







系统学习Pytorch笔记二:Pytorch的动态图、自动求导及逻辑回归
Pytorch的动态图、自动求导及逻辑回归
背景
学习知识先有框架(至少先知道有啥东西)然后再通过实战(各个东西具体咋用)来填充这个框架。 而这个系列的目的就是在脑海中先建一个Pytorch的基本框架出来。关于系统学习Pytorch,逻辑上就是按照机器学习的那五大步骤进行的, 步骤为:数据模块 -> 模型模块 -> 损失函数 -> 优化器 -> 迭代训练。
接着上次的学习Pytorch的数据载体张量与线性回归进行整理,这次主要包括Pytorch的计算图机制和自动求导机制,并且最后基于前面的所学玩一个逻辑回归。
计算图与Pytorch的动态图机制
计算图
计算图是用来描述运算的有向无环图。 主要有两个因素: 节点和边。 其中节点表示数据,如向量,矩阵,张量, 而边表示运算,如加减乘除,卷积等。使用计算图的好处不仅让计算更加简洁,更大的优势就是让梯度求导更加方便。
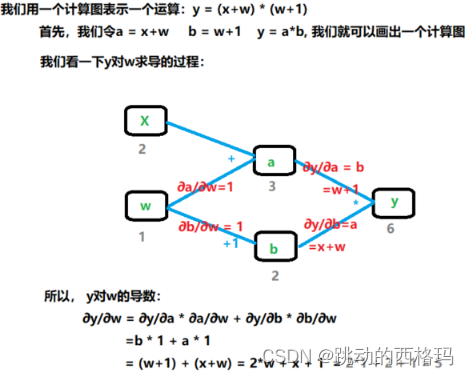
计算图里面张量比较重要的属性:
- is_leaf: 指示张量是否是叶子节点
- grad_fn: 记录创建该张量时所用的方法(函数),记录这个方法主要用于梯度的求导
叶子节点: 用户创建的节点, 比如上面的x和w。叶子节点是非常关键的,在上面的正向计算和反向计算中,其实都是依赖于我们叶子节点进行计算的。
为什么要设置叶子节点的这个概念的? 主要是为了节省内存,因为在反向传播完了之后,非叶子节点的梯度是默认被释放掉的。
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(w.grad) # tensor([5.])
#查看叶子结点
print("is_leaf:\n", w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf)
#查看梯度, 默认是只保留叶子节点的梯度的
print("gradient:\n", w.grad, x.grad, a.grad, b.grad, y.grad)
## 结果:
is_leaf:
True True False False False
gradient:
tensor([5.]) tensor([2.]) None None None
如果想保留a的梯度, 那么可以使用retain_grad()方法。 就是在执行反向传播之前, 执行一行代码:a.retain_grad()即可
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
a.retain_grad()
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
# 查看 grad_fn 这个表示怎么得到的
print("grad_fn:\n", w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn)
## 结果:
None None <AddBackward0 object at 0x0000029AECF56D08> <AddBackward0 object at 0x0000029AEEFEB248> <MulBackward0 object at 0x0000029AEEFEB748>
# 查看 grad
print("gradient:\n", w.grad, x.grad, a.grad, b.grad, y.grad)
## 结果:
gradient:
tensor([5.]) tensor([2.]) tensor([2.]) None None
grad_fn属性 会记录变量具体是怎么得到的, 比如两数相加,或者两数相乘,这样反向计算梯度的时候才能使用相应的法则求变量的梯度。
Pytorch的动态图机制
根据计算图的搭建方式,可以将计算图分为动态图和静态图。
静态图: 先搭建图,后运算。动态图: 运算与搭建同时进行。更灵活,易调节,目前TensorFlow(2.0之后)、Pytorch都采样动态图构建。
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
print(y) # tensor([6.], grad_fn=<MulBackward0>)
边建图边执行,比较灵活, 有错误可以随时改,也更接近我们一般的想法。
Pytorch的自动求导机制
torch.autograd.backward()方法
Pytorch自动求导机制使用的是torch.autograd.backward方法, 功能就是自动求梯度。

- tensors表示用于求导的张量,如loss。
- retain_graph表示保存计算图, 由于Pytorch采用了动态图机制,在每一次反向传播结束之后,计算图都会被释放掉。如果我们不想被释放,就要设置这个参数为True
- create_graph表示创建导数计算图,用于高阶求导。
- grad_tensors表示多梯度权重。如果有多个loss需要计算梯度的时候,就要设置这些loss的权重比例。
这时候我们就有疑问了啊? 我们上面写代码的过程中并没有见过这个方法啊? 我们当时不是直接y.backward()吗? 哪有什么torch.autograd.backward()啊? 其实,当我们执行y.backward()的时候,背后其实是在调用后面的这个函数。
如果retain_graph参数默认,默认是不保留,即一次反向传播之后,计算图就会被释放掉,这时候,如果再次调用y.backward, 就会报错。
还有一个比较重要的参数叫做grad_tensors, 这个是当有多个梯度的时候,控制梯度的权重。
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y0 = torch.mul(a, b)
y1 = torch.add(a, b)
loss =torch.cat([y0,y1],dim=0)
loss.backward()
# 这里有两个梯度,如果直接backward会报错,因为程序不知道使用哪个梯度作为w的梯度
上面这个过程会报错,这时候我们就需要用到gradient这个参数了 , 给两个梯度设置权重,最后得到的w的梯度就是带权重的这两个梯度之和。
grad_tensors = torch.tensor([1., 1.])
