









论文信息
论文题目
Deep Person Generation: A Survey from the Perspective of Face, Pose and Cloth Synthesis
作者
TONG SHA, Beihang University, China
WEI ZHANG, JD AI Research, China
TONG SHEN, JD AI Research, China
ZHOUJUN LI, Beihang University, China
TAO MEI, JD AI Research, China
录用期刊
ACM Computing Surveys, 2023
链接
https://arxiv.org/pdf/2109.02081
摘要
深度人物生成因其在虚拟代理、视频会议、在线购物和艺术/电影制作等领域的广泛应用而引起了广泛的研究关注。随着深度学习的推进,人物图像的视觉外观(面孔、姿势、布料)可以很容易地按需生成或操作。在本次调查中,我们首先总结了人物生成的范围,然后系统地回顾了深度人物生成的最新进展和技术趋势,包括三个主要任务:说话的头部生成(Face)、姿势引导的人物生成(Pose)和面向服装的人物生成(Cloth)。涵盖了两百多篇论文进行了全面的概述,并突出了里程碑式的工作,见证了重大的技术突破。基于这些基本任务,本文研究了虚拟试衣、数字人、生成式数据增强等若干应用。我们希望此次调查能够对深度人物生成的未来前景有所启发,并为数字人的全面应用提供有益的基础。
介绍
随着深度学习的推进,人们不再满足于对相机拍摄的照片/视频进行视觉理解。视觉内容生成作为另一个研究方向应运而生,因为图像和视频对于信息的呈现和交流非常有效。人物生成是指按需合成具有真实感的人物图像和视频。长期目标是生成具有与真人一样逼真的外貌、表情和行为的数字人类。作为一个新兴的领域,由于其在数字人、客户服务、临场感、艺术/服装设计和虚拟世界等领域有着广泛的应用,人物生成引起了大量的研究关注。
一般来说,合成一个人物图像或视频有3个关键组件(face, pose, cloth) ,如图1所示。人脸图像生成是最成熟的领域,多年来得到了广泛的研究。无条件人脸生成、人脸属性编辑和深度伪造在之前的论文[ 79、159、163]中已经得到了很好的综述。同时,具有易获取性工具 (如DeepFace Lab) ,伪造的面部视频也带来了严重的社会和伦理问题,比如深度伪造在总统选举中的威胁。近年来,由于视频会议、数字人等多种应用,说话人生成也引起了广泛关注。姿态引导的人物生成是另一个很好的探索任务,一个新的人物图像是在给定条件姿势的情况下生成的。该任务对于许多运动感知生成任务是必不可少的,例如舞蹈和运动合成。面向服装的生成对于虚拟试穿和其他服装操作任务,如文本引导的服装操作、服装修复等,具有重要意义。

图2显示了说话人头生成的文献图谱。沿着时间轴,近年来作品数量急剧增加。根据驱动信号,即音频或运动,有两个分支的技术被开发出来。对于这两个方向,2D生成的发展相对较早,因而得到了更多的研究关注。与此同时,基于3D的方法作为一种重要的补充,近年来也得到了广泛的研究。更多的细节将在第二节中介绍。

对于姿势和服装生成,技术路线大致遵循类似的模式。图3为现有文献的概况。总体而言,可以清晰地识别出以下观察结果。 (1) 作品数量随年代迅速激增(见时间轴)。 (2) 一般而言,自下而上的方法比自上而下的方法更受青睐。 (3) 无论是面向姿态生成还是面向服装生成,其趋势都是先从自上而下到自下而上,再到混合方法。 (4) 最流行的位姿变换方法和服装变换方法分别是变形法和对布法。详细内容在第3节(姿势)和第4节(服装)中讨论。

说话人生成
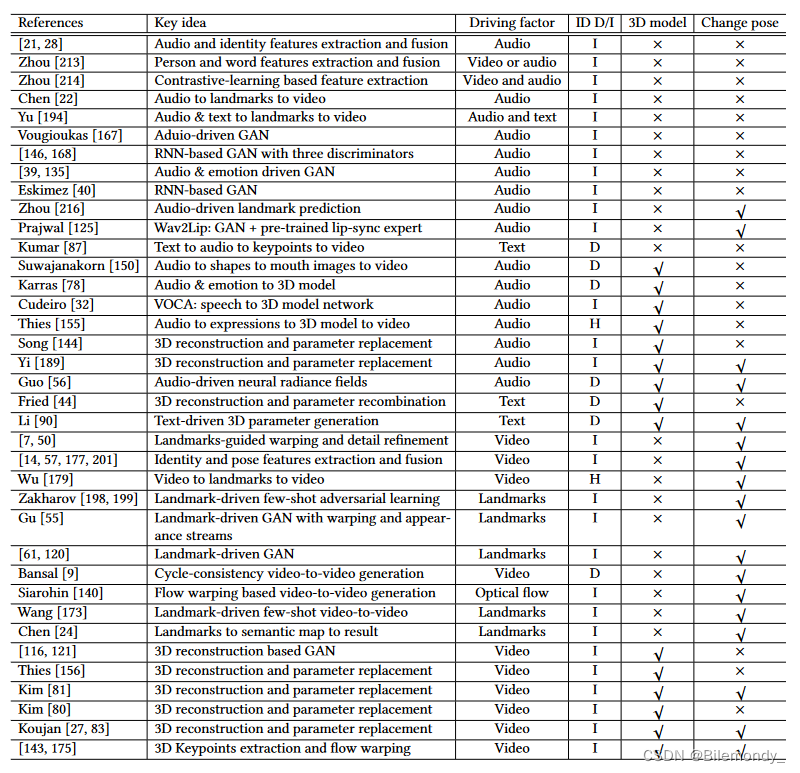
