







 本文探讨了HANA数据库与ABAP SQL语法的不同,特别是在使用@转义字符、新旧SQL语法混用导致的错误以及新功能的引入。HANA简化了变量定义,支持类似Oracle的SQL运算,并允许在SELECT语句中使用CASE WHEN THEN等构造。此外,还介绍了如何处理字符串搜索、列合并以及变量定义的变化,展示了HANA如何向Oracle语法靠拢,提高代码效率。
本文探讨了HANA数据库与ABAP SQL语法的不同,特别是在使用@转义字符、新旧SQL语法混用导致的错误以及新功能的引入。HANA简化了变量定义,支持类似Oracle的SQL运算,并允许在SELECT语句中使用CASE WHEN THEN等构造。此外,还介绍了如何处理字符串搜索、列合并以及变量定义的变化,展示了HANA如何向Oracle语法靠拢,提高代码效率。
为啥要用@?
我的select 后面的字段用逗号分隔了:
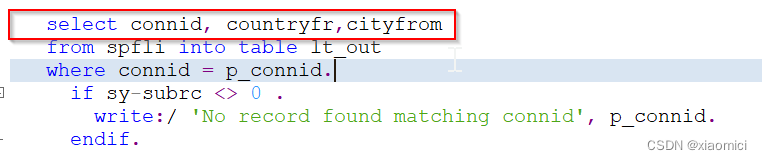
然后get了一个错:当用转义符时,所有主变量都得用@转义。

