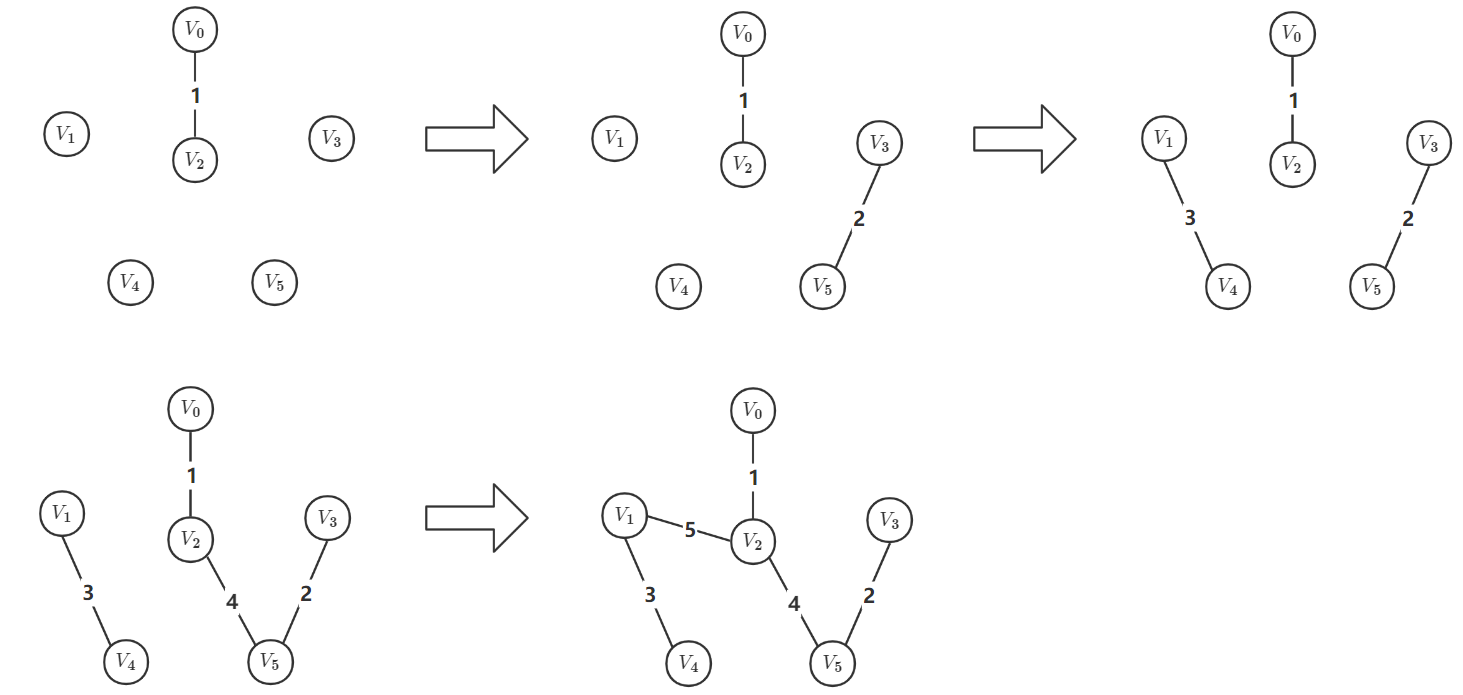
以下面的带权连通无向图为例,使用 K r u s k a l {\rm Kruskal} Kruskal 算法构造最小生成树
边的有序列表如下(红色字体代表被加入到最小生成树中的边):
| (0,2) | (3,5) | (1,4) | (2,5) | (0,3) | (1,2) | (2,3) | (0,1) | (2,4) | (4,5) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 5 | 5 | 6 | 6 | 6 |
K r u s k a l {\rm Kruskal} Kruskal 算法的实现:
首先是边的定义。对 K r u s k a l {\rm Kruskal} Kruskal 算法来说,由于需要判断边的两个端点是否在不同的连通块中,因此边的两个端点的编号一定是需要的;而算法中又涉及边权,因此边权也必须要有。于是可以定义一个结构体,在里面存放边的两个端点编号和边权即可满足需要。
struct Edge {
int u, v; //边的两个端点编号
int cost; //边权
};
在解决了边的定义后,需要写一个排序函数来让数组E按边权从小到大排序,因此不妨自定义sort的cmp函数:
bool cmp(Edge a, Edge b) {
return a.cost < b.cost;
}
接下来就要解决
K
r
u
s
k
a
l
{\rm Kruskal}
Kruskal 算法本身的实现了,其中有两个关键点:
1)如何判断测试边的两个端点是否在不同的连通块中。
2)如何将测试边加入最小生成树中。
事实上,对这两个问题,可以换一个角度来想。如果把每个连通块当作一个集合,那么就可以把问题转换为判断两个端点是否在同一个集合中,而这个问题可以使用并查集。并查集可以通过查询两个结点所在集合的根结点是否相同来判断它们是否在同一个集合,而合并功能恰好可以把上面提到的第二个关键点解决,即只要把测试边的两个端点所在集合合并,就能达到将边加入最小生成树的效果。
详细实现代码如下:
#include <iostream>
#include <vector>
#include "algorithm"
using namespace std;
#define MaxVertexNum 100 //顶点数目的最大值
#define MaxEdgeNum 10000 //边数目的最大值
struct Edge {
int u, v; //边的两个端点编号
int cost; //边权
};
struct MST { //存储最小生成树
int totalWeight; //最小生成树边权的和
vector<Edge> edges; //最小生成树的边集合
};
//sort的cmp函数
bool cmp(Edge a, Edge b) {
return a.cost < b.cost;
}
// VertexType,顶点的数据类型
//template<typename VertexType>
class MGraph {
private:
// VertexType Vex[MaxVertexNum]; //顶点表
// int adjacentMatrix[MaxVertexNum][MaxVertexNum]; //邻接矩阵,边表
int vexnum, edgenum; //图的当前顶点数和边数
Edge edges[MaxEdgeNum]; //存储图的所有边及其权重
int father[MaxVertexNum]; //并查集数组
MST mst; //存储最小生成树
//并查集查询函数
int findFather(int x) {
int a = x;
while (x != father[x])
x = father[x];
//路径压缩
while (a != father[a]) {
int z = a;
a = father[a];
father[z] = x;
}
return x;
}
int kruskal() {