说话人生成旨在合成一个人说话的视频,由一段音频或运动序列驱动。该任务对于包括视频会议、虚拟锚点和客户服务在内的许多应用至关重要。如图4所示,根据驱动信号的不同,这些方法一般可以分为音频驱动和运动驱动两大类。值得注意的是,“文本驱动” (文像转换) 的生成是"音频驱动" (语音到视频) 的自然延伸,因为唯一的区别是成熟的文本到语音技术。例如,Kumar等人[87]使用Char2Wav将文本输入转换为音频。Fried等[ 44 ]将音素与3DMM [ 11 ]参数对齐,从输入文本中生成音频。因此在本文中,我们考虑将文本驱动分支作为音频驱动问题的一个变体。表1.(1)总结了关于说话人头生成的代表作品。
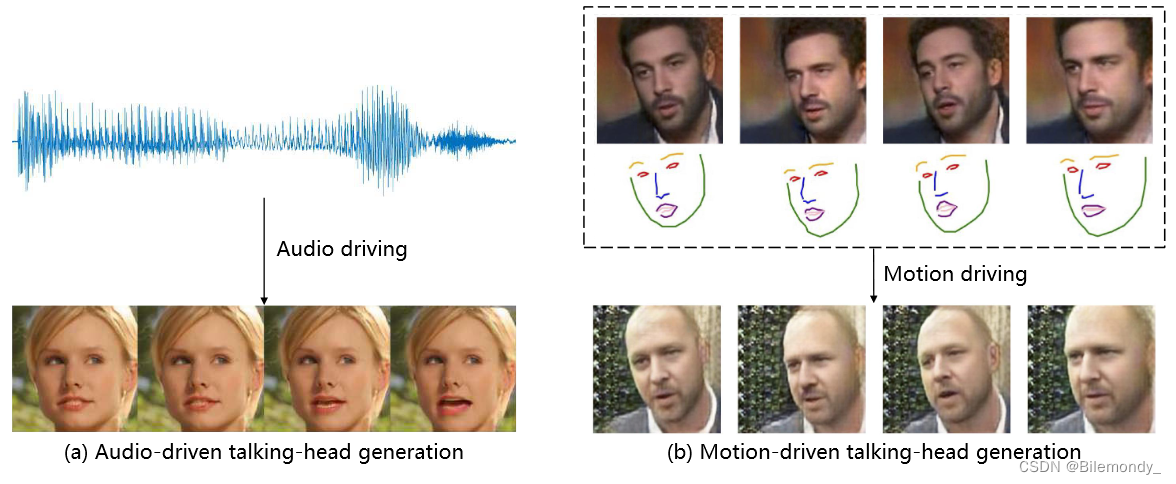
音频驱动的说话人头生成
音频驱动的说话头生成是由一段音频(例如,演讲、歌唱音频等)驱动合成一个逼真的动画视频。近年来,该地区一直受到广泛的研究关注。从技术上讲,可以确定两条研究路线:基于2D的[ 13、18、21、22、28、39、40、87、96、125、135、146、167、168、194、213、214、216]和基于3D的方法[ 32、44、56、78、90、144、150、155、189] ,这取决于它们的头部模型的内部表示。
2D方法
2D方法在合成时大多采用坐标、语义图或其他类似图像的表示,最早可追溯到布雷格勒等人1997年[ 13] 。早期的工作[ 13,18,96]集中于传统的机器学习,由于硬件和数据收集的限制,其结果比较初步。自2017年以来,基于GAN的方法因其优越的视觉质量逐渐流行起来。
许多作品尝试生成任意人物身份的视频(与身份无关)。Chung等人[28]通过将音频和身份特征与两个编码器分离,提出了一种与身份无关的架构。此后,许多与身份无关的方法被开发出来[ 21、22、39、40、125、135、146、167、168、194、213、214、216] 。Chen等[ 22 ]和Yu等[ 194 ]使用面部特征点作为内部表示来桥接音频和面部图像。Song等人[ 146 ]和Vougioukas等人[ 168 ]都提出了多重判别器:帧(图像级保真度)、序列(视频级保真度)和同步(唇读)判别器,以提高视频生成中的视觉质量和时间相干性。萨杜吉等人[ 135 ]和埃斯基梅兹等人[ 39 ]引入情感作为不同面部表情的另一种条件输入。Zhou等人[ 216 ]进一步应用说话人感知的动画模型来预测伴随音频的自发头部姿态。Prajwal等人[ 125 ]通过引入预训练的SyncNet作为唇同步判别器,显著改善了唇同步。
3D方法
与2D分支不同,3D方法主要基于3D人脸建模。Vlasic等人[ 165 ]和加里多等人[ 46 ]基于3D人脸模型使用Dubber视频指导唇动。Thies等人[ 157、158]采用视频人脸跟踪提取三维人脸模型,然后应用表情迁移进行唇动生成。值得注意的是,Face2Face [ 158 ]后来成为许多后续3D方法的原型。
最近的工作[ 27、80、81、83、116、121、156]大多基于单目三维重建,遵循类似的模式[ 158 ]。首先,采用单目三维重建获取源视频和驾驶视频的人脸模型。然后,将这两个3D模型进行组合,生成目标3D模型。最后,应用视频渲染模块进行视频生成。Kim等人[ 81 ]针对完全可控的人脸修改姿态、表情和眼睛参数,或者只修改表情参数来保持风格[ 80 ]。类似地,Koujan等人[ 27、83]保留了源视频的尺度参数,以保证生成的人脸大小合适。与之不同的是,Wang等人[ 175 ]提出从视频中提取三维特征点,而不是使用三维重建。此外,Song等人[ 143 ]使用从谈话视频帧中提取的控制点对虚幻的人脸进行动画。
讨论
面部表情在近期的谈话头作品中变得至关重要。早期的方法只对嘴巴区域进行生成和修改,导致活泼性有限。最近的方法[ 39,216]开始探索丰富的情感和自发的头部运动。在不久的将来,修饰微表情可能会出现。