loss.backward(gradient=grad_tensors)
print(w.grad) # 这时候会是tensor([7.]) 5+2
grad_tensors = torch.tensor([1., 2.])
loss.backward(gradient=grad_tensors)
print(w.grad) # 这时候会是tensor([9.]) 5+2*2
有点奇怪,backward() 明明是grad_tensors参数,为什么调用的时候默认要传入gradient (不过不影响正常使用!)

torch.autograd.grad()方法
除了backward()方法,还有一个比较常用的方法叫做:torch.autograd.grad(), 这个方法的功能是求取梯度, 这个可以实现高阶的求导。

- outputs: 用于求导的张量, 如loss
- inputs: 需要梯度的张量, 如上面例子的w
- create_graph: 创建导数计算图,用于高阶求导
- retain_graph: 保存计算图
- grad_outputs: 多梯度权重
x = torch.tensor([3.], requires_grad=True)
y = torch.pow(x, 2) # y=x^2
# 一次求导
grad_1 = torch.autograd.grad(y, x, create_graph=True) # 这里必须创建导数的计算图, grad_1 = dy/dx = 2x
print(grad_1) # (tensor([6.], grad_fn=<MulBackward0>),) 这是个元组,二次求导的时候我们需要第一部分
# 二次求导
grad_2 = torch.autograd.grad(grad_1[0], x) # grad_2 = d(dy/dx) /dx = 2
print(grad_2) # (tensor([2.]),)
函数还允许对多个自变量求导数
x1 = torch.tensor(1.0,requires_grad = True) # x需要被求导
x2 = torch.tensor(2.0,requires_grad = True)
y1 = x1*x2
y2 = x1+x2
# 允许同时对多个自变量求导数
(dy1_dx1,dy1_dx2) = torch.autograd.grad(outputs=y1,inputs = [x1,x2],retain_graph = True)
print(dy1_dx1,dy1_dx2) # tensor(2.) tensor(1.)
# 如果有多个因变量,相当于把多个因变量的梯度结果求和
(dy12_dx1,dy12_dx2) = torch.autograd.grad(outputs=[y1,y2],inputs = [x1,x2])
print(dy12_dx1,dy12_dx2) # tensor(3.) tensor(2.)
关于Pytorch的自动求导系统要注意
1、梯度不自动清零: 就是每一次反向传播,梯度都会叠加上去, 这个要注意。训练神经网络时,每一次反向传播之后,我们要手动的清除梯度。w.grad.zero_() ,这里有个下划线,这个代表原位操作.
