







Redolog 日志
redo log日志也叫重做日志,记录某个数据页修改操作;主要用来保证数据的容灾恢复(crash-safe);【物理日志】
物理日志:因为
mysql数据最终保存在数据页中,物理日志记录的就是数据页变更;
redolog日志是数据库事务持久性的保证。用来恢复未写入data file的已成功事务更新的数据。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。
每次事务完成后都直接提交到磁盘中也能保证持久性,为什么还需要
redolog日志?
最简单的做法是在每次事务提交的时候,将该事务涉及修改的数据页全部刷新到磁盘中。但是这么做会有严重的性能问题;接下来我们分析下以数据页为单位提交的弊端;
InnoDB引擎是以页为单位进行磁盘交互的,而一个事务很可能只修改一个数据页里面的几个字节,这个时候将完整的数据页刷到磁盘的话,太浪费资源了!并且一个事务可能涉及修改多个数据页,并且这些数据页在物理上并不连续,使用随机IO写入性能太差!所以
mysql设计了redolog 日志,只记录事务对数据页做了哪些修改
1. Redolog 日志文件的介绍
InnoDB的redolog是固定大小的,比如可以配置为一组4个文件,每个文件的大小是 1GB,那么这个文件总共就可以记录4GB的操作。从头开始写,写到末尾就又回到开头循环写,如下图所示:

checkpoint:检查点,代表的是当前要擦除的位置,擦除之前要把记录更新到数据文件
write pos:代表当前记录的位置;
write pos和checkpoint之间的是还空着的部分,可以用来记录新的操作。如果write pos追上checkpoint,表示满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把checkpoint推进一下。
2. Redolog日志的日志记录流程
WAL:"write ahead logging"先写日志,再写磁盘。redolog和binlog都使用的是这种技术.
2.1. 宏观角度
当一条记录需要更新时,InnoDB引擎会先将记录写到 redolog日志里,并更新内存数据,这个时候更新就算完成了。并且在合适的时候,根据更新策略将操作记录更新到磁盘中;
只会修改内存页中的数据,不会更改磁盘中的数据信息;至于内存页中的数据信息何时同步到磁盘中,会有一些触发条件;
更新到磁盘包含了两个方面
- 内存页中的数据更新到磁盘(脏页)
redolog日志持久化到磁盘。
2.2. 微观角度
从微观角度分析redolog日志的记录流程,涉及到 redolog buffer,page cache,hard disk
2.2.1 记录到日志
对应宏观流程中的,InnoDB引擎会先将记录写到 redolog日志里,InnoDB并非直接会将日志记录到 redolog 日志文件中,而是会先将日志写到 redolog buffer,redolog 日志的过程分为 prepare 和 commit 阶段,生成的日志在 commit时 才会将 redolog buffer 中的日志信息写入到 redolog 日志文件中;
(
redolog buffer:内存中的一块区域)
2.2.2 合适的时间刷新到磁盘(更新策略)
redolog 日志是如何刷新到磁盘的?
这个问题,要从 redolog 可能存在的三种状态说起。这三种状态,对应的就是下图中的三个颜色块。
- 存在
redolog buffer中,物理上是在MySQL进程内存中,就是图中的红色部分; - 写到磁盘 (
write),但是没有持久化(fsync),物理上是在文件系统的page cache里面,也就是图中的黄色部分; - 持久化到磁盘,对应的是
hard disk,也就是图中的绿色部分。
日志写到
redo log buffer是很快的,write到page cache也差不多,但是持久化到磁盘的速度就慢多了。在计算机中,用户空间(
user space)下的缓冲区数据 (redolog buffer)一般情况下是无法直接写入磁盘的,中间必须经过操作系统内核空间(kernel space)缓冲区(page Cache)。然后系统调用fsync()将其刷到磁盘。
Page Cache的本质是由Linux内核管理的内存区域。
为了控制 redolog 的写入策略,InnoDB 提供了 innodb_flush_log_at_trx_commit 参数,它有三种可能取值:
- 设置为 0 的时候,表示每次事务提交时都只是把
redolog留在redolog buffer中 ; - 设置为 1 的时候,表示每次事务提交时都将
redolog直接持久化到磁盘; - 设置为 2 的时候,表示每次事务提交时都只是把
redolog写到page cache。
可以看到当我们将 innodb_flush_log_at_trx_commit=1时,才会将日志记录到磁盘完成持久化。若我们将参数设置为其他是否意味着redolog日志不会进行持久化,异常重启就会丢失数据呢?