与运动驱动的任务相比,音频驱动的任务由于较大的领域间隙和非确定性映射,显然更具挑战性。在音频、文本和视频等不同形式的数据之间建立跨模态连接具有先天的困难。此外,相同的输入音频可能被解释为不同的头部动作和面部表情。此外,人眼对帧中的视觉伪影和视频中的时间抖动高度敏感,使得这一问题更加具有挑战性。
无论是音频驱动还是运动驱动的说话人生成,现在都倾向于结合2D和3D技术的解决方案。总的来说,基于GAN的2D解决方案给出了更直观的结果,但3D解决方案在运动控制方面表现更好。此外,单目三维重建的最新进展也为三维模型的生成提供了便利。就效果而言,这一任务还远未成熟。例如,生成具有微表情的高分辨率视频仍然是当前方法面临的主要挑战。
姿态引导的人的生成
姿态引导的人物生成旨在生成由目标姿态引导的全身照片真实感人物图像或视频,如图5所示。与谈话头的根本区别在于对身体姿势和动作的强调。该任务在电影制作、网络时尚购物等方面有很多潜在的应用。我们主要关注两个主要分支:姿态引导的人物图像和视频生成。
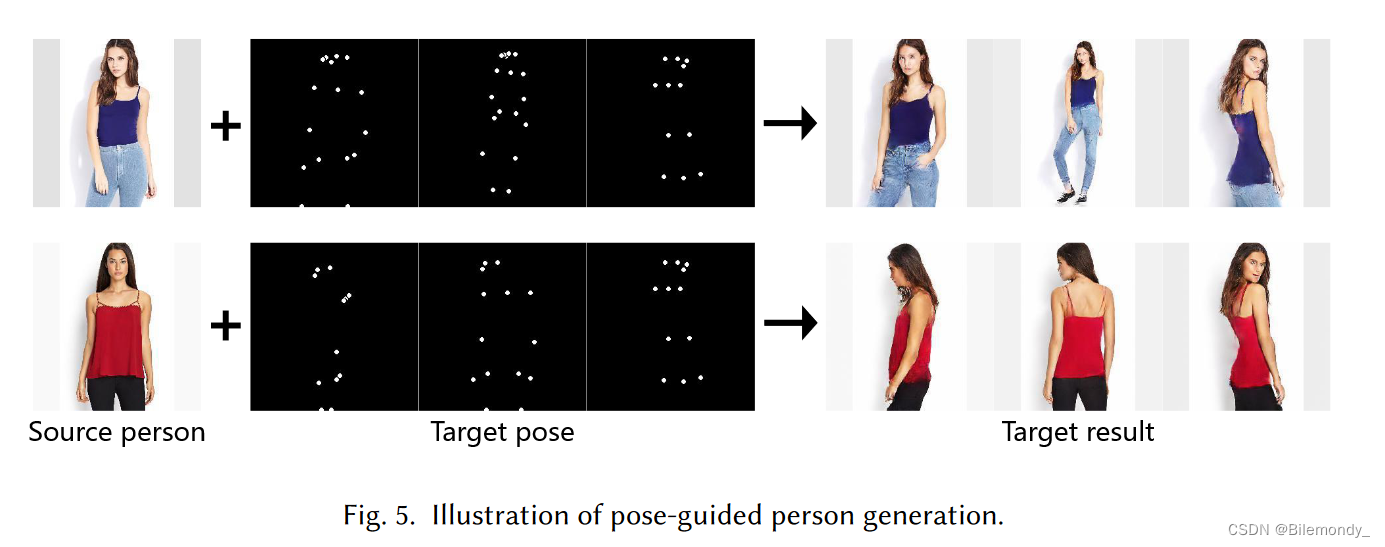
姿态引导的人物图像生成
姿态引导的人物图像生成旨在根据给定的目标姿态对源人物图像进行变换。主要的挑战在于源和目标姿态之间的不对准。
关于姿态引导的行人图像生成的总结如表2所示,现有的方法大致可以分为三类:自顶向下的[ 77、94、99、101、108、126、137、138、145、153]、自底向上的[ 8 , 19 , 23 , 33 , 35 , 38 , 41 , 54 , 58 , 91 , 92 , 100 , 103 , 109 , 132 , 141 , 148 , 152 , 178 , 207 , 208 , 220]和混合[ 119、182、186、187]方法。具体来说,自顶向下的方法直接学习从输入到期望输出图像的映射,大多使用类似GAN的网络。自底向上的方法将整个管道分解成若干个中间组件并构建最终结果循序渐进。混合方法利用了这两方面的优势。作为概述,图6展示了每个类别的代表性作品,图7比较了主要的网络结构。
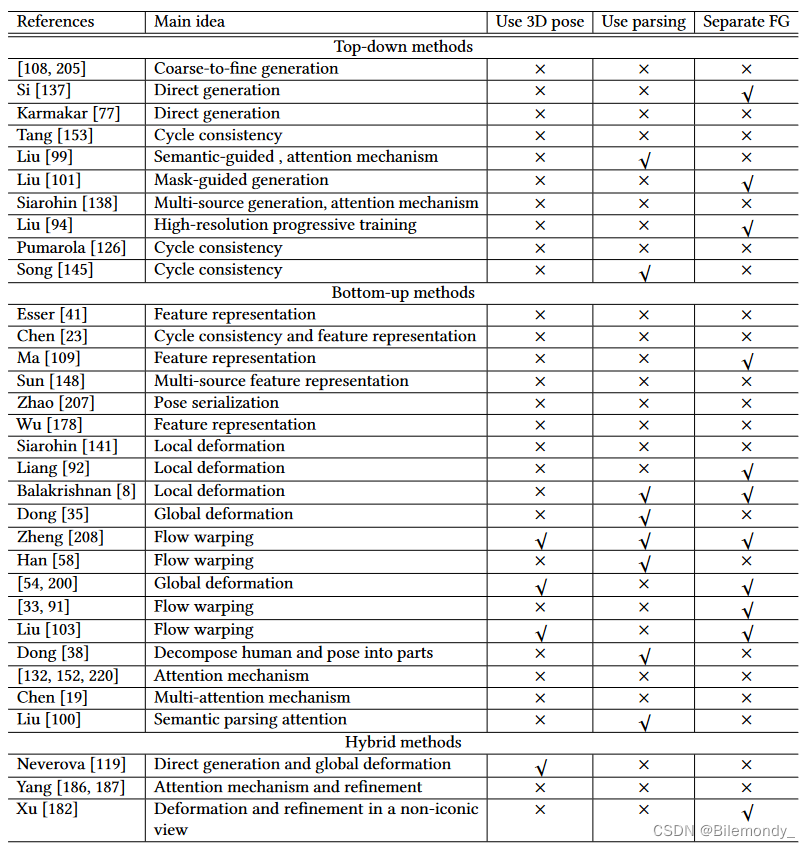
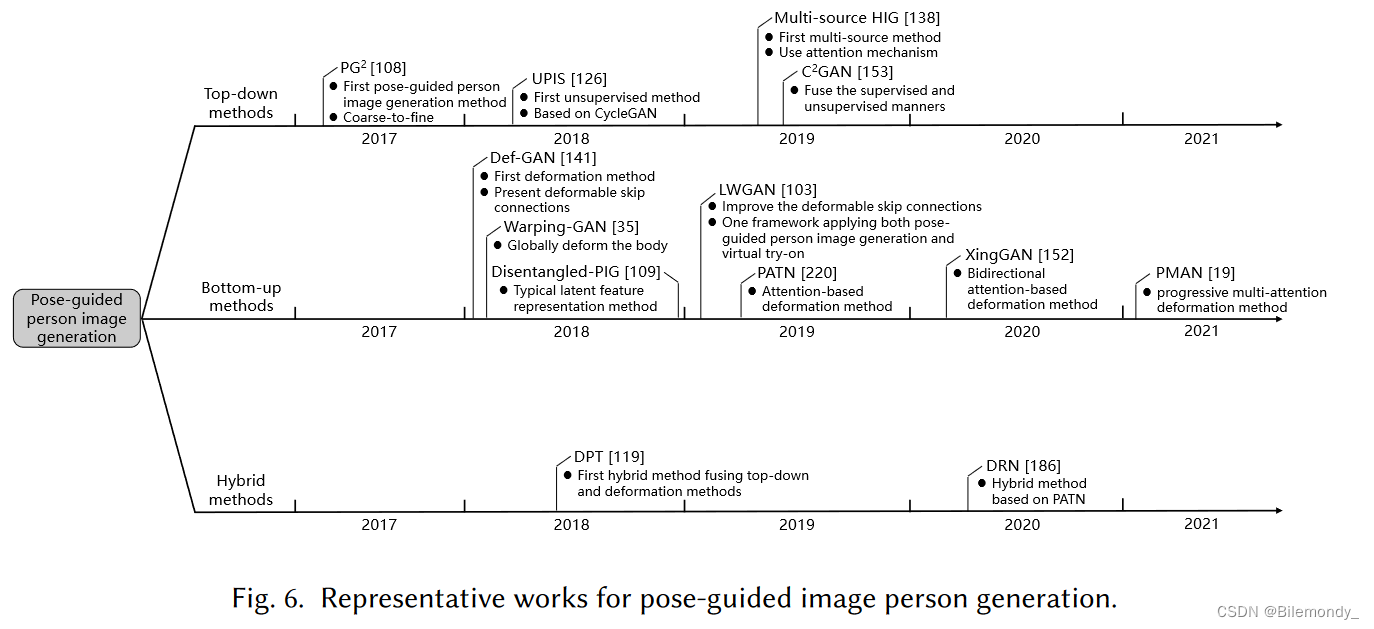
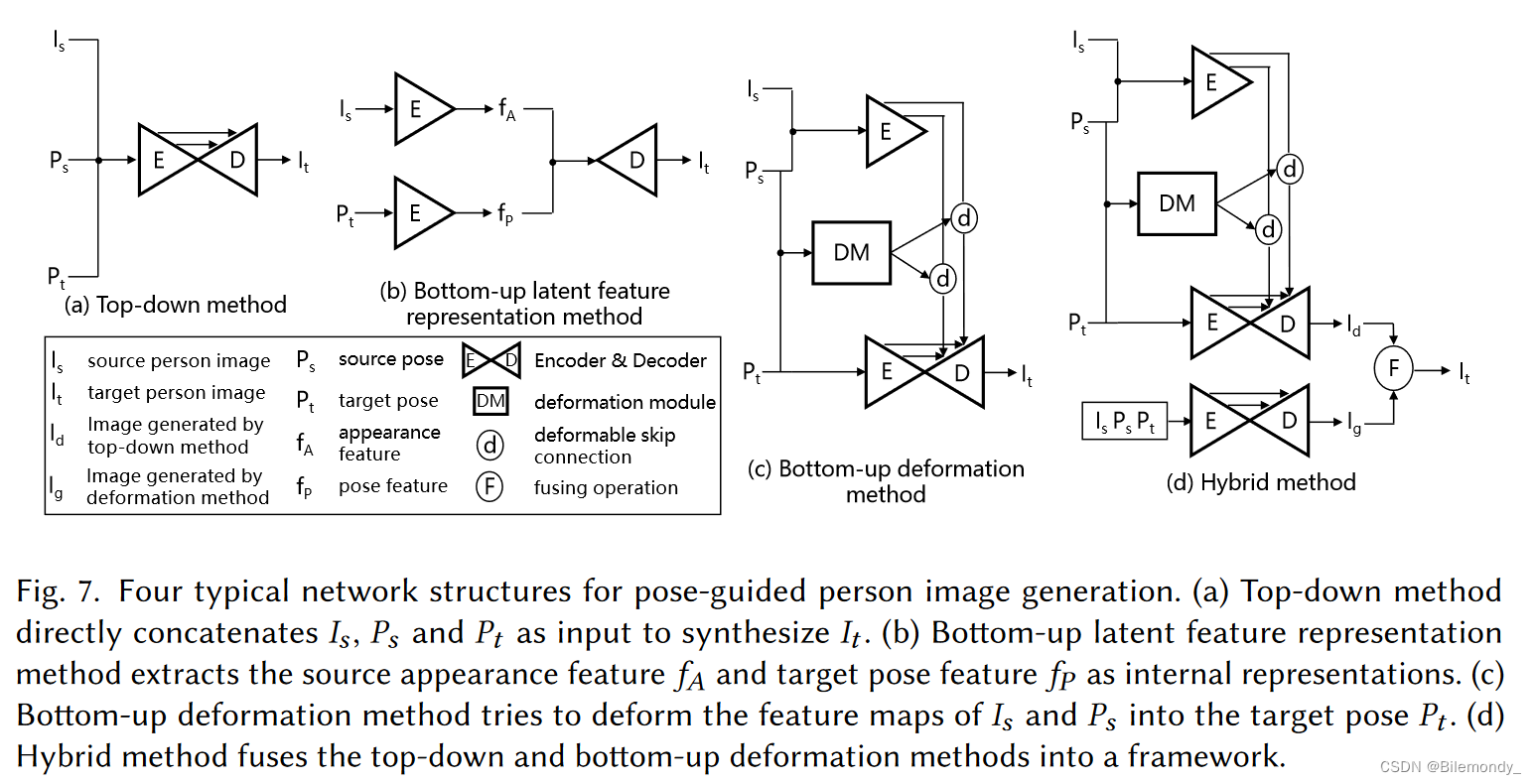
自上而下方法
受基于GAN的视图合成[ 205 ]的启发,Ma等[ 108 ]将条件GAN [ 115 ]应用于姿态引导的人物生成,提出了开创性的自顶向下解决方案PG2。PG2直接将源图像、源和目标姿态作为输入进行拼接合成目标图像,再加上一个细化模型来改善生成细节。
为了获得更好的性能,随后提出了一些改进,包括数据增强[ 77 ]和更多的信息输入[ 99、101]。具体来说,Liu等人[ 99、101]用分割掩模和解析图代替姿态来指导图像生成。一些研究者关注其他衍生任务。Siarohin等[ 138 ]提出了一种多源方法,采用注意力机制为不同源图像分配权重。Liu等[ 94 ]提出了一种高分辨率的( 1024 × 1024)方法来保持更多的细节。除了上述有监督的分支外,其他工作探索了无监督的设置。Pumarola等[ 126 ]介绍了一种类似于CycleGAN [ 218 ]的无监督方法。Song等[ 145 ]对语义地图进行操作,绕过了配对数据的要求。Tang等[ 153 ]引入多个循环损失,即1 × image→image→image cycle and 2 × pose→image→pose cycles,以引入更多的自我监督。
自下而上的方法
自下而上的方法倾向于将整个过程分解为组件或步骤,其中的中间结果通常是生成所必需的。一般而言,这些方法可以归为两类:潜在特征表示方法[ 23、41、109、148、178、207]和变形方法[ 8、19、33、35、38、54、58、91、92、100、103、132、141、152、208、220]。
