







YOLOv1、YOLOv2都是在CVPR这种正规的计算机视觉学术会议上发表的正式学术论文。
YOLOv3不算一篇严谨的学术论文,是作者随笔写的技术报告。
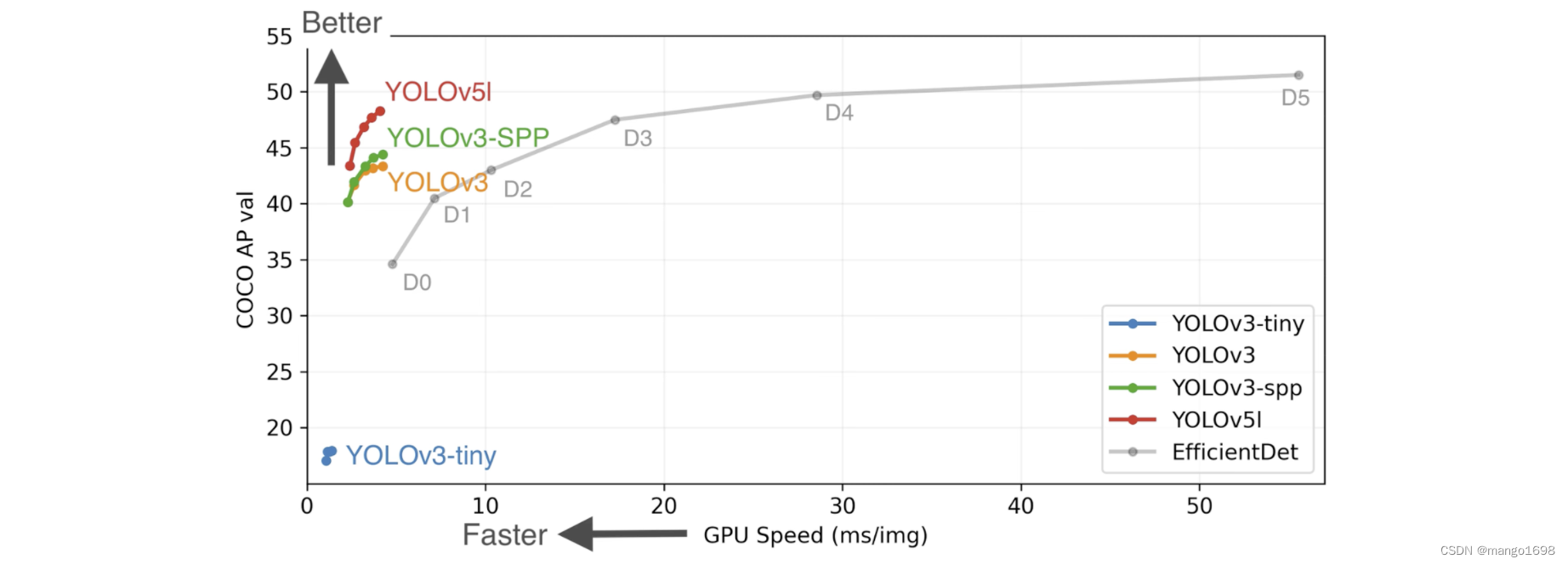
YOLOv3性能:
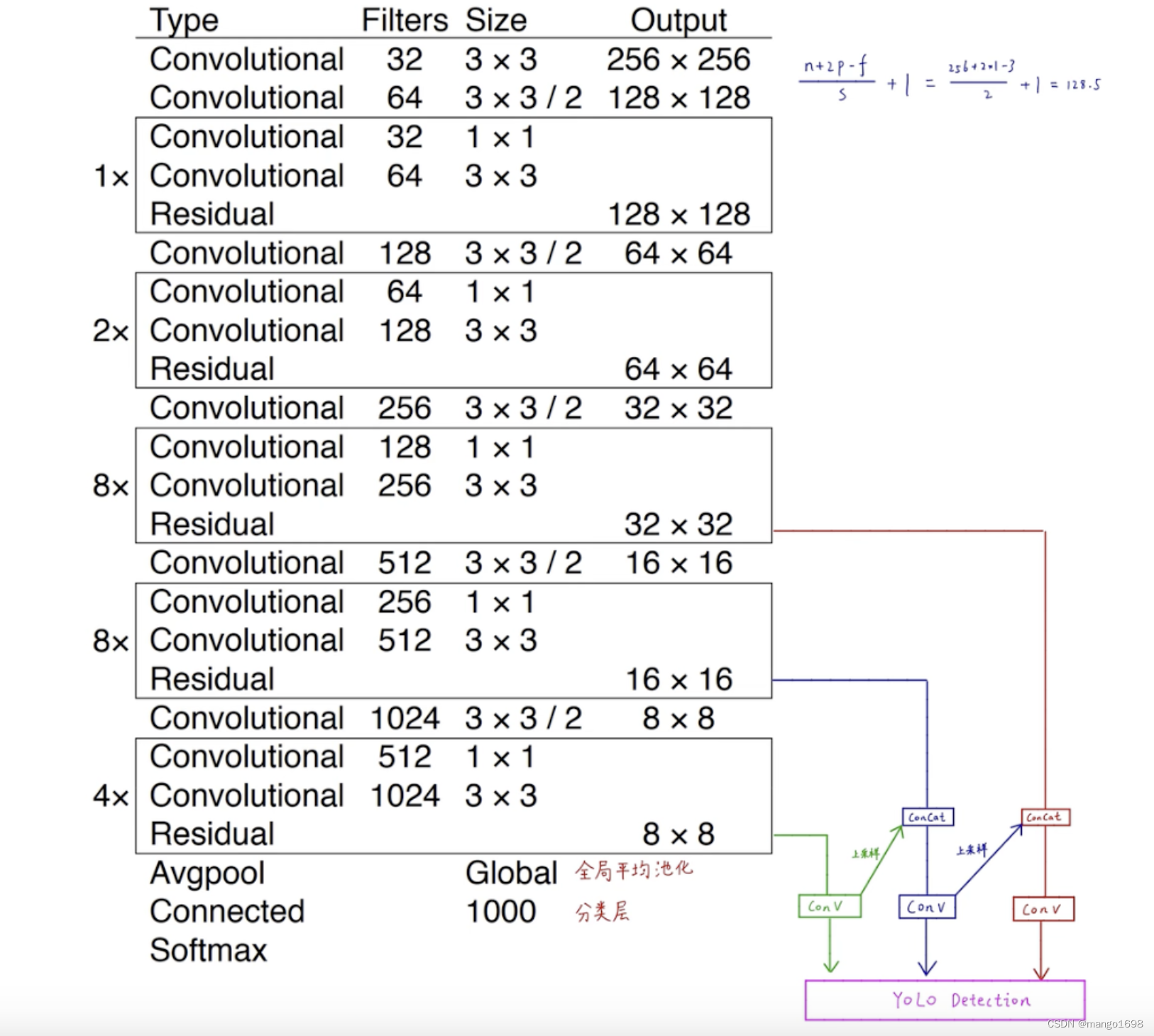
1. Backbone Darknet-53
