







论文解读:GAT
论文信息
论文标题:Graph Attention Networks
论文作者:Petar Velickovic、Guillem Cucurull、Arantxa Casanova、Adriana Romero、P. Lio’、Yoshua Bengio
论文来源:2018 ICLR
论文地址:paper
论文代码:code
INTRODUCTION
两种模态结构
- grid-like structure(网格结构):photo
- irregular domain:3D meshes(三维网络), social networks, biological networks or brain connectomes
目前研究
图的研究
- 光谱方法:学习滤波器都依赖于拉普拉斯特征基,拉普拉斯特征基依赖于图的结构。因此,在特定结构上训练的模型不能直接应用于不同结构的图。
- 非光谱方法:
注意力机制
- 允许处理可变大小的输入,关注输入中最相关的部分来做出决策。
- 当注意机制用于计算单个序列的表示时,通常称为自我注意或内部注意self-attention or intra-attention
attention-based architecture
特性
- 操作高效,因为它可以跨节点-邻居对node- neighbor pairs并行;
- 它可以通过给邻居指定任意的权重来适用于不同程度的图节点;
- 该模型直接适用于归纳学习问题inductive learning problems,包括模型必须推广到完全看不见的图的任务。
GAT 网络架构
图注意力层
输入输出
层输入: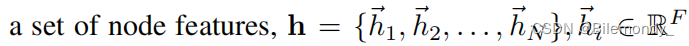
输出:![]()
其中 F F F 和 F ′ F' F′表示不同的节点特征维度, N N N是节点个数
注意力机制
为了获得足够的表达能力将输入特征转换为更高层次的特征,Graph attentional layer 首先根据输入的节点特征向量集,进行 self-attention处理:
e
i
j
=
a
(
W
h
⃗
i
,
W
h
⃗
j
)
e_{i j}=a(\mathbf{W} \vec{h}_{i}, \mathbf{W} \vec{h}_{j} )
eij=a(Whi,Whj)
其中
a
a
a 是一个
R
F
′
×
R
F
′
→
R
\mathbb{R}^{F^{\prime}} \times \mathbb{R}^{F^{\prime}} \rightarrow \mathbb{R}
RF′×RF′→R 的映射;
W
∈
R
F
′
×
F
W \in \mathbb{R}^{F^{\prime} \times F}
W∈RF′×F 是一个权重矩阵(被所有
h
⃗
i
\vec{h}_{i}
hi 的共享);
e
i
j
e_{ij}
eij 表明节点
j
j
j 的特征对节点
i
i
i 的重要性,也就是注意力系数。
一般来说,self-attention 会将注意力分配到图中所有的节点上,这种做法显然会丢失结构信息。为了解决这一问题,本文使用了一种 masked attention 的方式——仅将注意力分配到节点 i i i 的邻节点集上,即 j ∈ N i j \in \mathcal{N}_{i} j∈Ni,(在本文中,节点 i i i 也是 N i \mathcal{N}_{i} Ni 的一部分)。
归一化注意力系数
为了使注意力权重在不同节点之间容易比较,我们使用 Softmax 函数对所有的选择进行标准化:
α
i
j
=
softmax
j
(
e
i
j
