






YOLOv3学习记录
目标检测的评价指标
一般分为速度指标(fps)和准确度指标(map)。
FPS
也就是帧数,这个就是算法每秒能够推断的图片的数量。如果比较这个指标的话,必须保证硬件相同,并且数据集之类的都完全一样。
map

这里面有两个阈值,一个是iou另外一个是置信度阈值。这两个阈值都是人工指定的。然后可以构造出如下的混淆矩阵(confusion Matrix)。



论文中是在iou比较小的时候,此时识别效果比较好,但是随着iou变大之后,效果就没有难么好了,这样说明YOLOv3针对比较精确的目标识别和定位效果并不是很好(精准定位能力比较差)。
论文中的一些机制
Bounding Box Prediction
这里应用了YOLOv2的方法,具体实现为:
YOLOv3为每个bounding box预测出4个坐标,分别是
t
x
t_x
tx
t
y
t_y
ty,
t
w
t_w
tw,
t
h
t_h
th,在加上一个置信度。
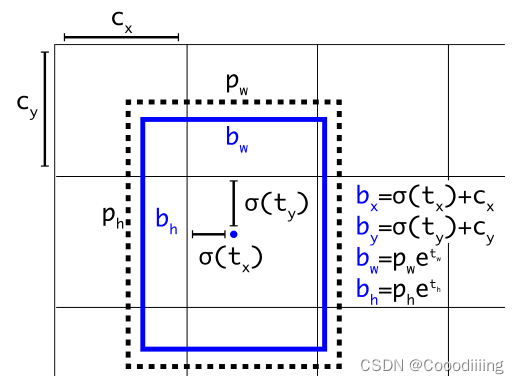
其中
c
x
c_x
cx,
c
y
c_y
cy分别表示负责产生bounding box的那个grid cell的左上角离整个图片左上角的宽和高。
p
w
p_w
pw,
p
h
p_h
ph分别表示真实物体所在框的宽和高。
通过公式计算得到
b
x
b_x
bx,
b
y
b_y
by,
b
w
b_w
bw,
b
h
b_h
bh分别是预测框的中心横坐标、纵坐标以及宽、高。
图中黑色的框是anchor,蓝色的是计算出来的预测框。之后用计算出来的预测框和真正的ground truth计算损失,然后进行梯度的反向传播。其实这里anchor的作用就是作为一个基准,更快的帮助网络收敛。如果没有anchor的话,在训练初期网络输出的值是随机的,这样就导致一开始训练的时候很不稳定,如果用了anchor,网络初期输出的值也相对比较稳定,这样网络收敛更快。
正负样本的概念
这里的正负样本主要是在计算损失函数的时候用到,有很多论文都是专门来研究正负样本的,其中很多算法中也用到了正负样本的概念。下面详细讲解一下YOLOv3中的正负样本是怎么用的。
正样本:如果标注框落中心坐标落在的那个grid cell里面,由这个grid cell产生的anchor和标注框求iou,其中iou最大的是正样本。(一个grid cell一共是产生9个anchor,每个尺度有三个,求这9个anchor中和ground truth的iou最大的那个作为正样本)(正样本只有一个,并且一定是由标注框中心点落在的那个grid cell产生的anchor),原文中是这样解释的,正样本是负责预测物体的。
负样本:计算所有grid cell产生的anchor和标注框的iou,求出来iou小于某个阈值的(人为设定,原文中用的是0.5),这种叫负样本。原文中解释,负样本是用来预测背景信息的。
其中有一部分的iou并不是最大的,但是也大于我们设定的iou阈值,对于这种anchor,不做处理。其中原理就是,这部分也包含一定的物体,并且包含的部分还不少(大于我们设定的那个阈值),所以这样看来,把这种当做正样本或者负样本来计算损失都不合适,因此不做处理。
正样本的置信度设置为1,负样本的置信度设置为0。
但是有些代码,在真正实现的过程中,选出来正样本后,直接将剩下的所有都当做负样本来处理的。
YOLOv3网络输出形状以及含义
YOLOv3相对于前两代YOLO的改进,实际上相当于多了一些预测框。YOLOv1的生成7 * 7 * 2(grid cell个数是49个,每个产生两个预测框) 个预测框。YOLOv2生成 13 * 13 * 5(一共169个预测框,每个对应5个anchor )个预测框。YOLOv3生成 13 * 13 * 3 + 26 * 26 * 3+ 52 * 52 * 3(3个尺度的grid cell,每个对应3个anchor)。 这样就改善了小目标和密集目标的检测结果。
由于YOLOv3整个网络中都没有全连接层,因此输入图像只要是32的倍数就可以。输入的尺寸越大,最终得到的grid size也越大,产生的预测框也就更多。
YOLOv3网络输出的形状为[batch_size,75,grid_cell,grid_cell] ,注意因为YOLOv3中用了三种不同的grid cell,分别是13,26,52,因此最终输出的是三个不同维度的Tensor。在计算损失的时候,根据grid cell的不同,每个Tensor对应的Anchors的大小也不同。因此也有三组Anchors,每组Anchor里面有三个Anchor。
其中每个维度所代表的含义如下:
1.batch_size
2.75:因为每个网格grid cell负责预测输出三个bounding box(为什么是三个?因为网络设计的是每组不同大小尺寸的anchors分别都有3个anchor,你在计算损失的时候,需要和这3个anchor匹配上才行),每个bounding box包含4个坐标信息和1个置信度,在加上每个类别的概率(该数据集一共有20个类别),(5+20) * 3=75。
这里的置信度在计算的时候,直接将正样本的置信度设置为1,这样也能提高精度。在YOLO前两个版本中,是用iou作为置信度的,这样有一个缺点就是,anchor本来就和ground truth的iou很小,比如说是0.6,用一个很小的数作为标签,不利于网络的收敛。
在计算损失的时候,会将这个75拆开,将真个pred的维度变为[batch_size,3,grid_cell,grid_cell,25]
这里每个类别的条件概率,都是分别由一个simgold函数输出的,并没有用softmax(默认所有的类别都是互斥的),这样的好处是可以同时输出很多个比较大的概率,可以处理一些特殊的数据集(比如说一个object的标签是person,同时可能还是man或者woman)。
3.grid_cell:yolov3中一个很重要的创新就是网络的输出一共有三部分,这三部分的根本区别就是grid_cell的大小不同,分别是13,26,52。这样设计的目的就是用不同大小的特征图去检测不同的物体,这样就能检测小目标的物体了。
损失函数的计算

