






贪心算法其实就是没有什么规律可言,所以大家了解贪心算法 就了解它没有规律的本质就够了。
贪心本质是选择每一阶段的局部最优,从而达到全局最优。如果每步最优解不能保证到达全局最优,就不能用。
最好用的策略就是举反例,如果想不到反例,那么就试一试贪心吧。
解决优化问题。
饼干不能掰开。
解决方法:得先满足胃口小的孩子,所以得排序;要用双指针的办法的话,指针一直往前走,g不排序不行,比如:g=3,2,1;s=1,2,3。
所以都排序,遇到可满足的就count++,i++;j++。遇到不可满足的就看下一块饼干:j++。
class Solution {
public:
int findContentChildren(vector<int>& g, vector<int>& s) {
int i=0,j=0,count=0;
sort(g.begin(),g.end());
sort(s.begin(),s.end());
for(int j=0;j<s.size()&&i<g.size();++j){
if(s[j]>=g[i]){
count++;
i++;
}
}
return count;
}
};
认为边上2个一定是 是错的,比如[0,0,0]
class Solution {
public:
int wiggleMaxLength(vector<int>& nums) {
if(nums.size()==1)return 1;
if(nums.size()==2 &&nums[0]==nums[1])return 1;
int count=2;//边上2个一定是
//统计有几个极值
for(int i=1;i<nums.size()-1;++i){
int l=nums[i]-nums[i-1];
int r=nums[i]-nums[i+1];
if(l*r>0)count++;;
}
return count;
}
};可以发现:
![]()
没解决好:元素相等的情况——wrong.

总的:不要先统计两边的,先统计前两个因为pre计算前2个的。
pre是上一个升降,cur是下一个。
只会统计升降,也就是cur大于小于的情况,等于的话是跳过的。所以:极值数==升降数+1(这个1开头就加了, int count=pre==0?1:2;这里),后面就统计剩下的升降数。找规律:从[2,】开始,两相邻数之差不为0就是一个升/降,这样就可以统计+1了吗?不行,如果pre(前一个趋势和cur是一样的,只能算是一个升降,pre是已经统计过的,所以得跳过),只有当pre和cur的趋势不一致(pre>0且cur<0||pre<0且cur>0)才能+1;而且初始的pre还有可能为0(之后的pre不可能是0),pre为0 的时候如果cur是升降,也需要统计+1,所以总的条件就是下面的if。
class Solution {
public:
int wiggleMaxLength(vector<int>& nums) {
if(nums.size()==1)return 1;
int pre=nums[1]-nums[0];//pre和cur指向的区间趋势相反
int count=pre==0?1:2;//不相等为什么可以是2——因为把第二个替换成极值
//从[2,统计有几个极值——几个升降
for(int i=2;i<nums.size();++i){
int cur=nums[i]-nums[i-1];
if((cur>0 && pre<=0)||(cur<0 && pre>=0)){//发现一个和pre相对的升降
pre=cur;
count++;
}
}
return count;
}
};所以,不光是发现升降,要发现一个和pre相对的升降。
还记得一刷的一点印象,sum一直加上元素,如果sum<0了直接sum重置为0。还要设一个maxSum,统计循环里面sum的最大值,注意取最大值要在sum重置为0的前面,因为结果也可以是负数的。
class Solution {
public:
int maxSubArray(vector<int>& nums) {
//if(nums.size()==1)return nums[0];
int sum=0,maxSum=INT_MIN;
for(int i=0;i<nums.size();++i){
sum+=nums[i];
maxSum=max(maxSum,sum);
if(sum<0){
sum=0;
}
}
return maxSum;
}
};时复O(n);空复O(1)
是专注于自己这个元素,如果前面加上自己比自己还小,那就干脆不加前面的(也就是sum重置)。

