










串的模式匹配算法
暴力匹配
原理
从主串的指定的起始位置字符开始和模式第一个字符比较,如果相等,则继续比较下一个字符,如果不等,则从主串的下一个字符开始和模式的第一个字符开始比较,以此类推,直到模式串所有字符都匹配完成,则匹配成功,否则,匹配不成功

代码
#include <stdio.h>
#define MAXLEN 255
typedef struct {
char ch[MAXLEN];//从索引1开始存储
int len;
} SString;
//暴力匹配
int index(SString S, SString T, int pos) {
if (pos < 1 || pos > S.len) {
return 0;
}
int i = pos;
int j = 1;
while (i <= S.len && j <= T.len) {
if (S.ch[i] == T.ch[j]) {
i++;
j++;
} else {
i = i - j + 2;//i-(j-1)+1
j = 1;
}
}
if (j > T.len)
{
return i-T.len;
}
return 0;
}
时间复杂度的分析
我们这里只分析最坏的情况,那就是对于长度为n的模式串和长度为m的主串,模式串前n-1都是同样的字符而且主串的前m-1也是和模式串一样的字符,例如:模式串为:000001,主串为:000000000000000000000001,则对于这种情况的时间复杂度为:其中我们需要回朔:m-n+1次,每次都要比较:n次,所以我们的时间复杂度为:o((m-n+1)n)
KMP匹配
简介
KMP算法它是有Knuth、Morris和Pratt三个人同时发现的,所以我们称之为KMP算法。它是一个很优秀的算法,通过对模式串的一个预处理,将我们的时间复杂度减少到了一个线性的水平。
KMP算法精髓:利用已经匹配过的模式串的信息,求出next数组→利用next数组进行匹配(主串指针不回溯)
剖析算法的原理
下面我们将在实际的应用中来解释这个算法,首先我们有主串:acabaabaabcacaabc,有模式串:abaabc,现在假设我们匹配到了如下的图的步骤:

现在模式串的第六个字符和主串匹配不上了,那么现在我们就需要把模式串往右移动,并且重新选择主串和模式串的比较位置重新开始比较。那么如果是朴素法的话,我们是直接把模式串往右移动一格,然后,主串的第四个字符和我们模式串的第一个字符重新开始做比较。但是,你要知道其实主串的第三个字符到第六个字符我们都是已经和模式串做过比较的,而且我们知道他们的各个位置上的内容是什么,那么为什么不把这些已经知道的信息充分利用起来了?比如:我们知道模式串中红色的两个字符和绿色的两个字符是相等的,而且红色的两个字符正好是模式串开始的两个字符,所以我们可以直接把模式串向右移动四位,然后,我们主串从刚才发现不匹配那个字符位置开始和模式串的第三个位置比较,这样我们就可以减少五次比较。
哇噻,就是一个简单的处理,就给我们的程序效率带来了质的飞越,那么现在程序的最要紧要解决的问题就是我们主串比较位置不做任何改动,那么我们怎么知道该从模式串的哪个位置开始做比较了,这个时候,我们就需要对我们的模式串做一个预处理,通过预处理我们可得到一个next数组,它保存的就是当我们在模式串某个位置匹配失败后,应该从模式串的哪个位置重新开始比较。要求得next数组,那么我们就要理解刚才的那个例子为什么可以从模式串的第三个位置重新开始比较。其实next数组就是说对于模式串j这个位置之前(1到j-1)的串中,是否存在从模式串第一个位置出发往右移动得到的子串和从模式串的第j-1个字符位置出发往左移动得到的子串匹配,而且当该串达到最大长度时,则next值就是该串的长度加一,例如:abaabc这个模式串中,在c这个位置之前存在一个最大子串:ab。然后,我们next值就是记录这个最大子串的下一个字符的位置,其实说到这里,我们也就理解到了为什么要第三个字符了,因为模式串的前两个字符已经和主串匹配成功了(生成next值的时候,就完成了这个任务),所以不用再比较了。
next数组
用代码实现这个处理逻辑 可以用一个next数组来存储让模式串指针指向的位置

KMP算法:当子串和模式串不匹配时,主串指针 i 不回溯,模式串指针 j=next[j]。
复杂度分析
KMP算法最坏时间复杂度 O(m+n)
其中,求 next 数组时间复杂度 O(m)
模式匹配过程最坏时间复杂度 O(n)
代码
#include <iostream>
#define MAXLEN 255
using namespace std;
typedef struct {
char ch[MAXLEN];//从索引1开始存储
int len;
} SString;
//模式串为abaabc的next数组
int next[]={'\0',0,1,1,2,2,3};
//KMP匹配
int index_KMP(SString S,SString T,int next[]){
int i=1,j=1;
while(i<=S.len&&j<=T.len){
if (S.ch[i]==T.ch[j]||j==0){
i++;
j++;
}else{
j=next[j];
}
if (j>T.len){
return i-T.len;
}
return 0;
}
}
手算求next数组
不同类型的模式串,其对应的next数组也不相同
next数组的作⽤
当模式串的第 j 个字符失配时,从模式串的第 next[j] 的继续往后匹配

