






在数据分析和数据挖掘处理中常常会发现数据中存在重复值,因此需要对此进行处理。
工具:Pandas
数据如下:
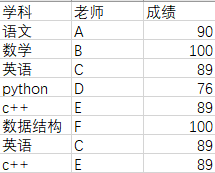
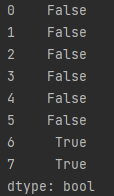
调用 对象.duplicated()函数可以对数据每一行进行重复性检测,结果如下:
调用 对象.drop_duplicates(inplace=True)函数可以删除数据中重复数据,其中参数inplace=True表示返回在原数据上进行删除,inplace=False则是对原数据不改动,只能用新变量来接收删除后的数据,结果如下:
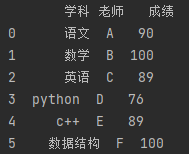
代码如下:
import pandas as pd
a=pd.read_excel('exam.xlsx',header=0)
a.drop_duplicates(inplace=True)
print(a)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











