




NLP-Lecture 4 Part-Of-Speech Tagging
Learning Objective
- Part-of-Speech Tags
- Part-of-Speech Tagging
-
- Simple Statistic Models
-
- Sequence Labeling Models: Hidden Markov Model (HMM)
-
- Maximum Entropy Markov Model (MEMM)
-
- Conditional Random Fields (CRF)
Part-of-Speech Tagging
Introduction to Part-Of-Speech (POS) Tagging
- Part-of-Speech (for short POS) is the name for a group words, which have similar grammatical functions, such as noun, verb, pronoun, proposition, adverb, conjunction, participle and article.
-
- They are also known as syntactic classes(句法类别序列).
- A semantic class associates to the general meaning, such as human, animal and plant.
- Part-of-Speech tagging is a task of assigning a part-of-speech tag (like noun, verb, adjectives) to each word in a sentence. In such labelings, parts of speech are generally represented by placing the tag after each word, delimited by a slash.

-
Part-of-speech tagging is the process of assigning a part-of-speech marker to each word in an input text.3
The input to a tagging algorithm is a sequence of (tokenized) words and a tagset, and the output is a sequence of tags, one per token. -
Tagging is a disambiguation task; words are ambiguous—have more than one possible part-of-speech—and the goal is to find the correct tag for the situation. The goal of POS-tagging is to resolve these resolution ambiguities, choosing the proper tag for the context.
-
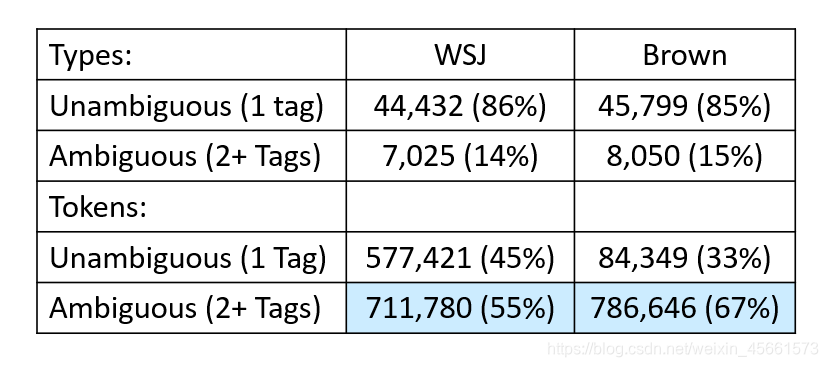
How common is tag ambiguity? Fig. 8.2 shows that most word types (85-86%) are unambiguous (Janet is always NNP, funniest JJS, and hesitantly RB). But the ambiguous words, though accounting for only 14-15% of the vocabulary, are very common words, and hence 55-67% of word tokens in running text are ambiguous. Some of the most ambiguous frequent words are that, back, down, put and set; here are some examples of the 6 different parts of speech for the word back:

-
POS Tagging is a disambiguation task, i.e., finding the correct tag for the word according to the context.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