int mstTotalWeight = 0, mstEdgeNum = 0; //生成树的边权和及边的数量
//所有边按权从小到大排序
sort(edges, edges + edgenum, cmp);
for (int i = 0; i < edgenum; i++) { //枚举所有边
//拿到两个顶点所在集合的根结点
int faU = findFather(edges[i].u);
int faV = findFather(edges[i].v);
if (faU != faV) { //该边的两个顶点不在一个集合中
father[faU] = faV; //合并集合
mst.edges.push_back(edges[i]); //将该边加入到生成树中
mstTotalWeight += edges[i].cost; //计算边权和
mstEdgeNum++; //当前生成树的边数+1
if (mstEdgeNum == vexnum - 1) //生成树的边数等于顶点数减1时,结束算法
break;
}
}
if (mstEdgeNum != vexnum - 1) //无法连通时,返回-1
return -1;
return mstTotalWeight;
}
public:
MGraph() {
mst.totalWeight = 0;
//初始化并查集数组
for (int i = 0; i < MaxVertexNum; i++)
father[i] = i;
}
void create() {
int row, col, weight;
cin >> vexnum >> edgenum; //输入实际图的顶点数和边数
for (int i = 0; i < edgenum; i++) { //输入边信息
cin >> row >> col >> weight;
edges[i].u = row;
edges[i].v = col;
edges[i].cost = weight;
}
}
//输出最小生成树
void displayMST() {
mst.totalWeight = kruskal();
if (mst.totalWeight == -1)
return;
//输出最小生成树的边权和以及对应的边
cout << "MST:" << endl;
cout << "totalWeight:" << mst.totalWeight << endl;
cout << "u\t" << "v\t" << "weight" << endl;
for (int i = 0; i < mst.edges.size(); i++)
cout << mst.edges[i].u << "\t" << mst.edges[i].v << "\t" << mst.edges[i].cost << endl;
}
};
int main() {
MGraph G;
G.create();
G.displayMST();
return 0;
}
输入数据:
6 10
0 1 6
0 2 1
0 3 5
1 2 5
1 4 3
2 3 5
2 4 6
2 5 4
3 5 2
4 5 6
输出结果:
MST:
totalWeight:15
u v weight
0 2 1
3 5 2
1 4 3
2 5 4
1 2 5
可以看到, k r u s k a l {\rm kruskal} kruskal 算法的时间复杂度主要来源于对边进行排序,因此其时间复杂度是 O ( E l o g E ) {\rm O(ElogE)} O(ElogE),其中 E {\rm E} E 为图的边数。显然 k r u s k a l {\rm kruskal} kruskal 适合顶点数较多、边数较少的情况,这和 p r i m {\rm prim} prim 算法恰好相反。于是可以根据题目所给的数据范围来选择合适的算法,即如果是稠密图(边多),则用prim算法;如果是稀疏图(边少),则用kruskal算法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