潜在特征表示方法从源图像和目标姿态中提取潜在特征作为中间结果,控制生成结果。[ 23、41]的一种典型方式是通过VAE从源图像中提取外观特征[ 82 ]。Chen等[ 23 ]使用循环一致性[ 218 ]来支持未配对的训练数据。Zhao等[ 207 ]从插值的位姿序列中提取位姿特征,从源位姿到目标位姿。Sun等[ 148 ]通过双向卷积LSTM从一组源图像中提取外观特征。
变形方法是另一条研究路线。自顶向下和潜在特征表示方法在源和目标姿态差异较大的情况下通常表现出较差的结果。变形方法通过将源人物图像的特征图转换为目标姿态来解决上述不足。这些方法在保留纹理细节方面效果较好。
第一种变形方法可以追溯到可变形GAN ( Deformable GAN,Def-GAN )。受空间变换网络[ 73 ]的启发,Siarohin等[ 141 ]提出在特征图层面对近刚体部件进行局部变形。提出了一种新的可变形跳线连接来代替标准跳线操作,其中变形特征和目标位姿被串接作为综合输入。
其他局部变形方法[ 8、92、103]相对于可变形跳跃连接有所改进。Liu等人[ 103 ]应用了一个液体翘曲块( Liquid Warping Block,LWB ),其中源和目标姿态之间的变换流被用来变形特征图,用于姿态引导生成和虚拟试戴。此外,少数方法选择不在输入端显式变形车身部件,而是在生成过程中采用编码器-解码器结构隐式变形。Dong等[ 38 ]引入了部分保持GAN ( PP-GAN ),直接将分解后的车身部件作为输入,隐式地进行变形,具有解析一致性损失。
最近,一些工作[ 19、100、132、152、220]进一步引入了局部形变的注意力机制。Zhu等人[ 220 ]提出了姿态注意力迁移网络( PATN ),根据姿态为不同的图像块分配权重。Ren等人[ 132 ]对从源图像中提取的特征图生成流场来计算局部注意力,从而可以对空间变换进行局部操作。Tang等[ 152 ]设计了一个新颖的基于注意力的网络Xing GAN,包括两个分支:形状引导的基于外观的生成( SA )和基于外观引导的形状生成( AS )。引入了一种新颖的交叉连接来捕获图像和姿态模态之间的联合注意力。
同时,其他一些工作[ 33、35、54、58、91、200、208]采用全局变形将人体作为一个整体进行变形。Dong等[ 35 ]提出了一种软选通翘曲块来预测解析图之间的转换网格。[ 33、58、91、208]的多篇著作对外观进行了估计
混合方法
自顶向下方法较好地保留了整体外观,但没有保留局部纹理,尤其是源姿态与目标姿态之间存在较大差距。自底向上的方法可以很好地处理大间隙,但在处理遮挡时存在困难。因此,对混合框架进行了探索,以期从两方面发挥优势。
Neverova等[ 119 ]提出了第一种混合方法- -密集位姿传递( Dense Pose Transfer,DPT ),将自顶向下的结果和形变输出进行融合,用于生成目标图像。Yang等人[ 186、187]将PATN [ 220 ]与图像细化[ 108 ]相结合,并应用交替更新策略,以促进两个模块之间的相互指导,以获得更好的外观和形状一致性。Xu等人[ 182 ]提出MR - Net来合成具有扭曲姿态和杂乱场景的行人图像。
姿态引导的人物视频生成
通过进一步考虑生成视频中的时间相干性,将姿态引导生成从图像扩展到视频域是很自然的。与图像生成类似,我们将相关工作分为两个分支:自顶向下的[ 164、169、183、184、206]和自底向上的方法[ 17、98、131、139、140、149、173、174、193、197、217]。
自上而下方法
自顶向下的方法通过基于GAN的网络直接将目标姿态序列映射到人物视频。目标位姿序列要么是给定的[ 183 ],要么是由另一个网络[ 164、169、184、206]预测的。Yang等[ 184 ]通过Pose Sequence GAN ( PSGAN )预测位姿序列。Walker等人[ 169 ]将VAE [ 82 ]与LSTM结合来学习未来姿势的分布。同时,引入姿态流以提高时间相干性。此外,维莱加斯等人[ 164 ]提出了一种类比生成方法来合成未来帧。Zhao等[ 206 ]在[ 164 ]的基础上改进了运动细化网络,以获得更好的时间相干性。