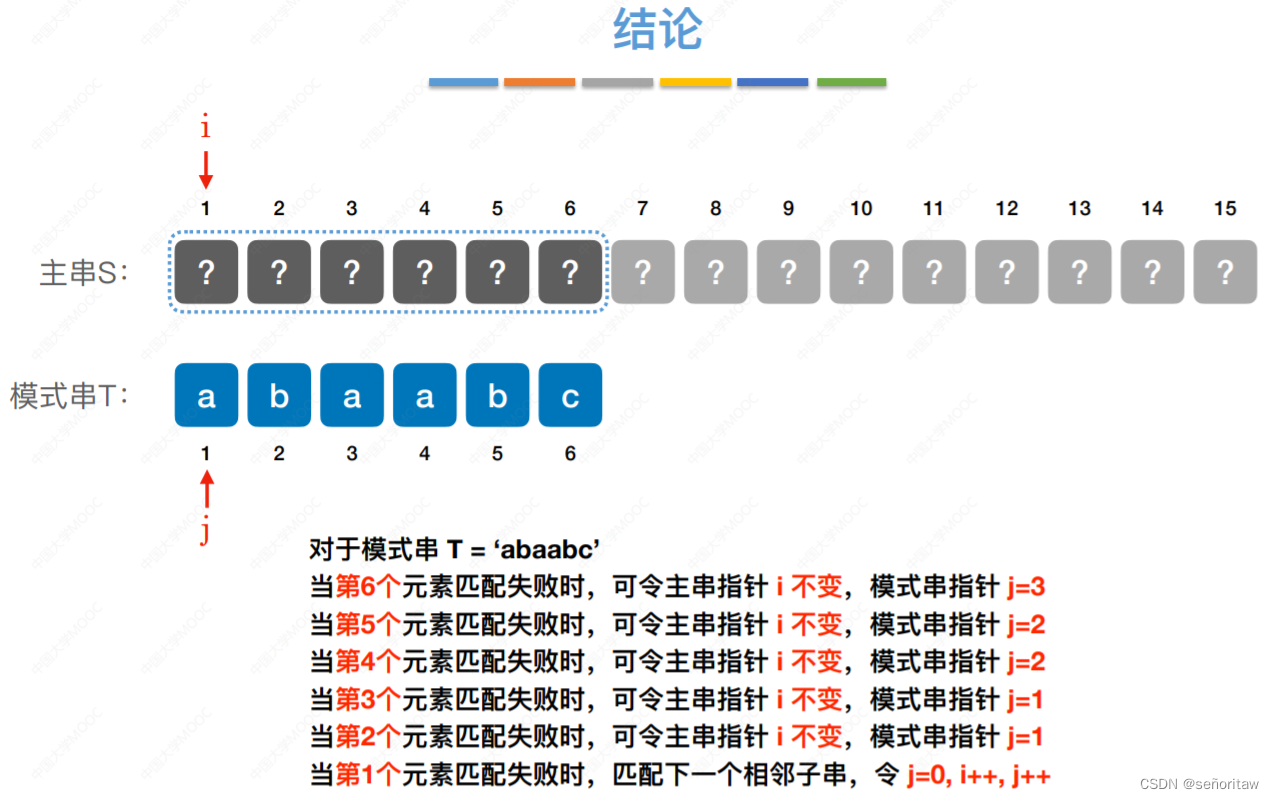
任何模式串第1个字符不匹配时,只能匹配下1个⼦串,因此,next[1]都⽆脑写 0
第2个字符不匹配时,应尝试匹配模式串的第1个字符, 因此,next[2]都⽆脑写 1
接下来的字符,在不匹配的位置前划一根分界线,模式串一步一步往后退,直到分界线前的“对的上”,或模式串完全越过分界线位置,如下面为第3个字符不匹配的情况