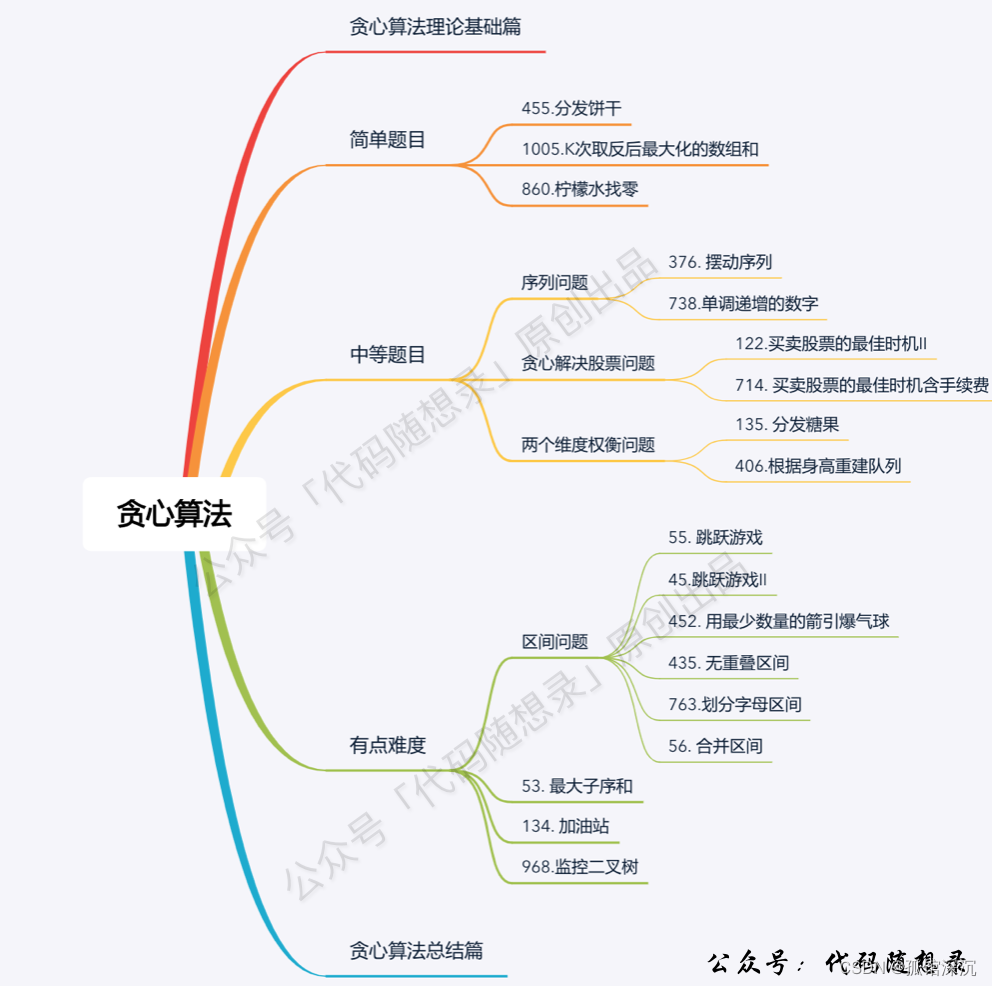
还记得,跟上面的有点像。我站在上帝视觉,知道明天和今天的股票,所以每天都会试试水,尝试今天买入和明天卖出,如果赚了(chajia>0),就这样做。如果不赚,就不做。
所以count只会加上相邻2天是可以赚到(>0)的差价,就只会往越来越多的趋势走。体现贪心思想:局部最优推全局最优