自下而上方法
为了保留更多的时间一致性,探索了自下而上的方法,在视频生成过程中注入更多的结构化信息。Wang等[ 174 ]提出了第一种双向可视化合成方法,采用光流来提高时间相干性。Chan等人[ 17 ]介绍了一种典型的姿态引导视频生成方法,用于从另一个视频中传输身体动作。为了保持时间相干性,采用了一序列帧而不是单幅图像。Liu等[ 98 ]在三维模型上进行了较好的位姿传递。
上述方法[ 17,98,174]在身份依赖性方面存在局限性。也就是说,当应用于一个新的人时,必须重新训练模型。一些研究者尝试设计与身份无关的方法[ 131、139、140、149、173、188、193、197、217]。Siarohin等人[ 139、140]加入源图像作为输入,生成针对不同身份的视频。此外,源和驱动帧之间的光流被估计以保持时间相干性。Wang等人[ 173 ]也加入了识别图像作为额外的输入来控制生成视频的外观。Zhou等[ 217 ]提出了一种与身份无关的方法,将身体部位变形为目标位姿。Ren等[ 131 ]对图像生成网络[ 132 ]进行改造以合成连续帧,并引入运动提取网络以提高时间一致性。Yoon等[ 193 ]利用3D人体模型以时间一致的方式传递姿态,可应用于野外图像。
讨论
由于人体姿态的多样性和复杂性,基于姿态引导的人体生成具有挑战性。对于源姿态和目标姿态之间的较大差距,看不见的区域是极难合成的。自顶向下的方法采用基于GAN的网络对未见区域产生幻觉,但牺牲了纹理细节。自底向上的方法将源图像变形为目标姿态,更好地保留了纹理细节,但对遮挡区域敏感。
到目前为止,大多数姿态引导的生成方法属于自底向上的分支,而自顶向下的方法在视觉质量方面也在快速发展。三维姿态估计、人体解析和注意力机制等多项基础技术在进一步改善纹理细节方面表现出了巨大的潜力。然而,姿势之间的巨大差异,例如前后姿势,目前仍然难以处理。该混合方法在解决遮挡和纹理细节的困难方面具有更多的潜力。
服装引导的人物生成
面向服装的生成专注于生成人物形象的新服装,在时尚领域有着广泛的应用。在本节中,我们重点研究了两个主流任务:虚拟试穿和服装编辑。
虚拟试衣
虚拟试穿,如图8所示,是将特定的服装转移到一个人的形象上,这使得顾客在网上购物之前可以对服装进行虚拟试穿。早期的方法侧重于三维人体和服装的重建,大多是通过人工建模。这些方法过程复杂,其结果(风格倾向于电子游戏)视觉真实感较差。自2017年起,GAN - like方法作为3D解决方案的补充开始出现。作为对比,2D方法具有更简单的结构和更真实的结果。

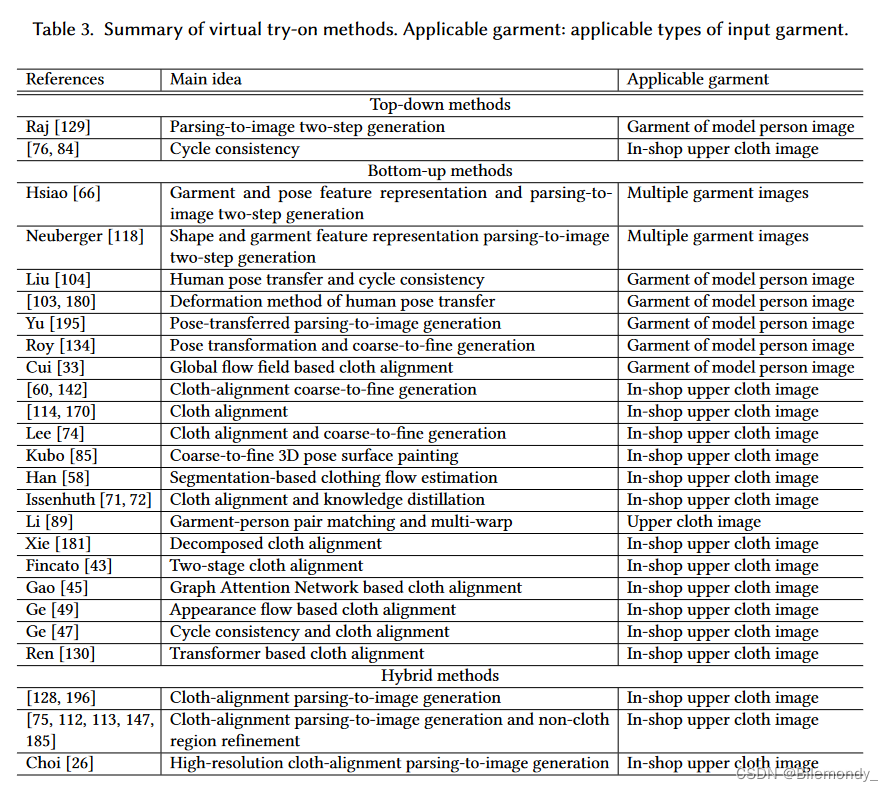
相关工作的简要总结如表3所示。基于深度学习的虚拟试穿也可以分为三类:自顶向下的[ 76、84、129]、自底向上的[ 33、43、45、47、49、58、60、66、71、72、74、85、89、103、104、118、130、134、142、170、180、181、195、200]和混合的[ 26、75、112、113、128、147、185、196]方法。图9展示了代表性方法,图10突出了3个分支之间的差异。
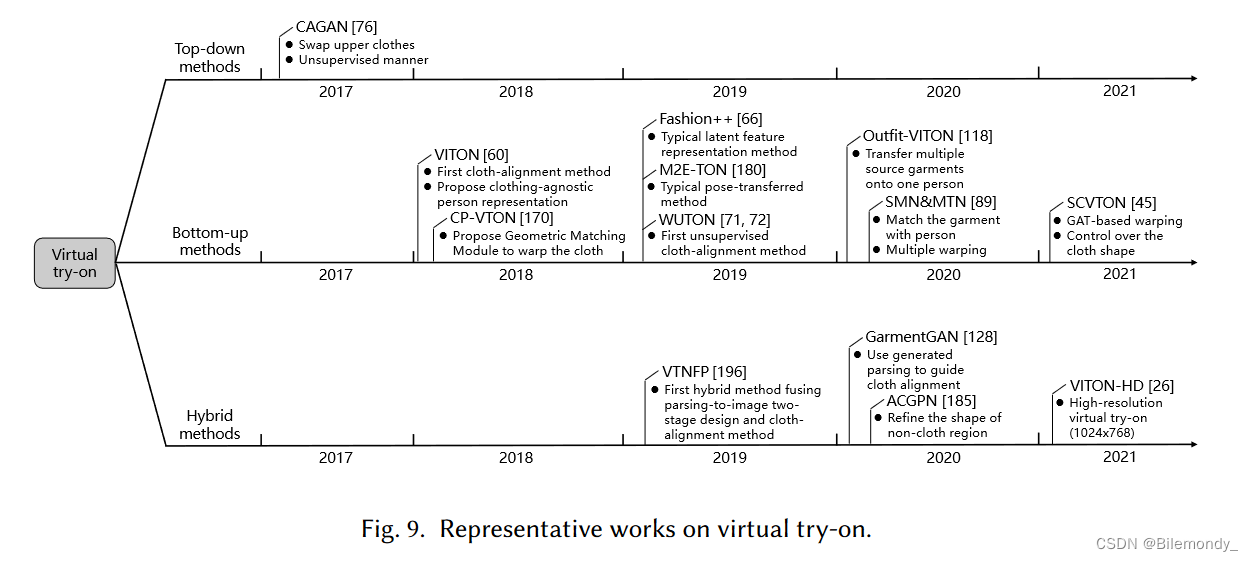
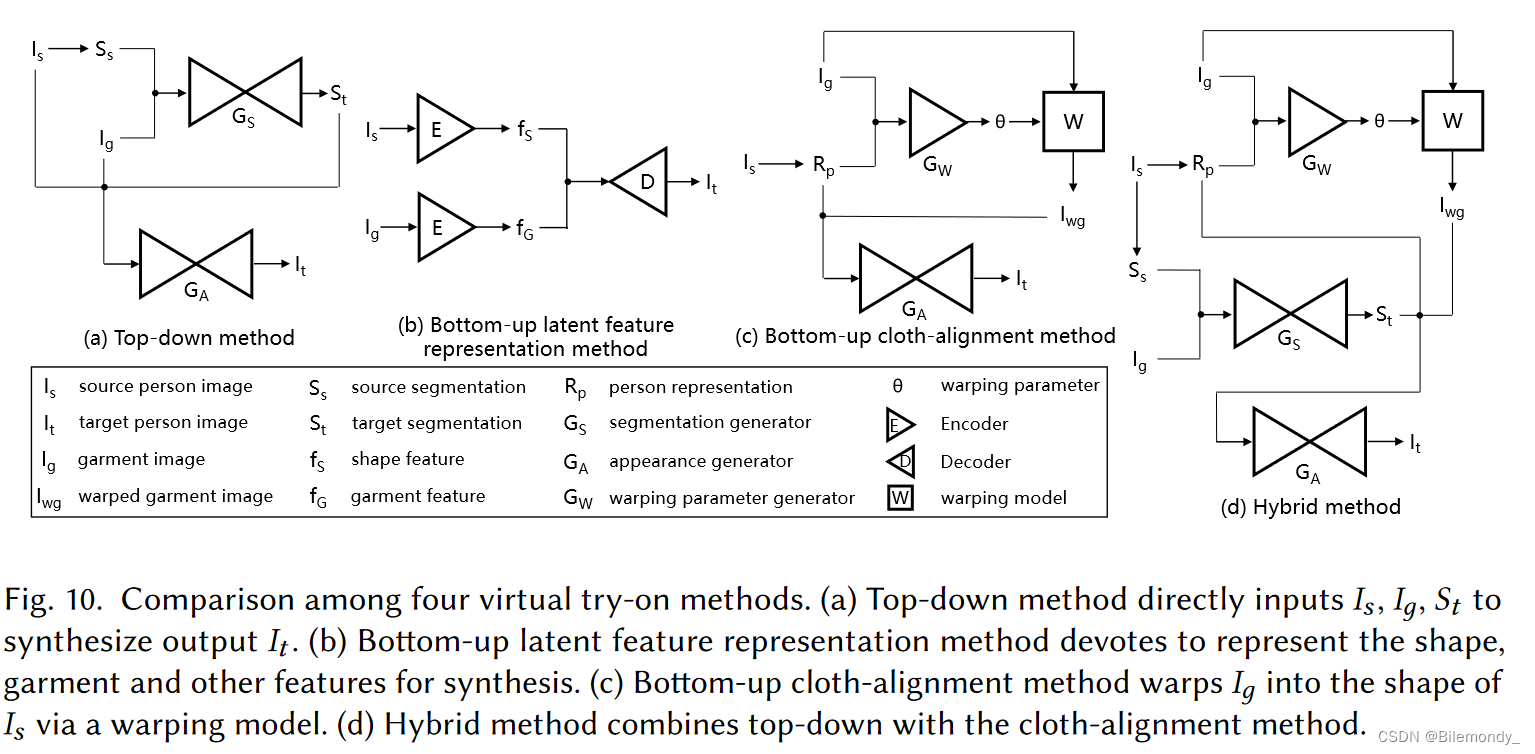
服装操纵
除了虚拟试穿外,服装操作还有服装合成、文本引导的服装操作和服装修复等任务。服装合成通过新的服装生成人物图像。**ClothNet [ 88 ]通过图像到图像的转换从草图生成真实感服装图像[ 70] 。**文本引导的服装操作是指在文本的引导下对服装进行修改。**Zhu等[ 219]提出FashionGAN根据文字描述生成服装。**服装修复使用油画磨损的修色方法添加服装纹理。Han等人[ 59 ]提出了FiNet来修复缺失的服装,如上/下衣服,鞋子。