)
=
e
x
p
(
e
i
j
)
∑
k
∈
N
i
e
x
p
(
e
i
k
)
\alpha_{i j}=\operatorname{softmax}_{j}( e_{i j} )=\frac{exp (e_{i j} )}{\sum \limits _{k \in \mathcal{N}_{i}} exp (e_{i k} )}
αij=softmaxj(eij)=k∈Ni∑exp(eik)exp(eij)
其中,
a
→
∈
R
2
F
′
\overrightarrow{\mathbf{a}} \in \mathbb{R}^{2 F^{\prime}}
a∈R2F′ 是单层前馈神经网络
a
a
a 的一个权重向量参数。
a
a
a 使用 LeakyReLU 非线性激活函数(在负区间,斜率
α
=
0.2
\alpha=0.2
α=0.2)。
注意力机制的完全形式为:
α
i
j
=
e
x
p
(
LeakyReLU
(
a
→
T
[
W
h
⃗
i
∣
∣
W
h
⃗
j
]
)
)
∑
k
∈
N
i
e
x
p
(
LeakyReLU
(
a
→
T
[
W
h
⃗
i
∣
∣
W
h
⃗
k
]
)
)
\alpha_{i j}=\frac{exp (\operatorname{LeakyReLU}(\overrightarrow{\mathbf{a}}^{T}[\mathbf{W} \vec{h}_{i} || \mathbf{W} \vec{h}_{j} ] ) )}{\sum \limits _{k \in \mathcal{N}_{i}} exp (\operatorname{LeakyReLU}(\overrightarrow{\mathbf{a}}^{T}[\mathbf{W} \vec{h}_{i} || \mathbf{W} \vec{h}_{k} ] ) )}
αij=k∈Ni∑exp(LeakyReLU(aT[Whi∣∣Whk]))exp(LeakyReLU(aT[Whi∣∣Whj]))
其中,
a
⃗
T
∈
R
2
F
′
\vec{a}^{T} \in \mathbb{R}^{2 F^{\prime}}
aT∈R2F′ 为前馈神经网络
a
a
a 的参数,
.
T
{.}^{T}
.T 代表着是转置操作,
∣
∣
||
∣∣ 是串联操作( t.cat )。这里最终
α
i
j
ϵ
R
\alpha_{ij} \epsilon {\mathbb{R}}
αijϵR
通过邻居节点更新自身节点
1. 加权求和
h ⃗ i ′ = σ ( ∑ j ∈ N 1 α i j W h ⃗ j ) \vec{h}_{i}^{\prime}=\sigma(\sum \limits _{j \in \mathcal{N}_{\mathbf{1}}} \alpha_{i j} \mathbf{W} \vec{h}_{j} ) hi′=σ(j∈N1∑αijWhj)
2. Multi-head Attention
为提高模型的拟合能力,本文引入了 multi-head attention ,即同时使用多个
W
k
W^{k}
Wk 计算 self-attention,然后将各个
W
k
W^{k}
Wk 计算得到的结果合并(连接concat或求和):
h
⃗
i
′
=
∣
∣
k
=
1
K
σ
(
∑
j
∈
N
i
α
i
j
k
W
k
h
⃗
j
)
\vec{h}_{i}^{\prime}=||_{k=1}^{K} \sigma(\sum \limits _{j \in \mathcal{N}_{i}} \alpha_{i j}^{k} \mathbf{W}^{k} \vec{h}_{j} )