为啥呢,因为新旧SQL语法它不一样。
把新旧两种语法混合在一起就会有语法错误。
如果你用逗号分隔字段,那就是新open sql那主变量就得用@转义。
就是变量啊,工作区间啊,内表啊这些本地变量,如果逻辑用新SQL就得用@ 。用@ 来区分本地变量和外部变量。这个本地和外地我觉得就是方法内的变量和类的变量。但是也极大可能不是这个意思。
那么啥是新open SQL?我查了一下,发现它不就是和Oracle的SQL语句更接近了,有些功能可以用了。而且说为了代码下移做了优化啥的,具体不知道。来看看例子:
*20220608 就是HANA的SQL语法
文章目录
1. 用@转义
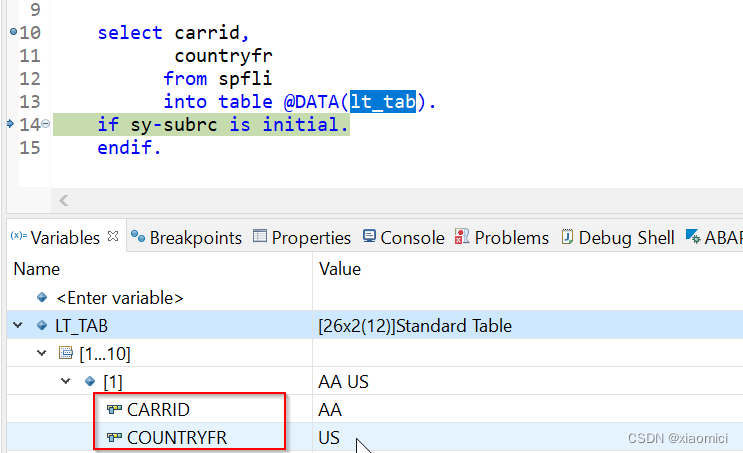
这个也就是个HANA和ABAP的变量定义不一样了。
如果用ABAP的变量定义,那么得统统定义一遍,但是这里对于内表的定义就只用@DATA,对于工作区间的定义就只是DATA了:
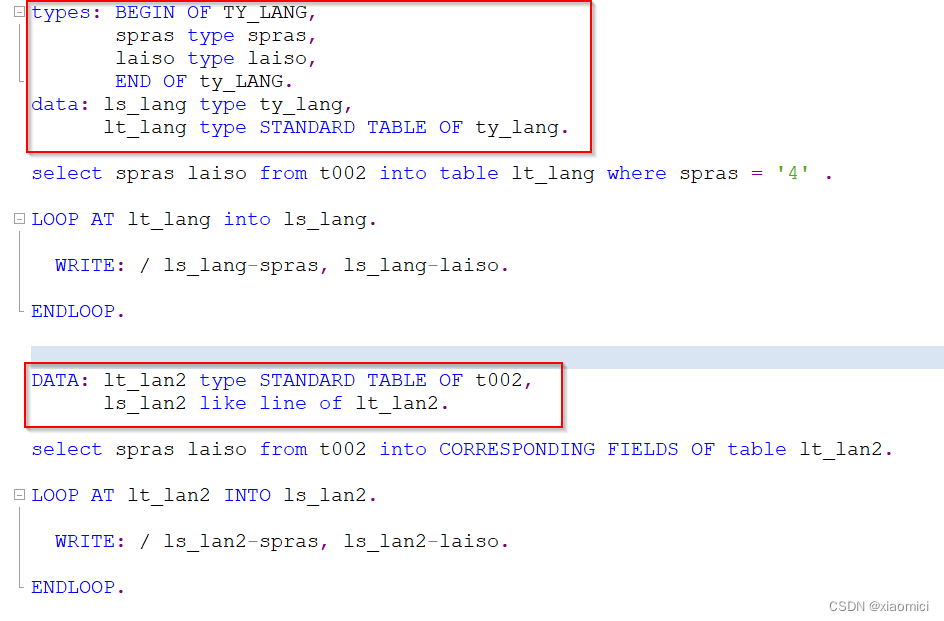
在HANA里面语法就直接变成了:
减少了很多条定义语句。
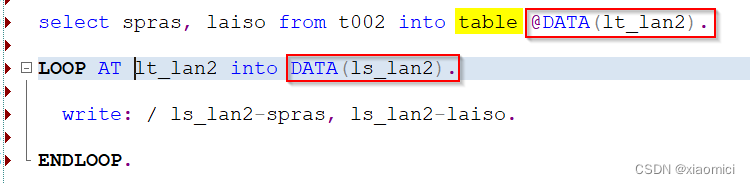
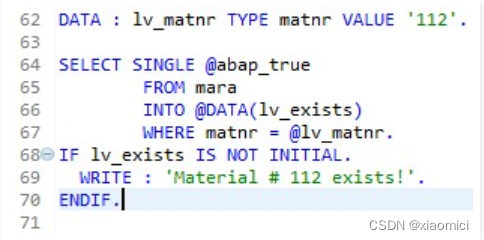
用常量检查,看是否存在条目。
这个ABAP_TRUE是个常量。类型boolean, 值X。
这个并没有去查啥,只是确定了matnr = 112的这条存在。这个常量值只为了确定这条。
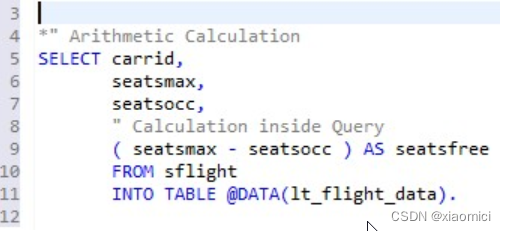
这种明显Oracle的加减乘除语句也可以用了。
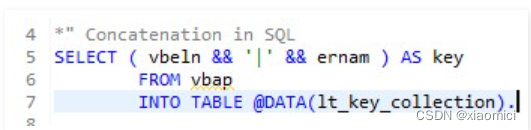
合并两列为一列作为KEY这个列名。新表也是只有Key这一列。一切向Oracle靠拢。
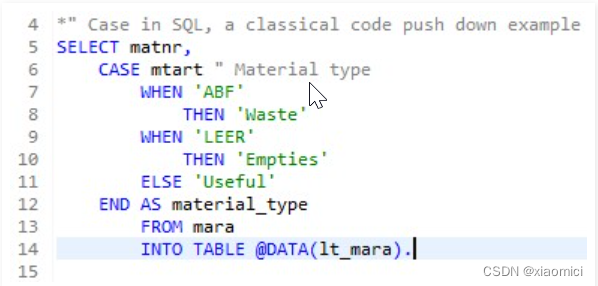
case when then的语句也能在select里面用了,给个列别名material_type. 这个case里的列分类最后放到material_type里了。直接在数据库层给你搞好了分类了。不用哼哧哼哧loop读表再改了。条条大路通罗马啊。
以下把search_term改成小写,还前后加了%通配符,为了能跟LIKE一起用。
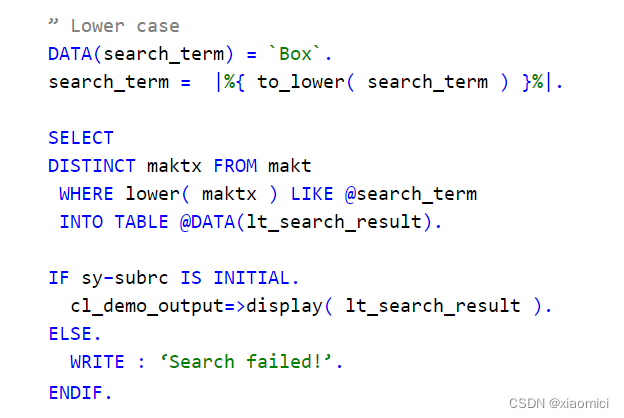
还有好多其他功能,感觉要重看一遍Oracle SQL语句。



















 517
517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