不会的,InnoDB 有一个后台线程,每隔 1 秒,就会把 redolog buffer 中的日志,调用 write 写到文件系统的 page cache,然后调用 fsync 持久化到磁盘。所以,事务执行中间过程的 redolog 也是直接写在 redolog buffer 中的,这些 redolog 也会被后台线程一起持久化到磁盘。也就是说,一个没有提交的事务的 redolog,也是可能已经持久化到磁盘的。
实际上,除了后台线程每秒一次的轮询操作外,还有两种场景会让一个没有提交的事务的 redolog 写入到磁盘中。
- 一种是,
redolog buffer占用的空间即将达到innodb_log_buffer_size一半的时候,后台线程会主动写盘。注意,由于这个事务并没有提交,所以这个写盘动作只是write,而没有调用fsync,也就是只留在了文件系统的page cache。 - 另一种是,并行的事务提交的时候,顺带将这个事务的
redolog buffer持久化到磁盘。假设一个事务 A 执行到一半,已经写了一些redo log 到 buffer中,这时候有另外一个线程的事务 B 提交,如果innodb_flush_log_at_trx_commit设置的是 1,那么按照这个参数的逻辑,事务 B 要把redolog buffer里的日志全部持久化到磁盘。这时候,就会带上事务 A 在redolog buffer里的日志一起持久化到磁盘。
2.3. redolog 日志和磁盘数据的关联关系
正常运行中的实例,数据写入后的最终落盘,是从
redolog更新过来的还是从 buffer pool 更新过来的呢?
redo log 并没有记录数据页的完整数据,所以它并没有能力自己去更新磁盘数据页,也就不存在“数据最终落盘,是由 redolog 更新过去”的情况。
- 如果是正常运行的实例的话,数据页被修改以后,跟磁盘的数据页不一致,称为脏页。最终数据落盘,就是把内存中的数据页写盘。这个过程甚至与
redolog毫无关系。 - 在崩溃恢复场景中,
InnoDB如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它读到内存,然后让redo log更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态。
3. 数据库的异常抖动(脏页的影响)
为什么我的
MySQL会“抖”一下?
一条SQL语句,正常执行的时候特别快,但是有时也不知道怎么回事,它就会变得特别慢,并且这样的场景很难复现,它不只随机,而且持续时间还很短。看上去,这就像是数据库“抖”了一下。
3.1 脏页
什么是脏页?
当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”。
数据库更新数据时,由于
磁盘IO非常的影响性能,所以InnoDB在处理更新语句的时候,平时执行很快的更新操作,其实就是在写内存和日志。
MySQL 偶尔“抖”一下的那个瞬间,可能就是在刷脏页(flush)。
刷脏页:内存中的数据记录到磁盘中,使磁盘中的数据和内存中保持一致;
3.2 什么情况会引发数据库的 刷脏页(flush) 过程呢?