hi′=∣∣k=1Kσ(j∈Ni∑αijkWkhj)
其中,
∣
∣
||
∣∣ 表示concat,
a
i
j
k
a_{i j}^{k}
aijk 表示第
k
k
k 个注意机制计算的归一化注意力系数。由于
W
k
∈
R
F
′
×
F
W^{k} \in \mathbb{R}^{F^{\prime} \times F}
Wk∈RF′×F , 因此这里的
h
⃗
i
′
∈
R
K
F
′
\vec{h}_{i}^{\prime} \in \mathbb{R}^{K F^{\prime}}
hi′∈RKF′ 。
如果我们对网络的最终(预测)层执行 multi-head attention ,那么连接就不再是明智的,可以采取求和的方式来得到
h
⃗
i
′
\vec{h}_{i}^{\prime}
hi′:
h
⃗
i
′
=
σ
(
1
K
∑
k
=
1
K
∑
j
∈
N
i
α
i
j
k
W
k
h
⃗
j
)
\vec{h}_{i}^{\prime}=\sigma(\frac{1}{K} \sum \limits _{k=1}^{K} \sum \limits_{j \in \mathcal{N}_{i}} \alpha_{i j}^{k} \mathbf{W}^{k} \vec{h}_{j} )
hi′=σ(K1k=1∑Kj∈Ni∑αijkWkhj)
由于
W
k
∈
R
F
′
×
F
W^{k} \in \mathbb{R}^{F^{\prime} \times F}
Wk∈RF′×F ,因此这里的
h
⃗
i
′
∈
R
F
′
\vec{h}_{i}^{\prime} \in \mathbb{R}^{ F^{\prime}}
hi′∈RF′ 。
3. 生成注意力系数及Multi-head Attention 图示
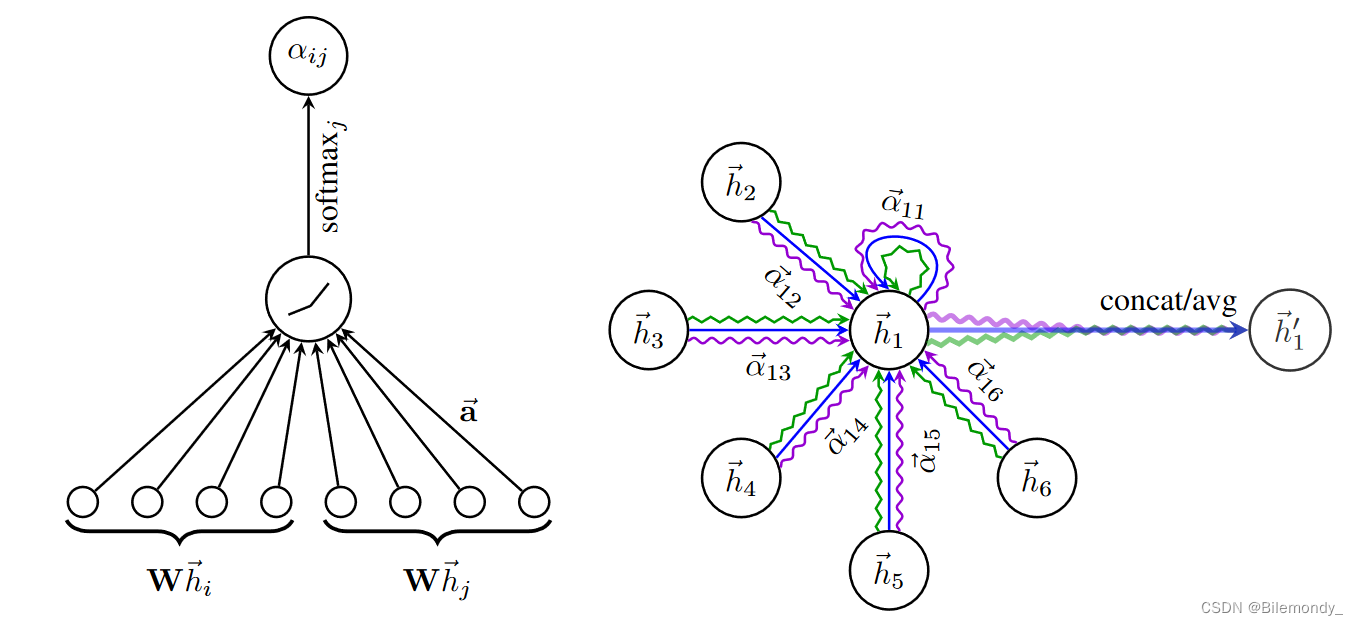
右图中不同颜色表示不同的head,一共有三个head。
GAT相比于先前研究的优势
- 计算高效。Self-Attention层的可以跨所有边并行化,输出特征的计算可以跨所有节点并行化。
- 可解释,且更有效。
- Inductive learning。可以泛化到未见过的节点和图,甚至completely unseen graph
- 解决GraphSage的缺点。GraphSage不能在推理期间访问所有邻居。
- GAT可以重新表述为MoNet的一个特定实例。更具体地说,将伪坐标函数设置为u(x,y)= f(x)||f(y),其中f(x)表示节点x的(一潜在的MLP变换的)特征,||表示串联;权函数为wj (u) = softmax(MLP(u))(在节点的整个邻域内执行softmax)将使MoNet的补丁操作符patch operator与我们的类似。尽管如此,人们应该注意到,与以前考虑的MoNet实例相比,我们的模型使用节点特征进行相似性计算,而不是节点的结构属性(这将假设提前知道图的结构)。
英文写作
摘要
-
We present graph attention networks (GATs), novel neural network architectures that operate on graph-structured data, leveraging masked self-attentional layers to address the shortcomings of prior methods based on graph convolutions or their approximations.