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
for i in range(4):
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(w.grad)
## 结果:
tensor([5.])
tensor([10.])
tensor([15.])
tensor([20.])
torch.mul(a, b) 是矩阵a和b对应位相乘,a和b的维度必须相等。Pytorch矩阵乘法之torch.mul() 、 torch.mm() 及torch.matmul()的区别,可参考https://blog.csdn.net/irober/article/details/113686080
2、依赖于叶子节点的节点, requires_grad默认为True。
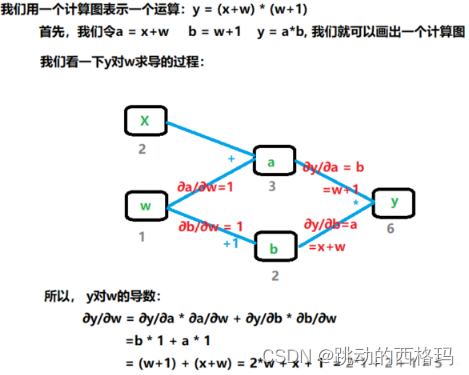
拿上面的计算图过来解释一下,依赖于叶子节点的节点,在上面图中w,x是叶子节点,而依赖于叶子节点的节点,其实这里说的就是a,b, 也就是a,b默认就是需要计算梯度的。但注意,虽然这里默认是计算梯度的,但非叶子节点的梯度默认是不保存的,也就是会被清空掉,所以如果想要保留下来,依然是需要再建立计算图之前加入a.retain_grad()这个操作。
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b) # y0=(x+w) * (w+1) dy0 / dw = 5
print(w.requires_grad, a.requires_grad, b.requires_grad) # 这里会都是True, w的我们设置了True, 而后面这里是依赖于叶子,所以默认是True
True True True
3、叶子节点不可执行in-place(原位操作)
in-place操作, 这个操作就是在原始内存当中去改变这个数据。
我们拿一个a+1的例子看一下,我们知道数字的话理论上是一个不可变数据对象,类似于字符串,元组这种,比如我假设a=1, 然后我执行a=a+1, 这样的话,a虽然是2,但是这两个a其实指向的对象是不一样的,原来的1并没有改变,执行a+1, 是新建了一个对象出来, 然后改变了原来a的指向。 这就是数字的不可变现象。我们知道列表示可变的,假设a=[1,5,3],我们可以a.append(4),此时a指向的对象就变成了[1,5,3,4],但其实是在原对象[1,2,3]上进行的添加,此过程没有新对象产生。 我们还可以a.sort(), 这时候a指向的对象就变成了[1, 3, 4, 5], 但依然是原对象上进行的改变。
原位操作, 将数字进行原位操作之后, 这个数字就类似于列表这种,是在本身的内存当中改变的数,这时候就没有新对象建立出来。 a+=1就是一种原位操作。
a = torch.ones((1,))
print(id(a), a) # 1407221517192 tensor([1.])
# 我们执行普通的a = a+1操作
a = a + torch.ones((1,))
print(id(a), a) # 1407509388808 tensor([2.])
# 会发现上面这两个a并不是同一个内存空间
# 那么执行原位操作呢?
a = torch.ones((1,))
print(id(a), a) # 2112218352520 tensor([1.])
a += torch.ones((1,))
print(id(a), a) # 2112218352520 tensor([2.])
求取梯度的过程, 我们要求w的梯度的时候,也就是反向传播的时候可能会用到叶子节点, 这时候是怎么找到w的呢? 其实正向传播的时候,会把w的地址给记下来,然后反向传播的这一步,就是根据这个地址去找w的值。 如果在反向传播之前,就用原位操作把这个w的值给变了,那么反向传播再拿到这个w的值的时候,就出错了。
前面已经学习了数据的载体张量,学习了如何通过前向传播搭建计算图,同时通过计算图进行梯度的求解,有了数据,计算图和梯度,我们就可以正式的训练机器学习模型了。接下来,我们就玩一个逻辑回归模型吧。
逻辑回归模型
逻辑回归模型是线性的二分类模型,模型表达式如下:
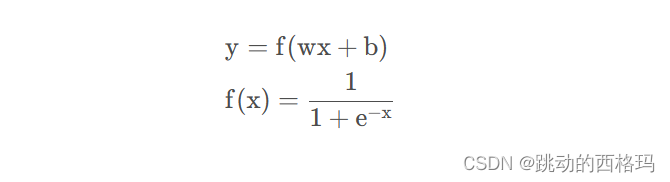
那为什么称为线性呢?我们可以对比一下线性回归和逻辑回归的区别:

图像也是一条直线。 是分析自变量x 与因变量y (概率)之间的关系。 这里注意不要只看到那个sigmoid函数就感觉逻辑回归是非线性的。因为这个sigmoid函数在这里只是为了更好的描述分类置信度。 如果我们不用这个函数,其实也是可以进行二分类的,比如w x + b > 0 , 我们判定为1, w x + b < 0 , 我们判定类别0, 这样其实也是可以的,就会发现,依然是一个w 只影响一个y , 决策边界是一条直线。所以依然是线性的(关于参数是线性的)。
线性和非线性模型的区别:
- 1、看决策边界,如果是线性模型,决策边界一定是一条直线。
- 2、看自变量前面参数w,如果自变量只受一个参数w影响,则模型为线性
下面训练一个逻辑回归模型,先说一下机器学习模型训练的步骤:
- 1、数据模块(数据采集,清洗,处理等)
- 2、建立模型(各种模型的建立)
- 3、损失函数的选择(根据不同的任务选择不同的损失函数),有了loss就可以求取梯度