讨论
虚拟试穿具有挑战性,主要有两个原因。
**第一个问题来自于人类姿势的多样性,以及服装与姿势的不匹配。**自顶向下的方法可以在较宽的姿态范围内生成逼真的结果,但不能很好地保留纹理细节。潜在特征表示方法支持多服装虚拟试穿,但难以保留足够的布料纹理。布料对齐方法保留了大部分的布料纹理,但难以处理衣服与姿态之间的较大失配。
**第二个问题是缺乏合适的数据集进行全监督训练。**在虚拟试穿的场景中,配对数据是很难收集的。但是,有监督数据中的障碍导致了[ 71,76,118]等无监督方法的出现。
到目前为止,自下而上的方法更受欢迎。由于在保留纹理细节方面的优势,布料对齐方法发展迅速。为了提高生成质量,人们探索了多种变形方法,包括TPS [ 12 ]、Cloth Flow [ 58 ]、decomposed warping[ 181 ]等。此外,近年来试穿服装的种类也越来越多。早期作品仅支持上衣。最近的作品[ 66、118]开始尝试服装,包括上衣、裤子、裙子、帽子等。然而,目前的方法在野外数据集和多服装上不能很好地工作。
基准
在本节中,我们首先回顾了数据集和评估指标,然后在适用的情况下对最近的性能进行了基准测试。
数据集
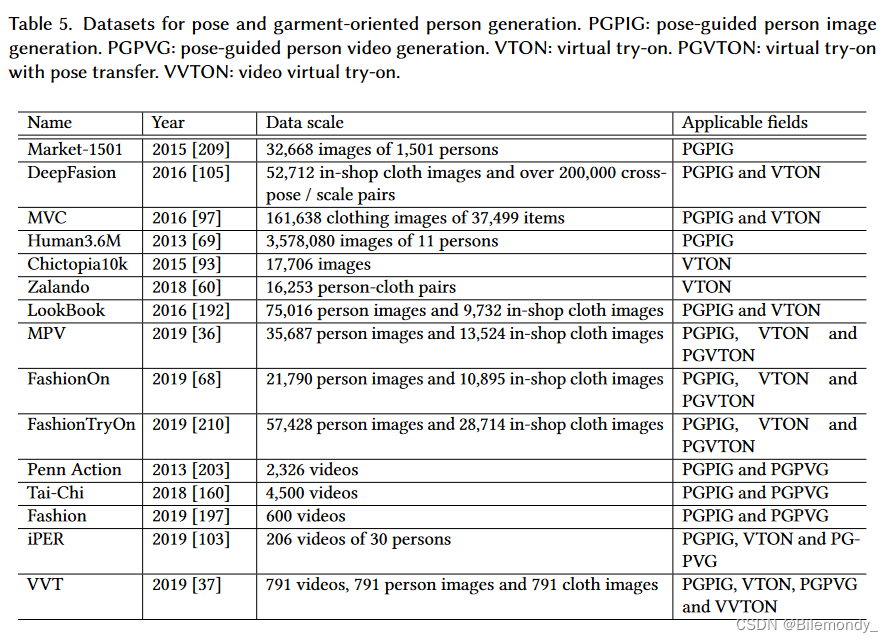
常用的说话人生成数据集详细信息如表4所示。面向姿态和服装的生成如表5所示。在此,我们仅简要介绍大多数研究者采用的数据集。
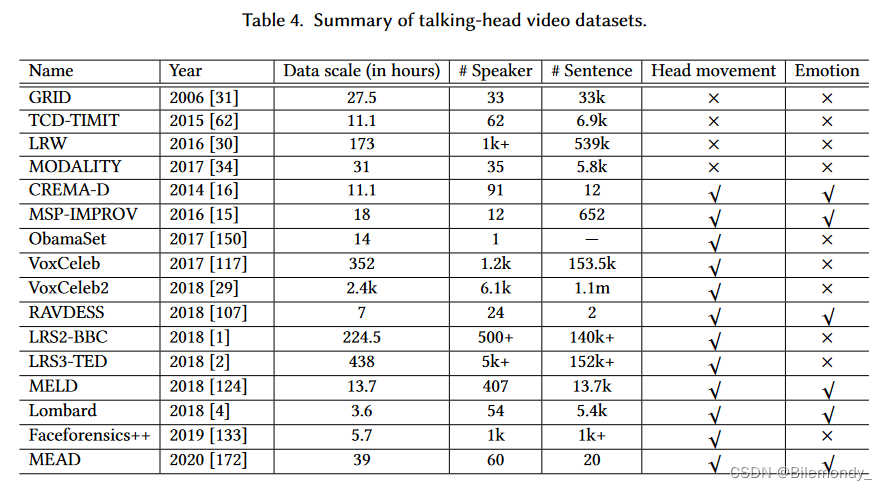
对于说话人生成,采用GRID [ 31 ]和LRW [ 30 ]对无头部运动的方法进行评估;CREMA-D [ 16 ]在具有自发运动的视频上进行了验证;Voxceleb2 [ 29 ]和LRS3-TED [ 2 ]关注于野外视频。另外,Chen等人[ 20 ]也提出了几种评估会话头生成的评估方案。
对于姿态引导的人物图像生成,最常用的数据集是Market - 1501 [ 209 ]和DeepFasion [ 105] 。对于基于服装的生成,Zalando [ 60 ]和Deepfasion [ 105]数据集很热门。最近,MPV [ 36 ]数据集也被用来评估基于服装和姿势的生成。
评价指标
评估生成任务是众所周知的困难。作为一种常见的做法,采用多个客观( e.g. , Inception Score , SSIM)和主观(例如,Amazon Mechanical Turk, User study)指标进行综合评估。主观评价涉及人在回路,常用于比较生成内容的感知视觉质量。然而,由于评价过程中的主观因素和较高的成本,大多数工作也寻求用客观的指标进行定量评价。对于人物生成,常见的客观度量指标总结如下。
SSIM
结构相似度( Structural Similarity,SSIM ) [ 176 ]衡量生成图像与原始图像相比的质量,在图像合成中应用广泛。具体来说,SSIM计算合成图像与真实图像在亮度、对比度和结构三个维度上的相似度。
IS
IS ( Inception Score ) [ 136 ]从对象清晰和多样性高两个方面评价生成图像的质量。IS通过预训练的Inception v3 [ 151 ]网络计算生成图像的分布。这个度量并没有那么丰富,巴拉特和Sharma [ 10 ]提出了IS的一些缺点。
FID
FID (弗雷谢起始距离) [ 64 ]通过计算生成图像和真实图像的分布之间的Fréchet距离来捕捉它们的相似性。
FReID
FReID使用预训练的行人重识别模型来估计生成图像和真实图像的高斯分布,并计算这些分布的Fréchet距离。
LPIPS
LPIPS (学习了感知图像块相似性) [ 202 ]使用预训练的深度网络学习图像块的深度感知特征,然后计算两幅图像特征之间的平均l2距离。
DS
DS ( Detection Score )通过计算生成图像上的人-类别平均检测分数来衡量预训练的行人检测器在生成的行人图像中的置信度。