代码:
class Solution {
public:
int maxProfit(vector<int>& prices) {
int count=0;
for(int i=1;i<prices.size();++i){
int chajia=prices[i]-prices[i-1];
if(chajia<0)continue;
else count+=chajia;
}
return count;
}
};就下面的思想:
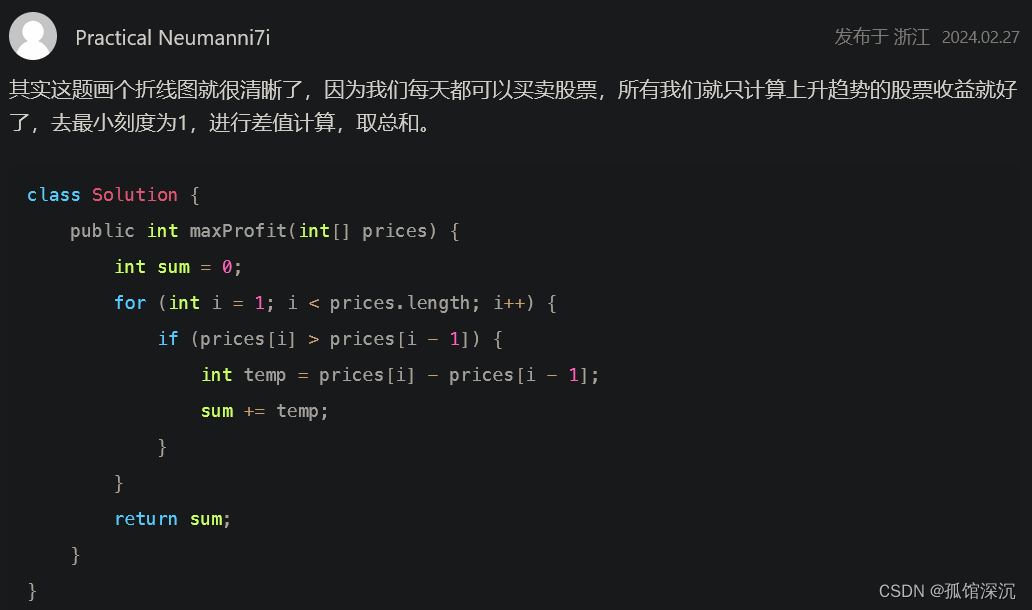
因为只要知道能不能跳到最后,所以看最大覆盖范围能不能到最后就行。
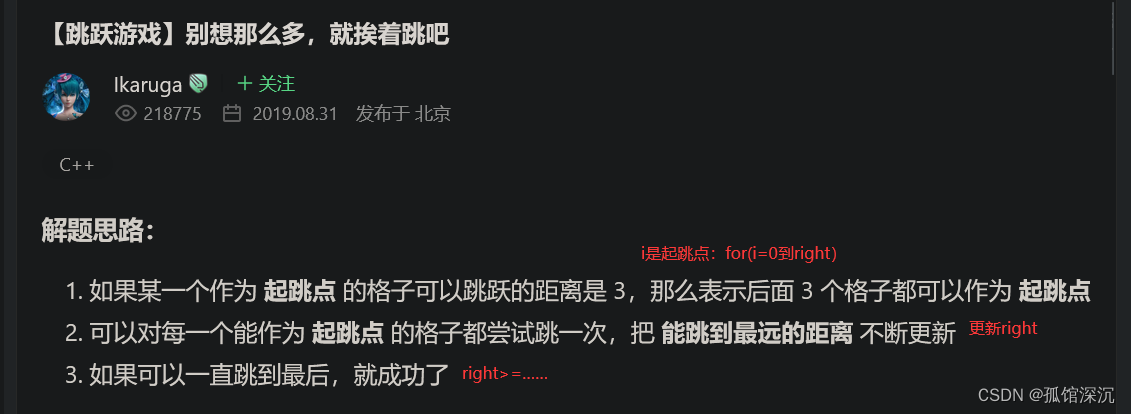
1、最后的right(覆盖范围)≥最后的位置就可以返回true。
class Solution {
public:
bool canJump(vector<int>& nums) {
int right=nums[0];//覆盖范围
for(int i=0;i<=right;++i){//挨着跳
right=max(right,i+nums[i]);
if(right>=nums.size()-1)return true;
}
return false;
}
};2、
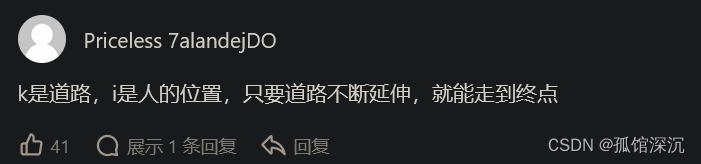
class Solution {
public:
bool canJump(vector<int>& nums) {
int k = 0;
for (int i = 0; i < nums.size(); i++) {
if (i > k) return false;
k = max(k, i + nums[i]);
}
return true;
}
};
作者:Ikaruga
链接:https://leetcode.cn/problems/jump-game/solutions/24322/55-by-ikaruga/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。要得到最小跳跃次数。怎么从上面的基础上来做。
次数最小就是要求一次尽量跨最大步。
1、所以一种反向的思路是: i 从0开始,往后看(i++)有没有坐标i能走到right位置,如果可以,第一个遇到的坐标i和right肯定是距离最大,这个时候可以count++,然后更新right值(目标位置),而且又要重复这个过程,即把i重置为0。
class Solution {
public:
int jump(vector<int>& nums) {
int count=0,right=nums.size()-1;
for(int i=0;i<right;){
if(nums[i]>=right-i){
right=i;
count++;
i=0;
}
else {
i++;
}
}
return count;
}
};但是有点慢,因为如果是[1,1,1,1,1,1]这样的输入,时间复杂度退化到O(n^2),所以想一下一趟线性时间就能搞定的方法。
2、正向:
和上面一样,记录能到达的最大边界right。然后i在这个边界里面(0到right)找下一步能走的最大步,
但是什么时候count++?right更新下一步还不能加。
要在设置一个变量cur,代表这一步能到达的边界,当走到这个边界(i==cur)的时候,就是走了最大的一步,这个时候count++。然后走下一步,cur则更新为maxPos,所以maxPos记录的是下一步能到达的边界。
如果cur更新之后,边界值超过了nums边界,就可以返回了。
class Solution {
public:
int jump(vector<int>& nums) {
if(nums.size()==1)return 0;
int count=0;
int maxPos=0;//下一步可到达的边界
int cur=0; //这一步可到达的边界
for(int i=0;i<nums.size();++i){
maxPos=max(maxPos,i+nums[i]);//步子尽量跨大
if(i==cur){
count++;
cur=maxPos;
if(cur>=nums.size()-1)return count;
}
}
return count;
}
};
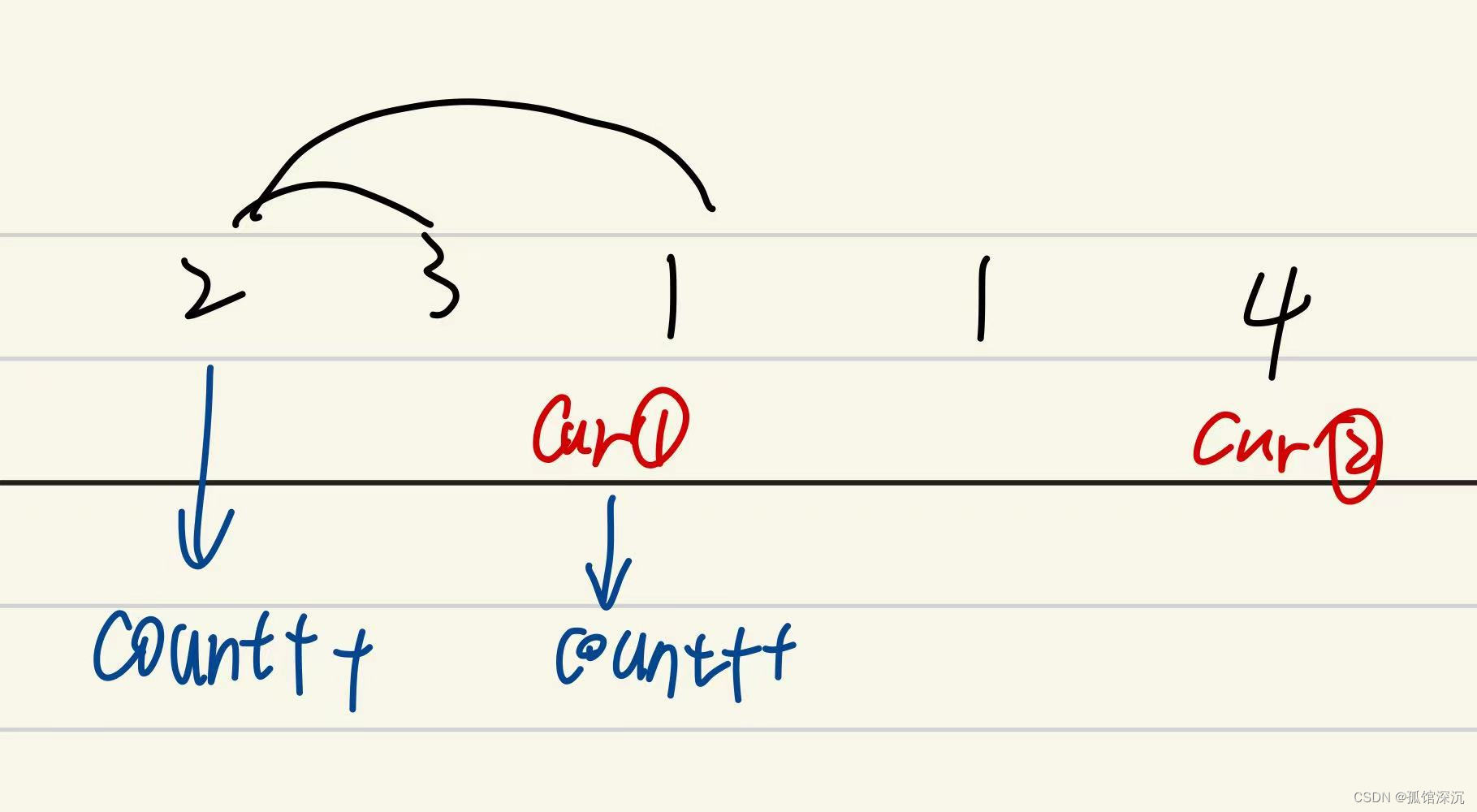
应该先按照绝对值从大到小排,然后遍历每个元素,把遇到的≤k个的负数都取反再加:非负数正常加。然后如果负数都取反了k还不为0而且是奇数,就把绝对值最小的那个非负数取反再加(因为可以可以多次选择同一个下标)。这样保证前面取反的是绝对值较大的一些负数,加起来最大,最后取反的是绝对值最小的那个非负数,减小的最少。综合是最大值。
class Solution {
public:
static bool cmp(int a,int b){
return (abs(a)>abs(b));
}
int largestSumAfterKNegations(vector<int>& nums, int k) {
int sum=0,i=0;
sort(nums.begin(),nums.end(),cmp);
for(int i=0;i<nums.size()-1;++i){
if(k>0 && nums[i]<0){
sum-=nums[i];
k--;
}
else{
sum+=nums[i];
}
}
if(k>0&&k%2==1)sum-=nums.back();
else sum+=nums.back();
return sum;
}
};力扣官方使用了map来做,再看看:
class Solution {
public:
int largestSumAfterKNegations(vector<int>& nums, int k) {
unordered_map<int, int> freq;
for (int num: nums) {
freq[num] += 1;
}
int ans = accumulate(nums.begin(), nums.end(), 0);
for (int i = -100; i < 0; ++i) {
if (freq[i]) {
int ops = min(k, freq[i]);
ans += (-i) * ops * 2;
freq[i] -= ops;
freq[-i] += ops;
k -= ops;
if (k == 0) {
break;
}
}
}
if (k > 0 && k % 2 == 1 && !freq[0]) {
for (int i = 1; i <= 100; ++i) {
if (freq[i]) {
ans -= i * 2;
break;
}
}
}
return ans;
}
};
作者:力扣官方题解
链接:https://leetcode.cn/problems/maximize-sum-of-array-after-k-negations/solutions/1134002/k-ci-qu-fan-hou-zui-da-hua-de-shu-zu-he-4r5lb/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。用一次遍历来做,如果穷举所有位置然后走一圈,会超时。
优化的办法就是:

