







索引:帮助MySQL高效获取数据的排好序的数据结构

例子:
找89
不带索引,全盘扫,需要去磁盘上找6次,6次io
带索引 2次io
索引的数据结构
二叉树 红黑树 hash表 b-Tree

如图是二叉树的数据结构(右边的元素比左边的元素大),当数据递增时,会退化成链表。

红黑树:平衡二叉树
缺点:数据量过大的时候,树的高度会很高,每一层高度都代表一次磁盘io
每一个节点都相当于在磁盘当中开辟了一块存储空间,为了层数少点,可以把磁盘上的存储空间开大点,一层上可以放更多索引,解决层树过高问题

优化B-树,在更小的高度,存放更多的数据,变种形成B+树,优化点:
所有的非叶子节点不存储data,只存储索引,可以放更多的索引;
叶子节点包含所有索引字段
叶子节点用指针来连接,提高区间访问的性能
磁盘io耗费的时间远大于在内存上定位数据


把节点(mysql默认16kb)加载到磁盘内存中,因为排好序了,做折半查找;
高度为3的B+树,存放2000万左右的元素(8b)
非叶子节点,启动mysql的时候,会被放到内存(RAM)当中
叶子节点放在磁盘当中
b+数数据之间有指针,针对范围查找更快速,b树还需要再次去根节点查询
mysql MylSAM存储引擎是表结构的

有三个文件 frm表结构 MYD(DATA)表数据 MYI(INDEX)表索引
索引文件和数据文件是分离的(非聚集)
select * from t where cloum='';
首先会判断cloum是不是索引,索引的话会在MYI(B+树)文件中查找对应的数据(数据的磁盘文件地址),到MYD中找到数据
InnoDB存储引擎

索引文件和数据文件是聚集的,FRM表结构 IBD索引文件+数据文件
相比较 MylSAM 查找到磁盘地址,需要再查data文件 需要回表
主键索引:data存储的是当前行的所有数据
二级索引:索引data存储的是当前数据所在行的主键,再去主键索引树中查找对应的数据
InnoDB表为什么必须建主键,并且推荐使用整型的自增主键
如果不建主键,mysql会找一列(数据都不相同)能够建唯一索引的记录,帮助建一个b+树的存储结构;
如果没有找到,mysql底层会维护一个隐藏列。类似rowid,形成b+树存储结构
因为mysql资源宝贵又有限,所以我们不能让mysql维护隐藏列,损耗性能,所以需要建主键
寻找数据的时候会比较大小,整型的 比较大小快,字符串比较大小要逐位比较,整型占用空间小,节约存储空间
自增:方便B+树 数据插入,减少分裂 旋转的情况,减少效率损失

O(1)级别 查找效率高,但是仅能满足 = 和 IN 不支持范围查询
hash冲突
索引最左前缀原理
联合索引
例如: idx (name age address)
从左到右依次判断排序
select * from user where name ='' and age = '';
select * from user where age = 30 and name='';
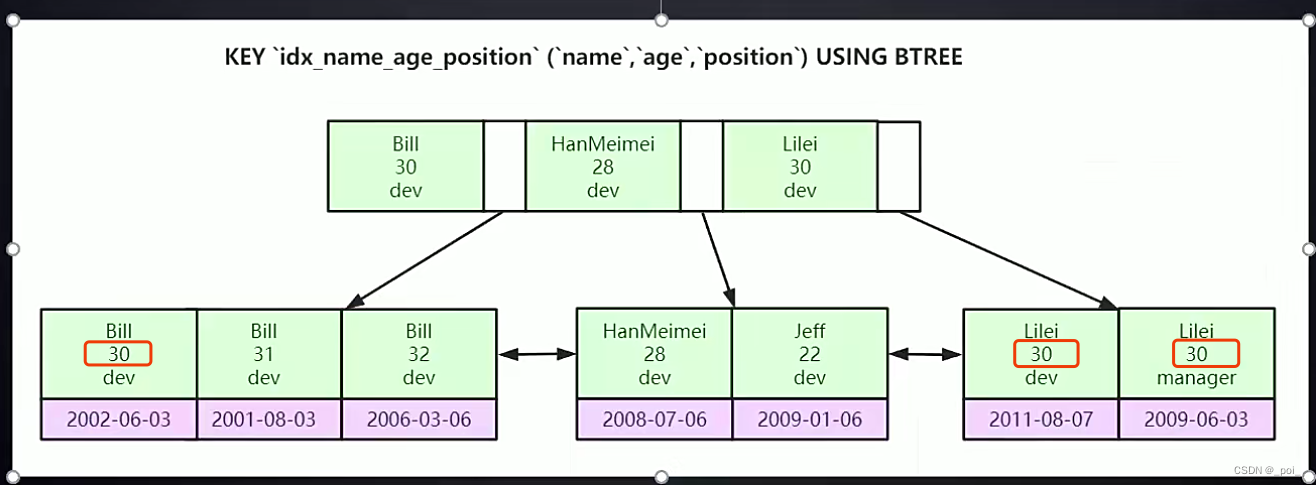
不走索引,age在b+树中可能不是顺序的,只能全表查询















 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