- 4、得到梯度之后,我们会选择某种优化方式去进行优化
- 5、然后迭代训练
后面建立各种模型,都是基于这五大步骤进行, 这个就相当于一个逻辑框架了。下面就基于上面的五个步骤,看看Pytorch是如何建立一个逻辑回归模型,并完成分类任务的。
1、数据生成
这里我们使用随机生成的方式,生成2类样本(用0和1表示), 每一类样本100个, 每一个样本两个特征。
"""数据生成"""
torch.manual_seed(1)
sample_nums = 100
mean_value = 1.7
bias = 1
n_data = torch.ones(sample_nums, 2)
x0 = torch.normal(mean_value*n_data, 1) + bias # 类别0 数据shape=(100,2)
y0 = torch.zeros(sample_nums) # 类别0, 数据shape=(100, 1)
x1 = torch.normal(-mean_value*n_data, 1) + bias # 类别1, 数据shape=(100,2)
y1 = torch.ones(sample_nums) # 类别1 shape=(100, 1)
train_x = torch.cat([x0, x1], 0)
train_y = torch.cat([y0, y1], 0)
2、建立模型
这里我们使用两种方式建立我们的逻辑回归模型,一种是Pytorch的sequential方式,这种方式就是简单,易懂,就类似于搭积木一样,一层一层往上搭。 另一种方式是继承nn.Module这个类搭建模型,这种方式非常灵活,能够搭建各种复杂的网络
"""建立模型"""
class LR(torch.nn.Module):
def __init__(self):
super(LR, self).__init__()
self.features = torch.nn.Linear(2, 1) # Linear 是module的子类,是参数化module的一种,与其名称一样,表示着一种线性变换。输入2个节点,输出1个节点
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.features(x)
x = self.sigmoid(x)
return x
lr_net = LR() # 实例化逻辑回归模型
另外一种方式,Sequential的方法:
lr_net = torch.nn.Sequential(
torch.nn.Linear(2, 1),
torch.nn.Sigmoid()
)
3、选择损失函数
这里我们使用二分类交叉熵损失
"""选择损失函数"""
loss_fn = torch.nn.BCELoss()
4、选择优化器
这里用了SGD
"""选择优化器"""
lr = 0.01
optimizer = torch.optim.SGD(lr_net.parameters(), lr=lr, momentum=0.9)
5、迭代训练模型
这里就是我们的迭代训练过程了, 基本上也比较简单,在一个循环中反复训练,先前向传播,然后计算损失,然后反向传播, 更新参数,梯度清零。
"""模型训练"""
for iteration in range(1000):
# 前向传播
y_pred = lr_net(train_x)
# 计算loss
loss = loss_fn(y_pred.squeeze(), train_y)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 清空梯度
optimizer.zero_grad()
# 绘图
if iteration % 20 == 0:
mask = y_pred.ge(0.5).float().squeeze() # 以0.5为阈值进行分类
correct = (mask == train_y).sum() # 计算正确预测的样本个数
acc = correct.item() / train_y.size(0) # 计算分类准确率
w0, w1 = lr_net.features.weight[0]
w0, w1 = float(w0.item()), float(w1.item())
plot_b = float(lr_net.features.bias[0].item())
print('Loss=%.4f' % loss.data.numpy())
print("Iteration: {}\nw0:{:.2f} w1:{:.2f} b: {:.2f} accuracy:{:.2%}".format(iteration, w0, w1, plot_b, acc))
if acc > 0.99:
break
Loss=0.9221
Iteration: 0
w0:0.00 w1:0.19 b: 0.25 accuracy:35.00%
Loss=0.1936
Iteration: 20
w0:-0.79 w1:-0.61 b: 0.26 accuracy:94.00%
Loss=0.1440
Iteration: 40
w0:-1.05 w1:-0.91 b: 0.42 accuracy:94.00%
Loss=0.1245
Iteration: 60