即:因为x可以到y+1前面的位置,剩余油量总是>0,但是到y+1就没有油了,说明这一段路把之前到y剩下来的油都能用完,那么肯定,从(x,y]之间任选一个点,走到了y的时候剩余油量比之前x开始的时候还少,再走[y,y+1]这段路肯定更不够。所以只能从y+1开始了。
找这个起点的循环,只用 从头到尾 顺序找就行了,因为假如找到一个start,能跑到结尾,但是不能跑一圈,当且仅当(maybe吧)总的汽油值是小于总的cost值的。所以用一个totalSum记录从0到结尾的 汽油总值减去cost总值,如果不够返回-1。如果>=0就肯定最后找到的start就是正确答案。
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
int totalSum=0,curSum=0,start=0;
for(int i=0;i<gas.size();++i){//从左到右,不用掉头
totalSum+=(gas[i]-cost[i]);//totalSum的作用
curSum+=(gas[i]-cost[i]);//起点start到结尾的剩余
if(curSum<0){//直接下一个开始
start=i+1;
curSum=0;
}
}
if(totalSum<0)return -1;
return start;
}
};
力扣官方题解:从start开始,往后从0累加curSum,<0的话会break;经过的站==n了也会退出内循环。
所以内循环外面判断如果是经过了n站了说明能走一圈所以直接返回start起点;否则就是break导致出循环,那么根据上面的原理更新start为下一个位置。
这里有走一圈的循环(i),没有用上面totalSum的原理。
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
int start=0;
int n=gas.size();
while(start<n){ //找起点
int zhan=0; //zhan:经过了几站
int curSum=0;
while(zhan<n){
int i=(start+zhan)%gas.size();//遍历[start,]的
curSum+=(gas[i]-cost[i]);
if(curSum<0)break;
zhan++;
}
if(zhan==n){//找到,可以走一圈
return start;
}
else //从start走不到start+zhan。
{
start=start+zhan+1;
}
}
return -1;
}
};
一刷的时候采用的办法:分两遍处理,先从左往右处理<的。再从右往左处理>的。
处理操作是:如果自己比 左边/右边 大 但是分到的糖果不是更大(if)就更新为更大(更新数组元素),要求 最少糖果数 所以比 左边/右边 大 一个就行。
class Solution {
public:
int candy(vector<int>& ratings) {
vector<int> result= vector<int>(ratings.size(),1);
for(int i=1;i<ratings.size();++i)
{
if(ratings[i]>ratings[i-1]&&result[i]<=result[i-1])result[i]=result[i-1]+1;
}
for(int i=ratings.size()-2;i>=0;--i)
{
if(ratings[i]>ratings[i+1]&&result[i]<=result[i+1])result[i]=result[i+1]+1;
}
int sum=0;
for(auto a:result){
cout<<a<<endl;
sum+=a;
}
return sum;
}
};但是时间开销大,遍历了两遍。而且空间复杂度O(n)。
这也是力扣官方题解方法一:两次遍历