YOLOv3的损失函数,图片来自B站同济自豪兄。
由于前面Bounding Box Prediction的预测出来的坐标值都是在0到1之间。那么在真正计算损失的时候,target和pred都是什么样子的呢?仔细阅读代码,发现是这样来实现的:
首先在原图中直接用cx,cy,真实框的宽和高,分别除以原图的宽和高,那么得到的这4个坐标信息,肯定都是在0-1之间的。在计算损失时候,因为需要确定真实的物体框落在哪一个grid_cell里面,所以直接让得到的0-1之间的坐标信息*对应特征图的宽和高(YOLOv3中也就是有13,26,52三种情况),假如的到的cx,cy坐标是6.2和7.3,那么就知道这个真实的框的中心点落在横着第6个竖着第7个grid_cell里面。以上操作就是为了确定,人工标注的框的中心点落在了哪一个grid cell里面。之后这个grid cell肯定对应着三个不同尺寸的grid cell分别是13 26 52,一共对应着9个anchor,用和人工标注框的交并比最大的那一个来预测真正的值,也就是作为下文提到的正例。
之后将对应大小的anchor也换成用grid cell来表示长和宽,然后分别求真正的ground truth和三个anchor的交并比,这里设置一个阈值,如果小于这个阈值,就将其设置为负例,将交并比最大的那一个设置为正例。
在真正计算损失的时候,让target中的cx和cy分别减去它对应的grid_cell的位置,那么就将坐标转换成了0-1之间的,就和pred中预测出来的0-1之间的坐标信息就一致了。
VOC2007数据集解析
该数据集既可以用来做语义分割又可以用来做目标检测。
该数据集共包含20个类别,训练集5011幅图片,测试集4952幅图片。
Annotations :放的都是xml文件存储图片的标注信息,主要包括图片的长、宽、深度(通道数为3)以及目标信息。目标的相关信息主要包括:目标信息具体是否被截断,是否难被识别,目标框左上角的横纵坐标和右下角的横纵坐标,以及目标类别信息。
ImageSets :图片类别标签
JPEGImages :图片本身
YOLOv3训练就采用该数据集,首先对xml数据进行读取,并解析成想要的格式,接着构建dataset以及dataloader。















 6855
6855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