w0:-1.12 w1:-1.01 b: 0.59 accuracy:95.50%
Loss=0.1111
Iteration: 80
w0:-1.15 w1:-1.08 b: 0.75 accuracy:96.50%
Loss=0.1009
Iteration: 100
w0:-1.17 w1:-1.13 b: 0.88 accuracy:97.50%
Loss=0.0928
Iteration: 120
w0:-1.19 w1:-1.17 b: 1.00 accuracy:98.00%
Loss=0.0862
Iteration: 140
w0:-1.21 w1:-1.22 b: 1.11 accuracy:98.00%
Loss=0.0808
Iteration: 160
w0:-1.23 w1:-1.25 b: 1.21 accuracy:98.00%
Loss=0.0762
Iteration: 180
w0:-1.24 w1:-1.29 b: 1.30 accuracy:98.00%
Loss=0.0723
Iteration: 200
w0:-1.26 w1:-1.32 b: 1.38 accuracy:98.00%
Loss=0.0690
Iteration: 220
w0:-1.27 w1:-1.35 b: 1.45 accuracy:98.00%
Loss=0.0660
Iteration: 240
w0:-1.29 w1:-1.38 b: 1.53 accuracy:98.00%
Loss=0.0634
Iteration: 260
w0:-1.30 w1:-1.41 b: 1.59 accuracy:98.00%
Loss=0.0612
Iteration: 280
w0:-1.32 w1:-1.43 b: 1.65 accuracy:98.00%
Loss=0.0591
Iteration: 300
w0:-1.33 w1:-1.46 b: 1.71 accuracy:98.00%
Loss=0.0573
Iteration: 320
w0:-1.35 w1:-1.48 b: 1.77 accuracy:98.00%
Loss=0.0556
Iteration: 340
w0:-1.36 w1:-1.50 b: 1.82 accuracy:99.00%
Loss=0.0541
Iteration: 360
w0:-1.37 w1:-1.53 b: 1.87 accuracy:99.00%
Loss=0.0527
Iteration: 380
w0:-1.38 w1:-1.55 b: 1.91 accuracy:99.00%
Loss=0.0514
Iteration: 400
w0:-1.40 w1:-1.57 b: 1.96 accuracy:99.00%
Loss=0.0502
Iteration: 420
w0:-1.41 w1:-1.59 b: 2.00 accuracy:99.00%
Loss=0.0491
Iteration: 440
w0:-1.42 w1:-1.61 b: 2.04 accuracy:99.00%
Loss=0.0481
Iteration: 460
w0:-1.43 w1:-1.63 b: 2.08 accuracy:99.00%
Loss=0.0472
Iteration: 480
w0:-1.45 w1:-1.65 b: 2.12 accuracy:99.00%
Loss=0.0463
Iteration: 500
w0:-1.46 w1:-1.66 b: 2.15 accuracy:99.00%
Loss=0.0455
Iteration: 520
w0:-1.47 w1:-1.68 b: 2.19 accuracy:99.00%
Loss=0.0447
Iteration: 540
w0:-1.48 w1:-1.70 b: 2.22 accuracy:99.50%
总结
总结一下,首先基于前面的张量的知识我们又更进一步,学习了计算图的机制,计算图就是描述运算过程的图, 有了这个图梯度求导的时候非常方便。 然后学习了Pytorch的自动求导机制,认识了两个比较常用的函数torch.autograd.backward()和torch.autograd.grad()函数, 关于自动求导要记得三个注意事项: 梯度手动清零,叶子节点不能原位操作,依赖于叶子节点的节点默认是求梯度。 最后我们根据上面的所学知识建立了一个逻辑回归模型实现了一个二分类的任务。
下一篇文章将学习pytorch的数据读取机制及相关知识。
参考:
[1]: http://meta.math.stackexchange.com/questions/5020/mathjax-basic-tutorial-and-quick-reference
[2]: https://mermaidjs.github.io/
[3]: https://zhongqiang.blog.csdn.net/article/details/105465136
[4]: http://adrai.github.io/flowchart.js/
[5]: https://zhongqiang.blog.csdn.net/article/details/105471435















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