YOLOv3在v2的基础上,更换了骨干网络,将Darknet-19替换为了Darknet-53。
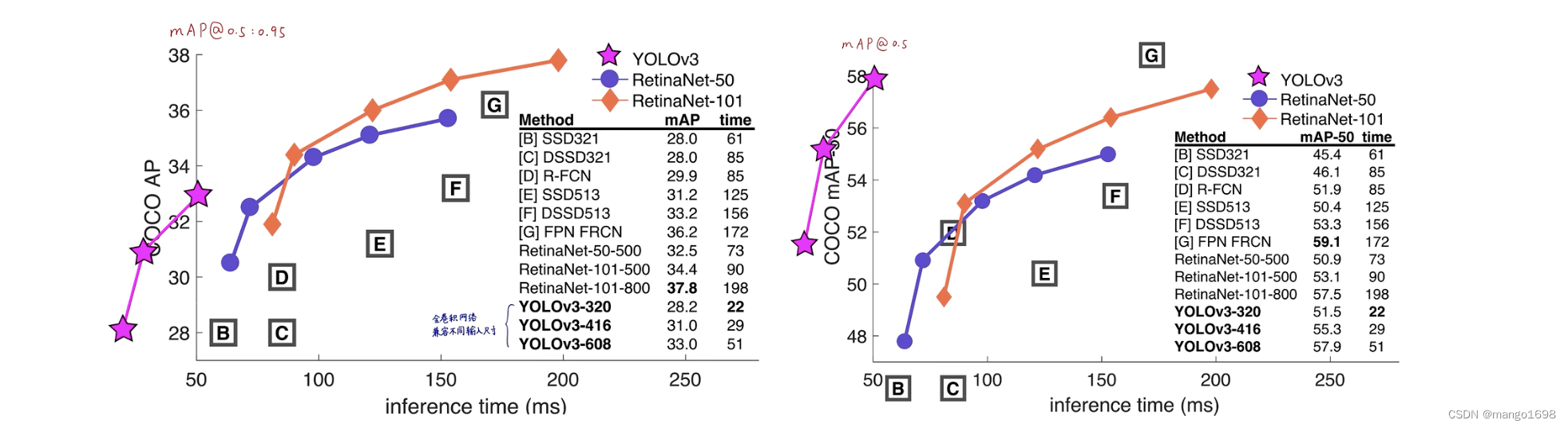
性能对比:

2. 整体架构
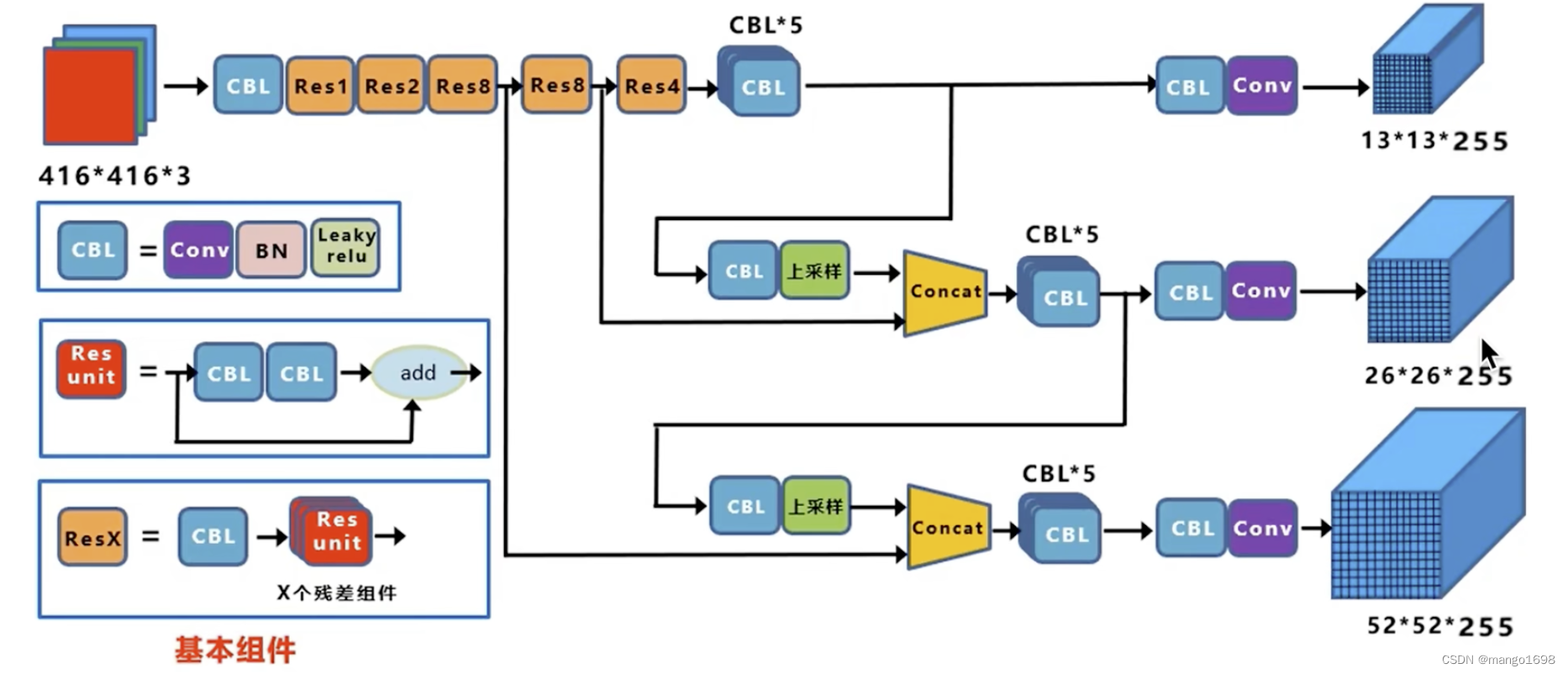
输入为416*416大小的图像。输出3个尺度的feature map,分别为 13 × 13 × 255 , 26 × 26 × 255 , 52 × 52 × 255 13\times 13\times 255,26\times 26\times 255,52\times 52\times 255 13×13×255,26×26×255,52×52×255。
三个尺度,分别输入图像划分为 13 × 13 , 26 × 26 , 52 × 52 13\times 13,26\times 26,52\times 52 13×13,26×26,52×52个grid cell。
13 × 13 13\times 13 13×13下采样32倍, 26 × 26 26\times 26 26×26下采样16倍, 52 × 52 52\times 52 52×52下采样8倍。
13 × 13 13\times 13 13×13的感受野对应原图上的感受野就是 32 × 32 32\times 32 32×32。
13 × 13 13\times13 13×13负责预测大物体, 26 × 26 26\times26 26×26负责预测中等大小物体, 52 × 52 52\times52 52×52负责预测小物体。
255怎么来的呢?
3 × ( 5 + 80 ) = 255 3\times (5+80)=255 3×(5+80)=255。其中3:每个grid cell生成3个anchor,每个anchor对应一个预测框,每个预测框有5+80个参数,5:(x,y,w,h,c),80:coco数据集80个类别的条件类别概率 。
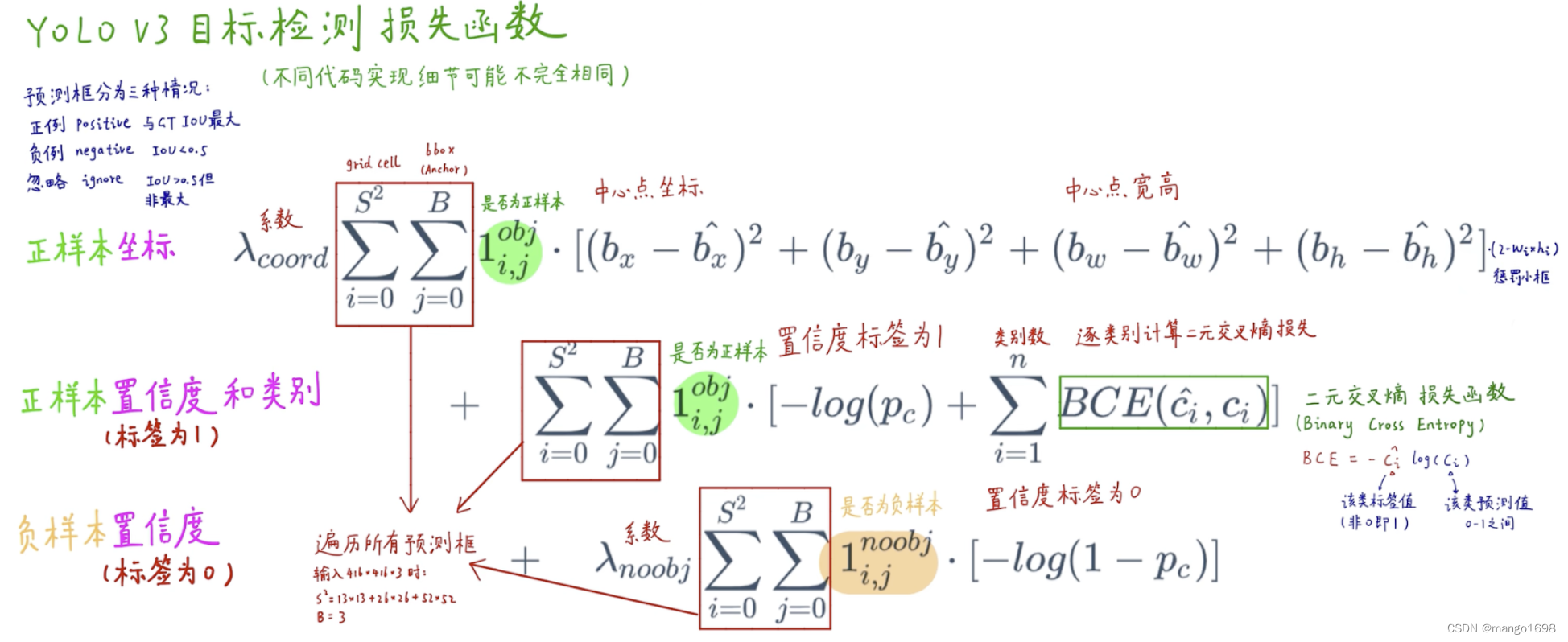
3. 损失函数
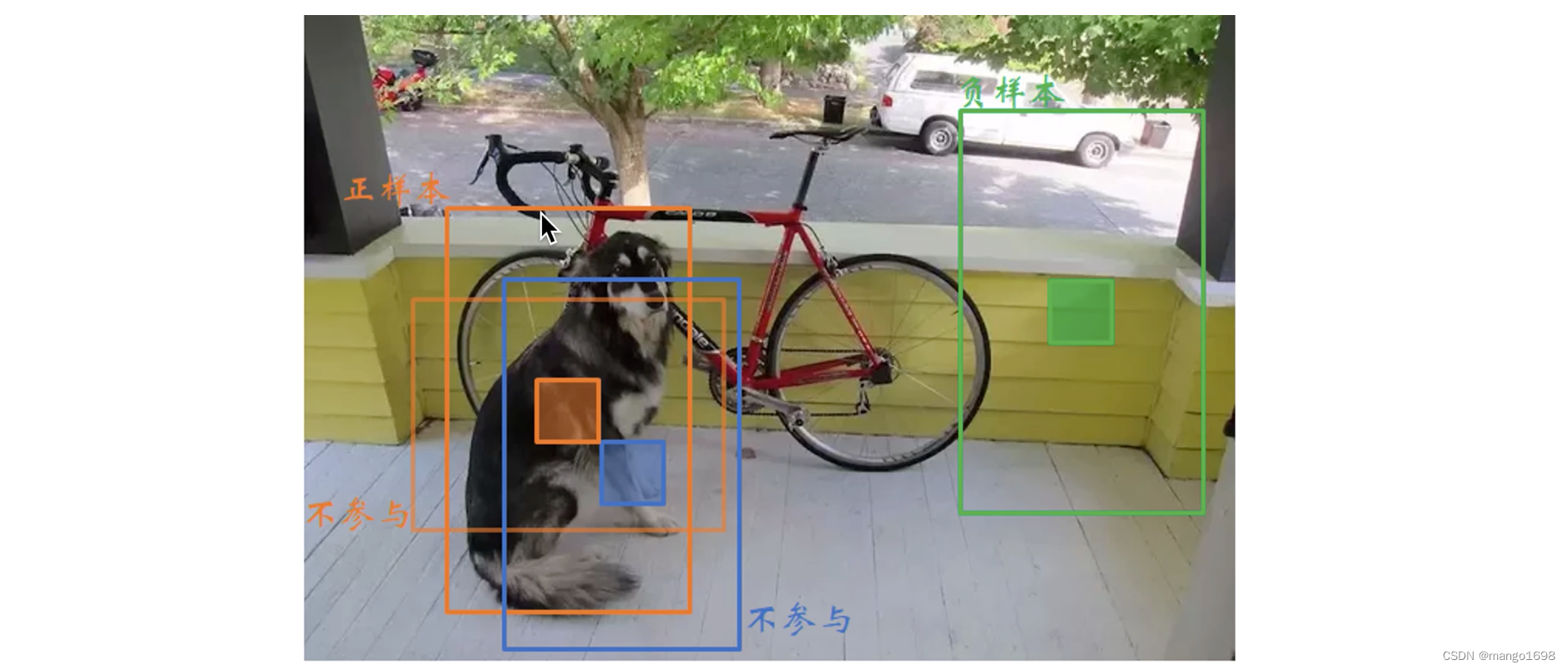
在yolov3中,如果一个anchor和ground-truth的IoU最大,那么它就是正样本。如果它和ground-truth有一
部分IoU,但是不是最大的,那么这些框则忽略掉。如果某个anchor和ground-truth的IoU小于阀值,它则为负样本。