AttrRec-k
AttrRec-k (Top - k服装属性保留率) 使用预训练的服装属性识别模型从生成的图像中预测服装属性。它使用top - k召回率作为最终得分。
性能比较
谈话头视频生成大多通过用户研究进行评估。最近,Chen等人[ 20 ]从身份保持、嘴唇同步、视频质量和自发头部运动等方面提出了一些客观的指标来评估说话头部视频。同时,他们提出了一个具有标准化数据集预处理策略的新基准来评估说话人生成方法。
对于姿态引导的人物生成和虚拟试穿,SSIM [ 176 ]、IS [ 136 ]及其变体得到了广泛的应用。但是这些度量指标都不是完美的[ 10、202]。人们逐渐转向FID [ 64 ]和LPIPS [ 202 ]进行评价。尤其是用户研究在虚拟试穿中的应用更为广泛。
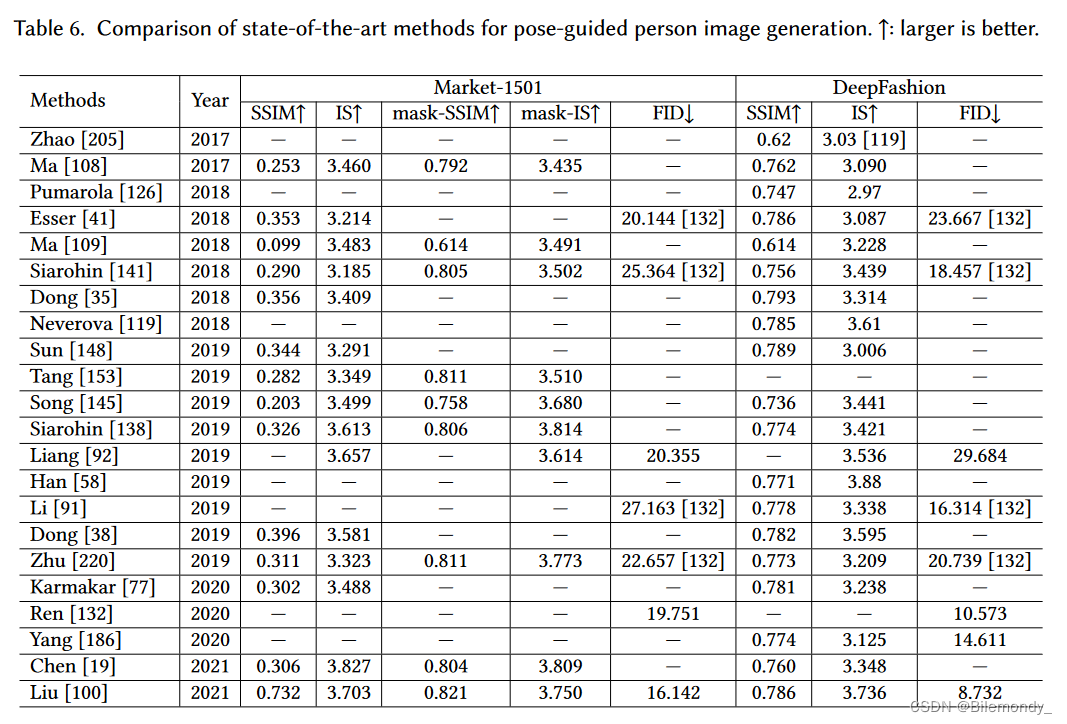
表6展示了主要先进的姿态引导行人图像生成方法的定量结果。平均而言,变形和混合方法优于自顶向下和潜在特征表示方法。同样,Tab . 7给出了虚拟试凑方法的比较。混合方法比其他方法更有竞争力。
应用实例
我们从面孔、姿势和布料合成的角度对深度人物生成进行了综述。本节基于上述基本任务给出典型应用。我们主要针对3个典型应用:生成数据增强(生成的数据如何帮助机器)、虚拟试衣和数字人(生成的数据如何能够帮助人类)。
生成数据增强
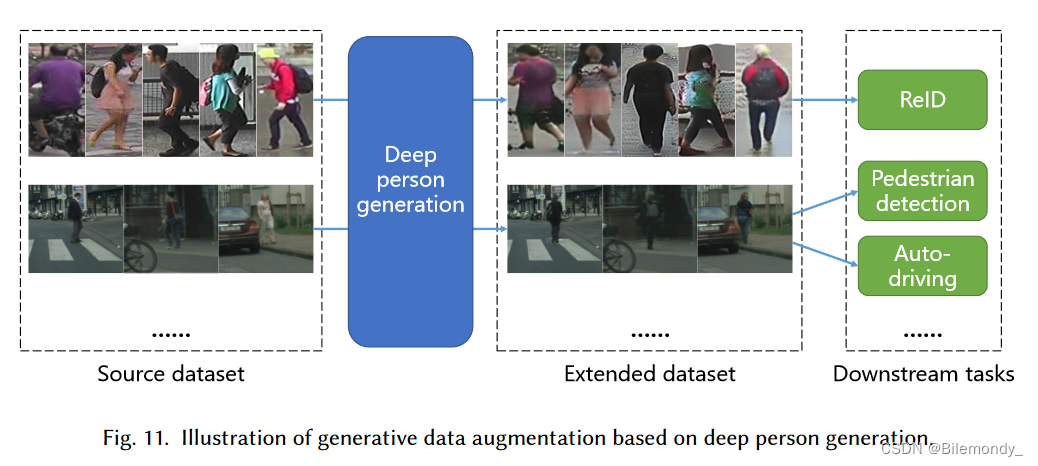
大多数深度学习模型都渴望获得优越的性能。如图11所示,在行人重识别、行人检测、自动驾驶等与行人相关的任务中,深度行人生成常被用作数据增强。
行人重识别需要来自不同视角的同一人的海量图像,但现有数据集只能为每个ID提供有限的图像。Zheng等[ 212 ]生成不同视角的人物图像,并提出一种半监督学习方法来利用生成的无标签数据。Liu等[95] 使用姿态引导生成来增强ReID。Zhang等[ 204 ]使用改进的PG2 [ 108 ]网络合成具有不同姿态的行人图像,省去了人工标注。也有将生成过程集成到ReID流水线[ 48、127、211]中的方法。Ge等人[ 48 ]提出了一种特征蒸馏GAN (FD-GAN) ,其中姿态引导的生成用于学习鲁棒的身份相关和姿态无关的特征。Zheng等[ 211 ]提出了一种DG-Net,巧妙地将re-ID判别模块与姿态引导生成模块相结合,在新的姿态下生成新的人物图像,同时对生成图像的ID进行判别。
对于行人检测和自动驾驶中的任务,行人生成也被用于数据增强。行人-合成- GAN (Pedestrian- Synthesis-GAN,PS-GAN) [ 122 ]生成新的行人图像来丰富数据集,稳定地改进行人检测模型。类似地,Vobecký等人[ 166]提出了一个基于GAN的框架来增加自动驾驶中的行人数据集。此外,他们还将人体姿势作为另一种输入来合成具有所需姿势的人。
虚拟试衣
虚拟试穿Virtual try-on (Sec.4.1)强调布料合成,而虚拟试衣virtual fitting则需要在真实场景中同时进行布料和姿态变化,如图12所示。例如,在网上购物中,一个很大的需求是根据新奇的服装和姿势生成试穿图像。人们试图将虚拟结合起来为此尝试使用姿态引导生成。最近出现了一些虚拟试衣应用,如Zeekit5、FXMirror6和Magic Mirror7等。
一些方法是基于自上而下的方法。FashionOn [ 68 ]将源人体解析转换为目标姿态,然后用服装纹理对转换后的解析图进行全局填充。另一类工作是基于潜在特征表示。伊尔迪里姆等[ 190 ]使用潜在向量表示人体姿态、服装颜色和服装部件(如衬衫、外套、裤子、裙子、鞋子等)。Men等人[ 110 ]将一幅人物图像细致地分离成几个部分(例如,姿势、头部、上衣、裤子、手臂、腿),然后分别进行编码。