-
we enable (implicitly) specifying(指定) different weights to different nodes
-
inversion 矩阵求逆
-
In this way, we address several key challenges of spectral-based graph neural net-works simultaneously(同时解决了xxx), and make our model readily applicable to (使我们的模型易于适用于)inductive (归纳)as well as transductive problems(转导问题).
-
Our GAT models have achieved or matched state-of-the-art results across four established transductive and inductive graph benchmarks: xx,xx,and xx datasets, as well as xx dataset.
INTRODUCTION
- There have been several attempts in the literature(文献) to extend neural networks to deal with arbitrarily structured graphs. Early work used xxx
- Attention mechanisms have become almost a de facto standard (已经成为事实标准)in many sequence-based tasks
- achieving or matching state-of-the-art results that highlight the potential of attention-based models when dealing with arbitrarily structured graphs.
GAT ARCHITECTURE
- In order to obtain sufficient expressive power to transform the input features into higher-level features(为了获得足够的表达能力将输入特征转换为更高阶特征), at least one learnable linear transformation is required. 至少需要一次可学习的线性变换
CONCLUSIONS
- We have presented graph attention networks (GATs), novel convolution-style neural networks that operate on graph-structured data, leveraging masked self-attentional layers. 我们提出了图注意网络(GATs),这是一种新型的卷积型神经网络,它利用隐藏的自我注意层masked self-attentional layers对图结构数据进行操作。
- The graph attentional layer utilized throughout these networks is computationally efficient (does not require costly matrix operations, and is parallelizable across all nodes in the graph), allows for (implicitly) assigning different importances to different nodes within a neighborhood while dealing with different sized neighborhoods, and does not depend on knowing the entire graph structure upfront—thus addressing many of the theoretical issues with previous spectral-based approaches. 在这些网络中使用的图注意力层计算效率很高(不需要昂贵的矩阵运算,并且可以在图中的所有节点上并行),允许(隐式)在处理不同大小的邻域时向邻域内的不同节点分配不同的重要性,并且不依赖于预先知道整个图结构——从而用以前的基于谱的方法解决了许多理论问题。
- Our models leveraging attention have successfully achieved or matched state-of-the-art performance across four well-established node classification benchmarks, both transductive and inductive (especially, with completely unseen graphs used for testing). 我们利用注意力的模型已经在四个完善的节点分类基准上成功实现或匹配了最先进的性能,包括转导型transductive和归纳型inductive(尤其是使用完全看不见的图进行测试)。
- There are several potential improvements and extensions to graph attention networks that could be addressed as future work, such as overcoming the practical problems described in subsection 2.2 to be able to handle larger batch sizes. 图注意力网络有几个潜在的改进和扩展可以作为未来的工作来解决,比如克服第2.2款中描述的实际问题,以便能够处理更大的批量。
- A particularly interesting research direction would be taking advantage of the attention mechanism to perform a thorough analysis on the model interpretability. 一个特别有趣的研究方向将是利用注意力机制对模型的可解释性进行深入分析。
- Moreover, extending the method to perform graph classification instead of node classification would also be relevant from the application perspective. 此外,从应用的角度来看,扩展该方法来执行图分类而不是节点分类也是有意义的。
- Finally, extending the model to incorporate edge features (possibly indicating relationship among nodes) would allow us to tackle a larger variety of problems. 最后,扩展模型以合并边缘特征(可能指示节点之间的关系)将允许我们处理更大的各种问题。














 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