但是为啥这样是最少的?不清楚

法2:
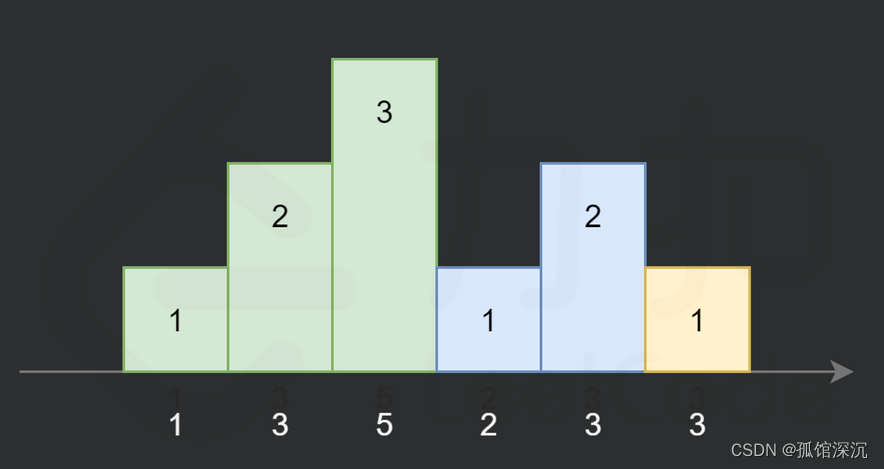
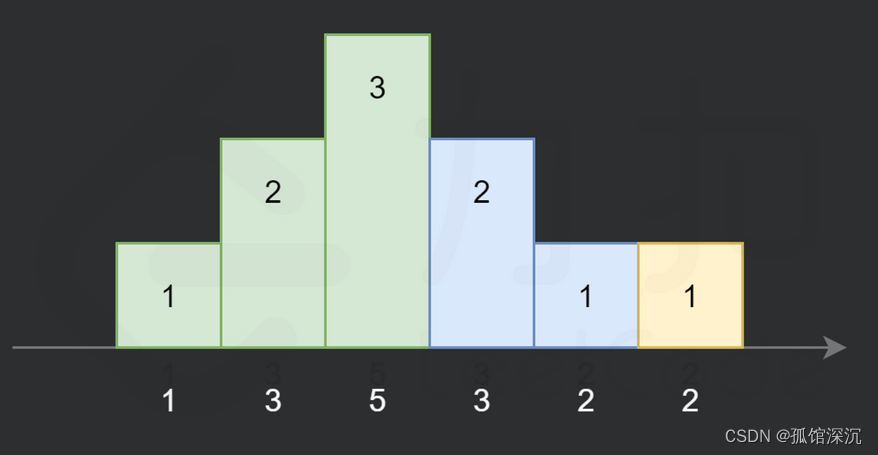
对上图修改一下:
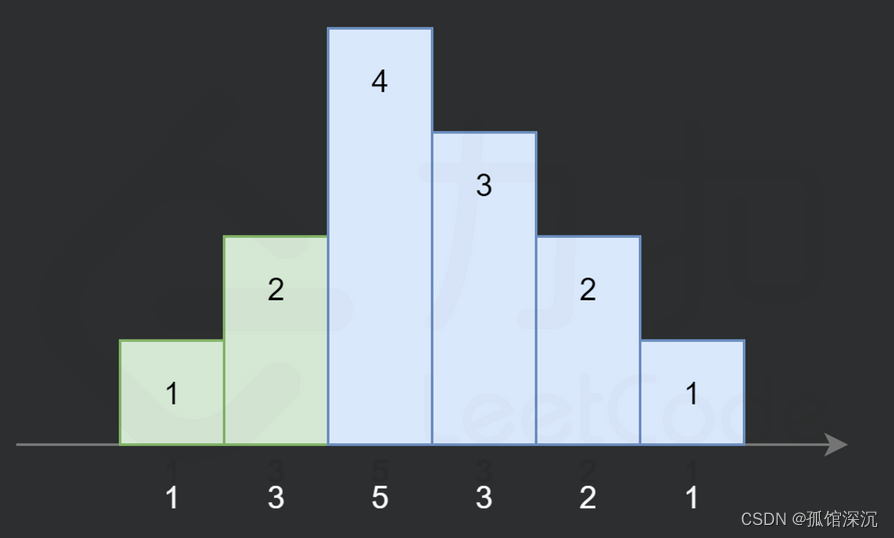
这个5就要并入递减序列里面算才对。这说明了一种特殊情况,红框的话:
总的:参考评论