其他的应用都是基于[ 36、67、171、210]的布匹对齐。通过扩展CP - VTON,MG-VTON [ 36 ]通过目标位姿对解析图进行变形,并将目标位姿作为输入,在目标位姿中生成结果。Wang等人[ 171 ]用树扩张融合块( tree-blocks )替换标准的ResNet Block来丰富纹理细节。Zheng等[ 210 ]设计了一种注意力双向GAN来突出服装纹理。此外,Dong等人[ 37 ]提出了一种基于视频的拟合模型( FW-GAN : Flow-naviated Warping GAN)来生成带有新衣服的视频。
数字人
近年来,数字人引起了广泛的关注,其目的是构建具有逼真外观和行为的虚拟人。与拥有物理身体的机器人不同,数字人只存在于数字领域。目前,数字人已应用于Zoombot视频会议AI、搜狗AI虚拟主播、客服等多个场景,如图13所示。

数字人被期望与人进行自然语言、面部表情和身体姿态的交互,就像真实的人一样。而一个整体的方法是首选的,一个可行的方法是将说话头和姿态引导生成结合起来。给定一个语音信号,会话头生成可以合成自然的嘴唇动作、面部表情和头部动作。同时,身体也可以根据信号进行合成,发出与语音相关的手势或自发动作[ 3、42、52、63、86]。模型在大规模数据集上进行训练,以捕获通用的语音到状态的(姿势、表情等。)映射和个性化风格。
未来方向
在本文中,我们从人脸、姿势和服装三个组成部分对深度人物生成进行了综述。得益于深度学习的惊人演进,我们见证了人物生成的快速发展,从生成低分辨率、粗糙的图像到生成高分辨率、细节逼真的图像。然而,在按需生成视觉上合理的人物图像/视频方面,人物生成还远未成熟。在此,我们列举了几个未来值得进一步研究的方向。
计算机图形学与计算机视觉的融合
计算机图形学( Computer Graphics, CG )在创建电影和游戏中的虚拟角色方面有着成熟的流程。同时,计算机视觉( Computer Vision, CV )支持合成具有真实感的人脸或人体图像。两者都有其独特的优势。具体来说,CG擅长运动控制和外观编辑,CV则产生更真实的外观。最近,已经有一些早期的尝试将CG和CV的优点结合起来,例如,基于神经渲染[ 154 ]、基于NeRF [ 111 ]的说话人生成[ 56 ]、基于3D人体网格的姿态引导生成[ 98 ]等。对于深度人物生成,三维人脸重建在提高表情和头部运动的准确性方面表现出了巨大的潜力。
可信的内容
人的一代的日益成熟对社会的威胁越来越大。滥用假人形象可能会引发严重的伦理和法律问题,尤其是在名人或政治家的视频中。例如,深度伪造(例如,头部互换、面部重做等)现在可以制作名人或政治家的逼真伪造图像或视频。与此相反,涉人取证旨在检测伪造的图像或视频,因而受到越来越多的关注。然而,现有工作大多是性能驱动的,从而忽略了模型的可解释性和高效性。而且,大多数方法都是唯一在固定的数据集上进行调优,实际使用时泛化能力也受到限制。健壮、可信的面向伪造检测,特别是针对与人相关的图像或视频的伪造检测,在加速技术演进和防止假冒伪劣材料被滥用方面发挥着至关重要的作用。
新兴任务
若干衍生任务开始涌现,前景广阔。
Person-in-context synthesis
旨在通过包围盒(布局)定义的复杂上下文中生成多个人物实例[ 191 ]。简单地将单人模型借用到多人案例中可能是次优的。最近,Person-in-context合成作为一个更具挑战性的问题开始受到关注。
Video-based person generation
与静态图像相比,由于时间和空间一致性的问题,视频生成的难度要大得多。此外,与视频相关的任务通常需要大规模的数据集,这可能会带来另一个挑战。
Text-guided person generation
文字描述提供了一种在生成过程中与人类互动的自然方式。与人相关的外观操作[ 215 ]尤其有助于基于人类请求的交互生成。
参考文献
过长


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