redoLog日志满了(checkpoint和write pos间所有的脏页数据都flush到磁盘上)- 系统内存不足(当需要新的内存页,而内存不够用的时候,就要淘汰一些数据页,空出内存给别的数据页使用。如果淘汰的是“脏页”,就要先将脏页写到磁盘。)
MySQL认为系统“空闲”的时候MySQL正常关闭时
3.2.1 分析四种场景对性能的影响
第三种情况是属于 MySQL 空闲时的操作,这时系统没什么压力,而第四种场景是数据库本来就要关闭了。这两种情况下,你不会太关注“性能”问题。所以这里,我们主要来分析一下前两种场景下的性能问题。
第一种是“redo log 写满了,要 flush 脏页”,这种情况是 InnoDB 要尽量避免的。因为出现这种情况的时候,整个系统就不能再接受更新了,所有的更新都必须堵住。如果你从监控上看,这时候更新数会跌为 0。
第二种是“内存不够用了,要先将脏页写到磁盘”,这种情况其实是常态。
在InnoDB 中用缓冲池(buffer pool)管理内存,缓冲池中的内存页有三种状态:(内存页的三种状态)
- 还没有被使用
- 使用了的干净页
- 使用了的脏页
当要读入的数据页没有在内存的时候,就必须到缓冲池中申请一个数据页。 这时候只能把最久不使用的数据页从内存中淘汰掉:如果要淘汰的是一个干净页,就直接释放出来复用;但如果是脏页呢,就必须将脏页先刷到磁盘,变成干净页后才能复用。
当一个个查询要淘汰的脏页个数太多,会导致查询的响应时间明显变长,所以,InnoDB 需要有控制脏页比例的机制,来尽量避免上面的这两种情况。
innodb_max_dirty_pages_pct:脏页比例上限。默认75%
3.2.2 刷脏页中的连坐策略
一旦一个查询请求需要在执行过程中先 flush 掉一个脏页时,这个查询就可能要比平时慢了。而 MySQL 中的一个机制,可能让你的查询会更慢:在准备刷一个脏页的时候,如果这个数据页旁边的数据页刚好是脏页,就会把这个“邻居”也带着一起刷掉;而且这个把“邻居”拖下水的逻辑还可以继续蔓延,也就是对于每个邻居数据页,如果跟它相邻的数据页也还是脏页的话,也会被放到一起刷。
在 InnoDB 中,innodb_flush_neighbors 参数就是用来控制这个行为的,值为 1 的时候会有上述的“连坐”机制,值为 0 时表示不找邻居,自己刷自己的。
在 MySQL 8.0 中,innodb_flush_neighbors 参数的默认值已经是 0 了。
4. change buffer
上面我们介绍了redolog日志和内存、磁盘间的交互。并且也简单的介绍了以下脏页相关的概念。脏页指的是内存中的数据和磁盘中的数据不一致。
更新数据时,当数据存在于内存中直接修改内存中数据形成脏页
当数据不存在内存中,会采用change buffer的机制。

change buffer 的大小,可以通过参数 innodb_change_buffer_max_size 来动态设置。这个参数设置为 50 的时候,表示 change buffer 的大小最多只能占用 buffer pool 的 50%。
4.1 change buffer 的好处
将数据从磁盘读入内存涉及随机 IO 的访问,是数据库里面成本最高的操作之一。change buffer 因为减少了随机磁盘访问,所以对更新性能的提升是会很显的。(将需要更新的数据放在change buffer 中,多次更新的操作统一进行更新。降低了随机IO,提升性能;)