第四个字符不匹配

第五个字符不匹配

第六个字符不匹配

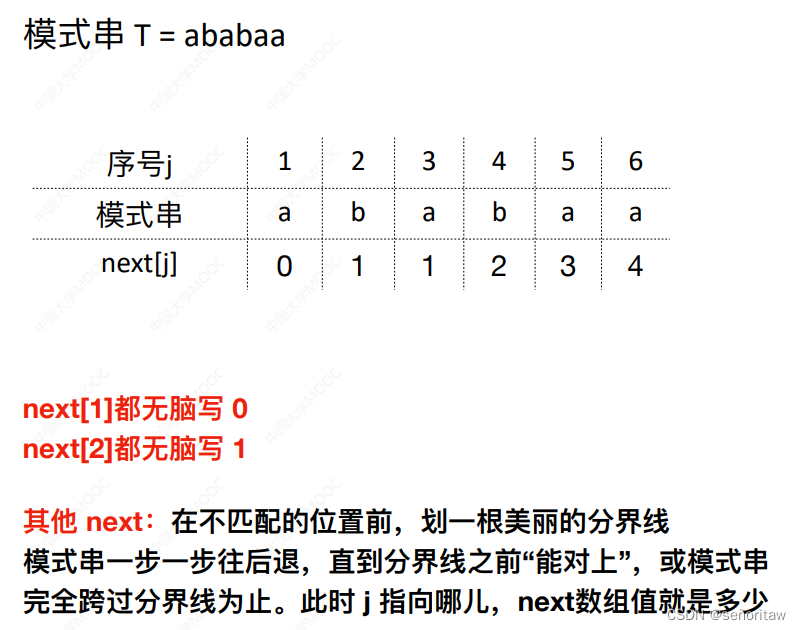
如

KMP算法优化——nextval数组
nextval数组
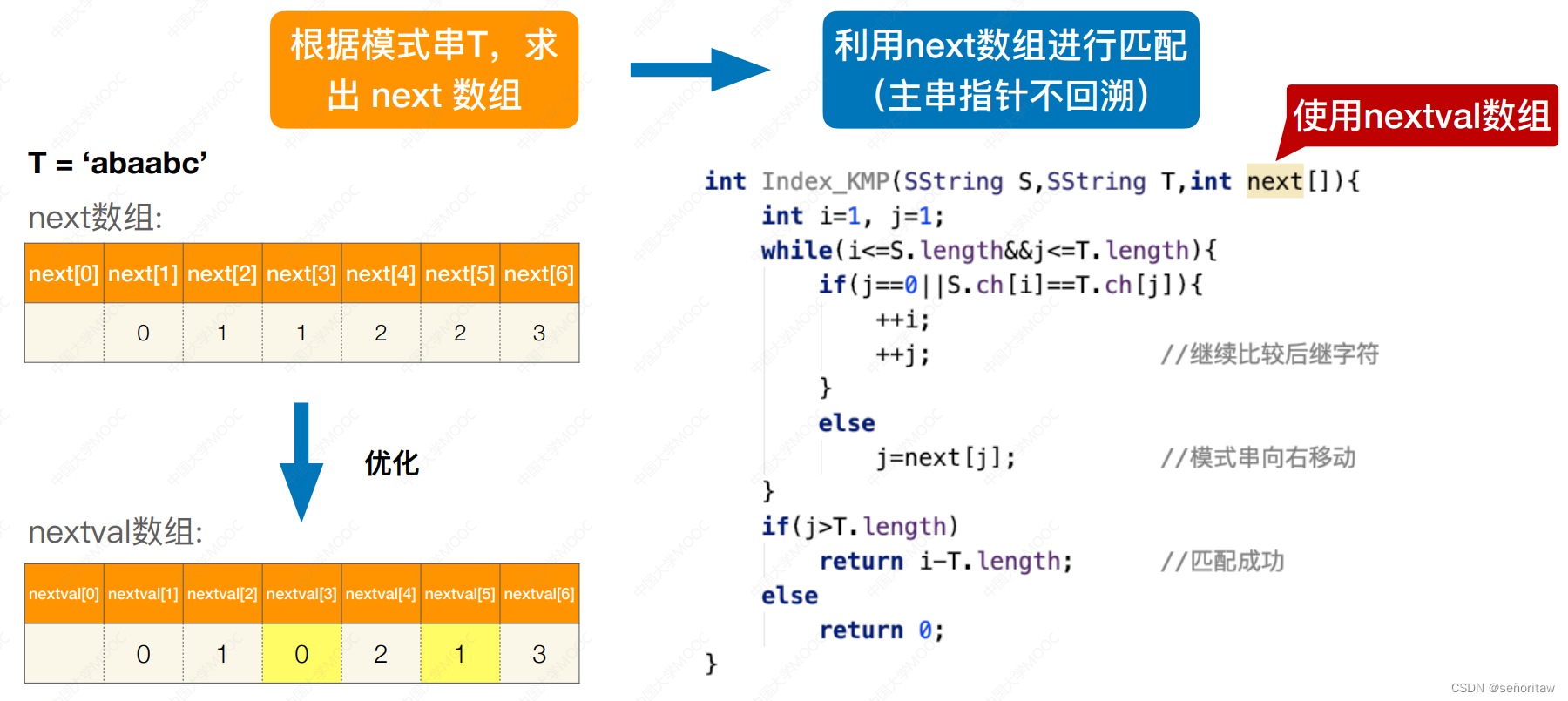
第3个字符和第1个字符相同,所以 可以直接跳到next[1]指向的位置,第5个字符跟第2个字符相同,直接跳到next[2]指向的位置
优化前后匹配代码不变,只改模式匹配数组,即将原next数组优化为nextval数组
手算求nextval数组
先求next数组,再求nextval数组
其中nextval[1]=0永远成立

















 3596
3596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