这里pre代表i 及 i 前面,递增序列的最后的数。所以遇到递减序列,pre就得重置为1.然后递减序列长度dec++;如果发现==inc了,对应特殊情况,所以dec还得+1,这样把递增递减中间的峰值划到递减序列;最后就给目前的和之前 的递减序列里面的都+1(效果等同+dec本身)。
遇到非递减序列,dec得重置为0.pre是什么?目前递增序列的最后的数,所以更新pre。把>=2个情况写一起的。然后结果加上这个pre——i位置的糖果数(加inc也可以,因为都从1开始加)。最后inc更新——不是直接++,而是等于pre——因为递增和等于的情况一起写的。
class Solution {
public:
int candy(vector<int>& ratings) {
int n = ratings.size();
int ret = 1;//最少糖果数目
int inc = 1, dec = 0, pre = 1;
for (int i = 1; i < n; i++) {
if (ratings[i] >= ratings[i - 1]) {
dec = 0;
pre = ratings[i] == ratings[i - 1] ? 1 : pre + 1;//更新i位置的糖果数
ret += pre;
inc = pre;
} else {
dec++;
if (dec == inc) {//要把最近的递增序列的最后一个同学也并进递减序列中。递减序列++
dec++;
}
ret += dec;//为什么+dec?
pre = 1;
}
}
return ret;
}
};
为了更好的理解,尝试把>=分开并且inc用++来实现,但是有的例子不能通过。
class Solution {
public:
int candy(vector<int>& ratings) {
int n = ratings.size();
int ret=1;//0下标糖果
int dec=0,inc=1,pre=1;//第一个算递增里面
for(int i=1;i<ratings.size();++i){
if(ratings[i]>ratings[i-1])//≥放一起写
{
pre++;//用pre更新i的糖果数
inc++;
dec=0;//不再连续递减
ret+=pre;
}
else if(ratings[i]<ratings[i-1])
{
dec++;
if(dec==inc){
dec++;
}
ret+=dec;
pre=1;
}
else
{
pre=1;//用pre更新i的糖果数
inc=1;
dec=0;//不再连续递减
ret+=pre;
}
}
return ret;
}
};

class Solution {
public:
bool lemonadeChange(vector<int>& bills) {
int five=0,s=0;
for(int i=0;i<bills.size();++i){
if(bills[i]==5){
five++;
}
else if(bills[i]==10){
if(five>0){
five--;
s++;
}
else return false;
}
else{//20
if(s>0&&five>0){
s--;
five--;
}
else if(five>2){
five-=3;
}
else return false;
}
}
return true;
}
};浏览评论找到代码可以直接把上面过程浓缩成一行:?:语法代替if-else结构:
class Solution {
public:
bool lemonadeChange(vector<int>& bills) {
return all_of(bills.cbegin(), bills.cend(), [a = 0, b = 0](int i)mutable { return i==5?++a:i==10 ? (++b,a--) : b ? (b-- && a--) :((a -= 3)>-1); });
}
};all-of函数里面用Lambda表达式。这行代码前++后++好像不能随便定,否则出错。
和分发糖果类似,不要两头兼顾,处理好一边再处理另一边。