在MySQL中,InnoDB 中用缓冲池(buffer pool)管理内存,当执行查询或者更新语句时,存在两种情况(数据在内存中和数据不在内存中)。接下来针对这几种情况做一下具体分析。
4.2 查询过程
当内存中存在数据,直接从内存中返回。当内存中不存在数据,先从磁盘中加载数据页(InnoDB 的数据是按数据页为单位来读写的)到内存,然后返回。
4.3 更新过程
介绍更新过程前,我们需要先了解一下 change buffer ,内存数据页和磁盘的概念;
当需要更新一个数据页时,可以分为两种情况,数据页在内存中和数据页不在内存中
-
数据页在内存中
在内存中直接更新需要更改的数据
-
数据页不在内存中
在不影响数据一致性的前提下,
InooDB会将这些更新操作缓存在change buffer中,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行change buffer中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
将 change buffer 中的操作应用到原数据页,得到最新结果的过程称为 merge。除了访问这个数据页会触发 merge 外,系统有后台线程会定期 merge。在数据库正常关闭(shutdown)的过程中,也会执行 merge 操作。
一个数据页做 merge 之前,
change buffer记录的变更越多,收益就越大。
4.4 redolog 和 change buffer 分析
insert into t(id,k) values(id1,k1),(id2,k2);
我们假设当前 k 索引树的状态,查找到位置后,k1 所在的数据页在内存 (InnoDB buffer pool) 中,k2 所在的数据页不在内存中。
k1 通过索引排序,发现要插入数据页的位置就在内存中。
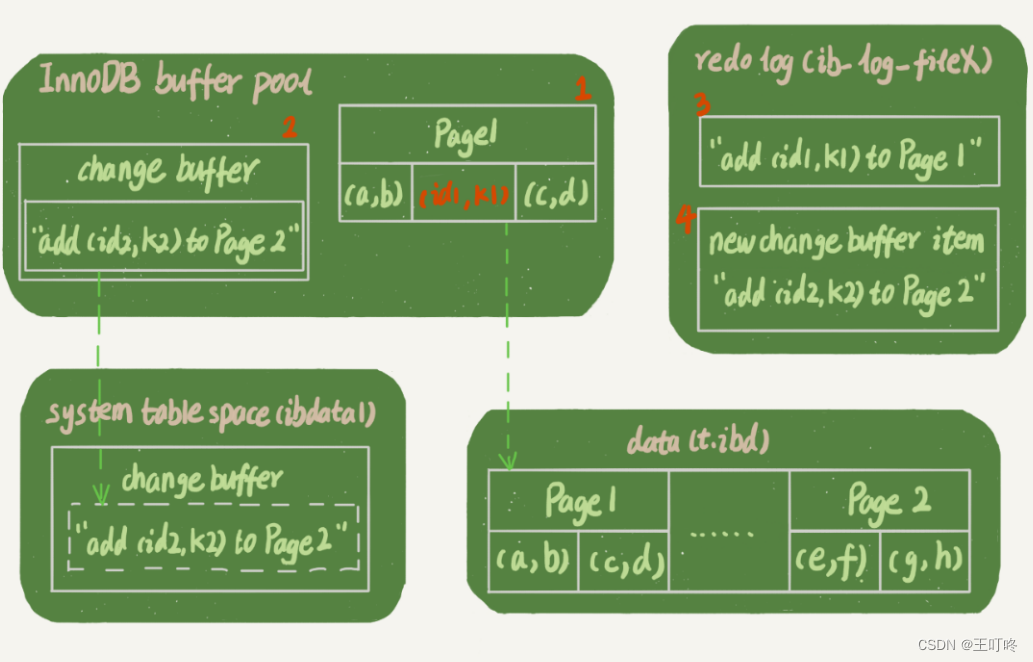
这条更新语句,你会发现它涉及了四个部分:内存、redo log(ib_log_fileX)、 数据表空间(t.ibd)、系统表空间(ibdata1)。
- Page 1 在内存中,直接更新内存;
- Page 2 没有在内存中,就在内存的 change buffer 区域,记录下“我要往 Page 2 插入一行”这个信息
- 将上述两个动作记入 redo log 中(图中 3 和 4)。
图中虚线的部分是后台操作,不影响更新时间;
可以看到k2 更新时,并没有修改内存或磁盘中的数据。那么此时有一个查询语句,系统该如何返回正确的值呢?
select * from t where k in (k1, k2);
- 读 Page 1 的时候,直接从内存返回。虽然磁盘上还是之前的数据,但是这里直接从内存返回结果,结果是正确的。
- 要读 Page 2 的时候,需要把 Page 2 从磁盘读入内存中,然后应用 change buffer 里面的操作日志,生成一个正确的版本并返回结果。(包含有change buffer 的 merge 过程)















 1418
1418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