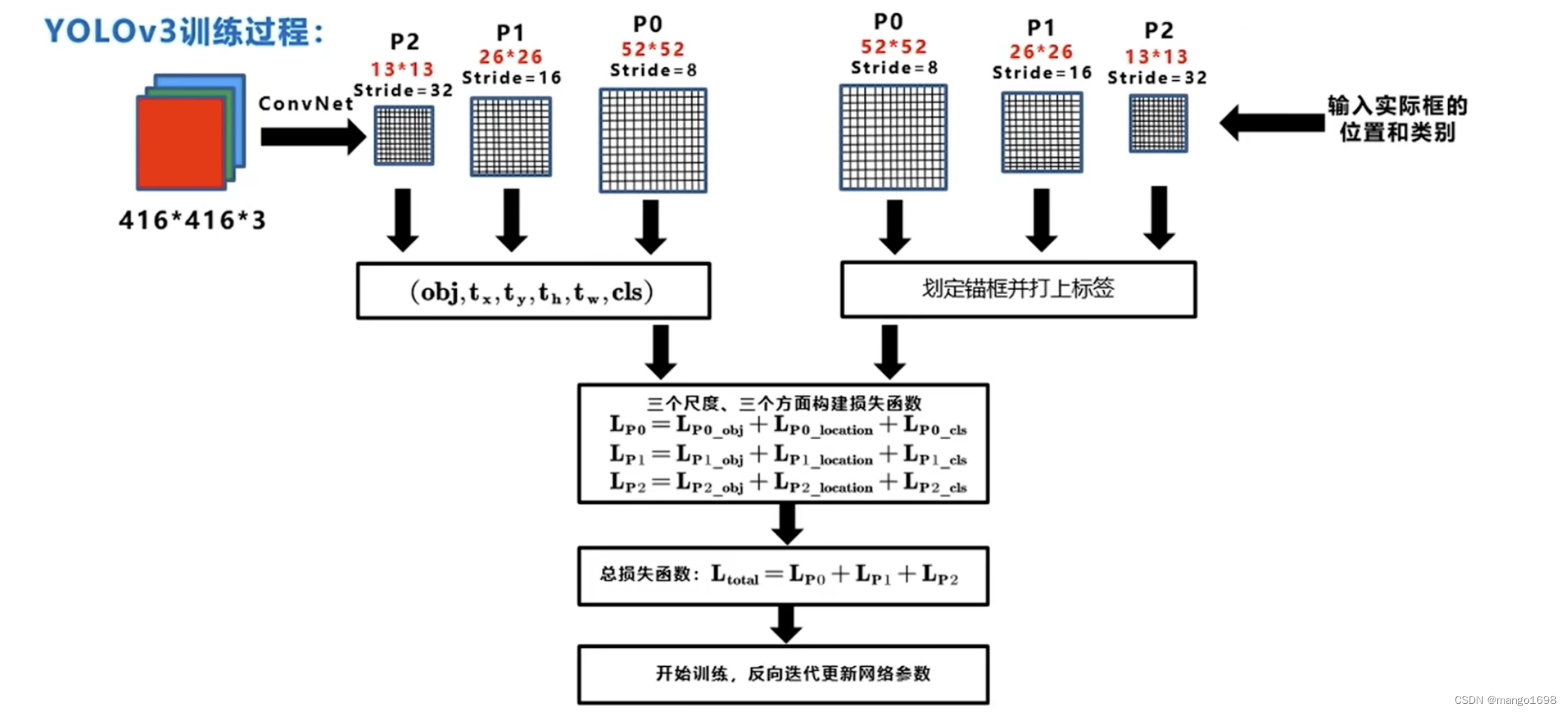
4. 训练过程
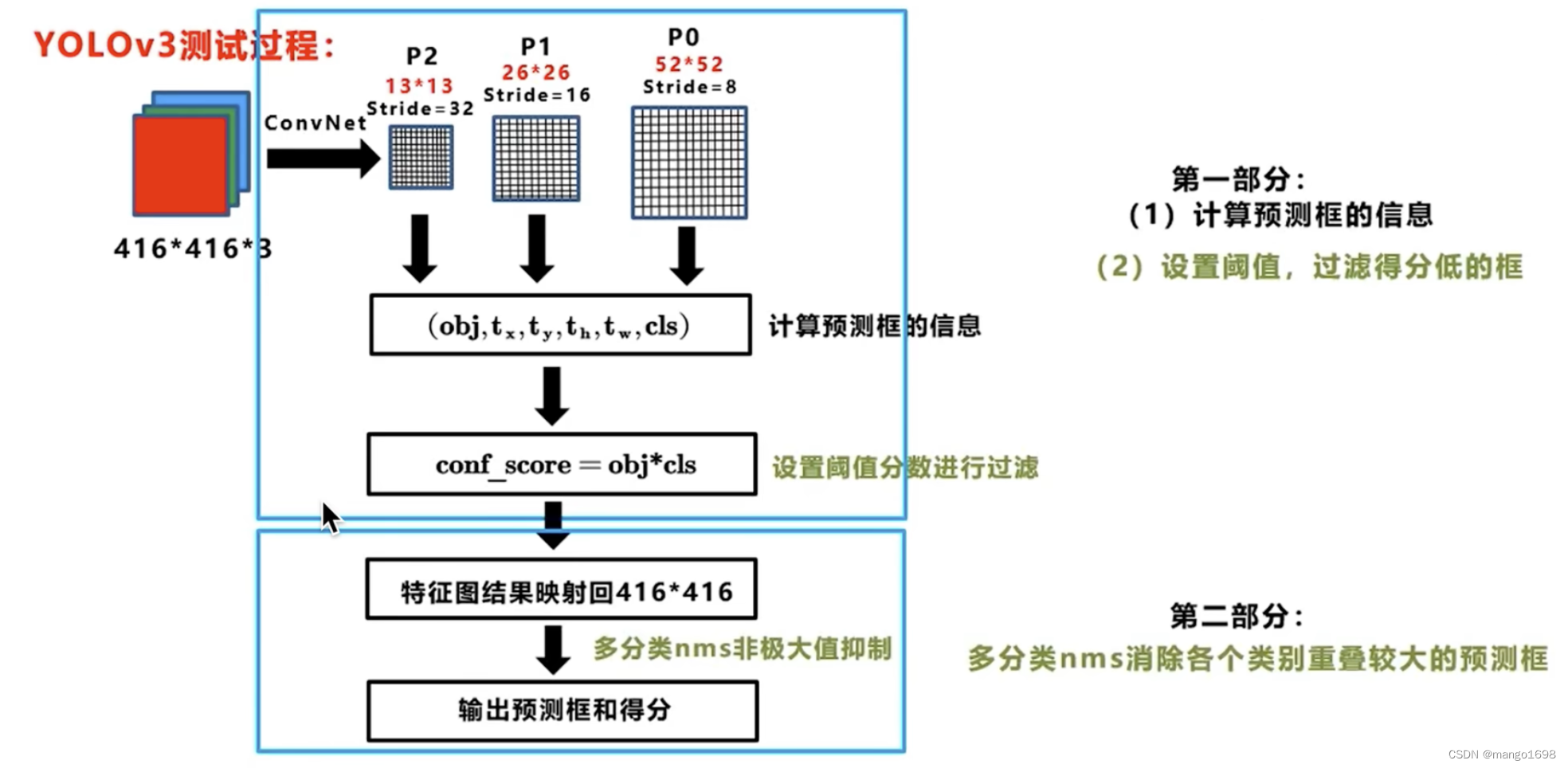
5. 预测过程
















 3097
3097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