前面刚好有ki个,那先进行排序,希望得到排序完之后的people是:序列里面的每个人的前面所有人都比自己高,或者相等,相等的话前面那个序号较小,这样的话从左到右,每个元素直接插入到位置是ki的地方,就能保证前ki个都是比自己高的了。
要保证最后结果这个身高得是从大到小的,所以当身高相等的时候,序号得从小到大,身高不相等的话就从大到小排好。
cmp实现:
static bool cmp1(vector<int> vec1,vector<int> vec2){
if(vec1[0]==vec2[0])return vec1[1]<vec2[1];
return vec1[0] > vec2[0];
}如果先插入i处元素,再删除,最后一个元素不会是对的。
for(int i=0;i<people.size();++i){
people.insert(people.begin()+people[i][1],vec);//insert和erase位置都得是迭代器
people.erase(people.begin()+i);
}其实原地修改操作不太方便,先插入再删除还是反过来都是。
所以还是用一个辅助空间,辅助空间也定义为 vector<vector<int>> 吗。vector底层是普通数组实现的。vector的容量capacity预先设定为1,size到了capacity之后,这个capacity就会增加到原先的两倍(或者其他倍),所以用vector做插入效率不高。增删时间复杂度低的数据结构是链表,所以用链表来访结果进行好一些。
list容器放正确顺序的结果。注意链表不能随机访问,所以插入的时候要确定迭代器的位置,而不能用插入位置不能用begin()+下标。
class Solution {
public:
static bool cmp1(vector<int> vec1,vector<int> vec2){
if(vec1[0]==vec2[0])return vec1[1]<vec2[1];
return vec1[0] > vec2[0];
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort(people.begin(),people.end(),cmp1);
list<vector<int>> result;
for(int i=0;i<people.size();++i){
list<vector<int>>::iterator it=result.begin();
int pos=people[i][1];
while(pos--){
it++;//确定插入位置
}
result.insert(it,people[i]);//插入
}
return vector<vector<int>>(result.begin(),result.end());
}
};时间:排序O(nlogn),插入O(n^2)。总的O(n^2)。
空间复杂度O(n)。
当然也可以用vector放结果,更简洁:
class Solution {
public:
static bool cmp1(const vector<int>& vec1,const vector<int> &vec2){
if(vec1[0]==vec2[0])return vec1[1]<vec2[1];
return vec1[0] > vec2[0];
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort(people.begin(),people.end(),cmp1);
vector<vector<int>> result;
for(const vector<int>& person :people){
result.insert(result.begin()+person[1],person);//插入到result的person[1]下标处
}
return result;//vector<vector<int>>(result.begin(),result.end());
}
};参数和上面一样的结构,感觉首先需要排序。
第一个元素从小到大排比较直观(习惯从左到右)。

所以遍历的cur气球就会有上面3种情况:左边界小于 上一个射出的弓箭 可覆盖的右边姐①②;大于……③。如果是①②。上一个弓箭还能接着用,但是弓箭射出位置在情况①得变化,总的就是选择上面右边界和cur右边界的最小值;如果是③,就得使用新的弓箭,但是弓箭射出位置应该选左边还是右边呢?应该是右边,右边才能尽可能多的覆盖其他没有遍历到的气球。

所以弓箭数count一旦增1,射出位置就是:(这里原本引爆的气球就是新射出的弓箭可以因报的气球)注意红框。

class Solution {
public:
static bool cmp(const vector<int> &v1,const vector<int> &v2)
{
return v1[0]<v2[0];
}
int findMinArrowShots(vector<vector<int>>& points) {
sort(points.begin(),points.end(),cmp);
int count=0;
int pre=INT_MIN;//上只箭射出的位置
for(const vector<int>& point:points)
{
if(point[0]>pre ){//必须再用1只箭
count++;
pre=point[1];
}
else pre=min(pre,point[1]);
}
return count==0?1:count;//有一个例子比INT_MIN小所以这样写
}
};最后的return 这样写是为了:

时间复杂度:O(nlogn)。排序决定
空间:O(logn)。排序决定。
和下面几题都是重叠区间 问题
注意到如果排序第二个元素(右边界的话),下一个区间右边界肯定比pre大,所以只有②③两种情况,②的话不需要新箭,射出位置本来就是要选最小的,原本的就是最小的,所以不用更新;③需要新箭,射出count++,然后更新射出位置。
class Solution {
public:
static bool cmp(const vector<int> &v1,const vector<int> &v2)
{
return v1[1]<v2[1];
}
int findMinArrowShots(vector<vector<int>>& points) {
sort(points.begin(),points.end(),cmp);
int count=0;
int pre=INT_MIN;//上只箭射出的位置
for(const vector<int>& point:points)
{
if(point[0]>pre ){//必须再用1只箭
count++;
pre=point[1];
}
}
return count==0?1:count;
}
};可以直接用上题的方法来做,要 求 移除区间 的 个数,可以间接求不重复区间(剩余区间)有几个,总数减去不重复区间 ,结果就是 移除区间 的个数。
剩余区间 之间的边界可以重合,所以和上面不一样的是,元素左边界 等于curRight的时候也得算做一个:
class Solution {
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
sort(intervals.begin(),intervals.end(),[](const vector<int>& v1,const vector<int>& v2){return v1[0]<v2[0];});
int count=1;
int curRight=intervals[0][1];
for(int i=1;i<intervals.size();++i)
{
if(intervals[i][0]>=curRight){
count++;
curRight=intervals[i][1];
}
else curRight=min(curRight,intervals[i][1]);
}
return intervals.size()- count;
}
};和上题同理排序右边界的话不用else条件:
class Solution {
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
sort(intervals.begin(),intervals.end(),[](const vector<int>& v1,const vector<int>& v2){return v1[1]<v2[1];});
int count=1;
int curRight=intervals[0][1];
for(int i=1;i<intervals.size();++i)
{
if(intervals[i][0]>=curRight){//计算新的重复区间
count++;
curRight=intervals[i][1];
}
}
return intervals.size()- count;
}
};和上面的是一个道理。要选择的位置是:原本引爆气球(这里是多个重复区间中)中最靠左的右边界位置。
需要知道每个字母的最后一次出现的下标位置,可以用map,也可以用数组来映射(因为s 仅由小写英文字母组成)
也是要不断更新右边界:

上述做法使用贪心的思想寻找每个片段可能的最小结束下标,因此可以保证每个片段的长度一定是符合要求的最短长度:要是更短的话,同一个字母会出现在不同序列里面。
下面是不用辅助空间实现的,但是很慢。因为找最少结束下标瑶遍历来找(j从后往前),时间复杂度O(n^2)
class Solution {
public:
vector<int> partitionLabels(string s) {
vector<int> result;
int start=0,maxRight=INT_MIN;
for(int i=0;i<s.size();++i)//字母最后出现的位置
{
int j=s.size()-1;
for(;j>=i;j--)
{
if(s[j]==s[i])break;
}
maxRight=max(maxRight,j);
if(maxRight==i)
{
result.push_back(i-start+1);
start=i+1;
}
}
return result;
}
};所以用辅助空间,数组实现,两次遍历:第一次遍历不断更新获得每个字母的最后位置;第二次遍历检查下标end值,找到则添加到result……时间复杂度O(n)
class Solution {
public:
vector<int> partitionLabels(string s) {
vector<int> result;
int start=0,end=INT_MIN;
int last[26];
for(int i=0;i<s.size();++i)//字母最后出现的位置
{
last[s[i]-'a']=i;//最后更新的就是最后下标位置
}
for(int i=0;i<s.size();++i)
{
end=max(end,last[s[i]-'a']);
if(end==i)//当前片段访问结束
{
result.push_back(i-start+1);
start=i+1;
}
}
return result;
}
};用int数组做银蛇比map更省空间和时间,因为这里key值就26个,而且key值(a-z)可以映射到0-25(s[i]-'a'),所以 再以这个值 作为下标,再映射到下标 i 去。
仍然和射箭/无重叠区间 是一类题:先排好序(这里排v1[0],所以当新的区间出现直接start赋值下一个的左边界intervals[i][0]就好)。
[start,end]记录一个合区间,当下一个区间的左边界脱离这个合区间了(>end),就需要把旧的合区间收集记录下来;否则需要更新end值(v1[1]没有排;得取较大值来延伸这个合区间)。
最后还要收集一下最后的合区间:
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
vector<vector<int>> result;
sort(intervals.begin(),intervals.end(),[](const vector<int>& v1,const vector<int>& v2){return v1[0]<v2[0];});
int start=intervals[0][0];
int end=intervals[0][1];
for(int i=1;i<intervals.size();++i)
{
if(intervals[i][0]>end)//新的区间
{
result.push_back({start,end});//收集旧的区间
//更新为新的区间
start=intervals[i][0];
end=intervals[i][1];
}
else end=max(intervals[i][1],end);
}
result.push_back({start,end});
return result;
}
};和上面不一样的就是这里end记录最右边界得取最大值(并的思想,这个最大值是一个合区间能到的最远处),而上面两道题是取最小值(交的思想,这个最小值涵盖一个count代表的所有区间,即一个count代表的所有区间的右边界的最小值)
是两位数的话,假设ab:a>b,那么符合条件的数就是(a-1)9,即把个位变成9,十位变成1。到一般情况:n位数,x1 x2 …… xn。如果xi > xi+1,仅仅把后一位xi+1变成9,前一位xi-1——那么xi+1到xn不会满足单调递增。所以只要发现有一对是单调递减的,就要记录下来。每次找到一个开始下降的一对,前面的-1后面的置9,数字又变化,所以还得往前检查,直到左边界。即在找到了最前面的单调递减的一对之后,这一对的第二个元素以及之后的都要变成9才符合条件。
总的思想就是:

比如:1、332。32:2改9,3-1,变成29。总的变成329。再看前面的32,同样改成29,所以是229。
2、101。01符合,10不符合,改成099。
注意设置为9的位置变量是pos,初始化为s.size()。比如1234就任何位都不会设置为9.
class Solution {
public:
int monotoneIncreasingDigits(int n) {
string s=to_string(n);
cout<<s<<endl;
int pos=s.size();
for(int i=s.size()-1;i>=1;--i)
{
if(s[i-1]>s[i])
{
pos=i;//不断更新找到最前面的递减对
s[i-1]--;
}
}
for(int i=pos;i<s.size();++i)s[i]='9';
return stoi(s);
}
};
复杂度是n的位数不是n的值。
要求最小摄像头数量。
用递归怎么做?
摄像头可以覆盖上中下三层,所以不放在树的叶节点上面

所以1、选择后序遍历。从叶节点往上找最小数(贪心体现在此)
2、要统一设置几种状态。递归函数要 根据孩子的情况(递归返回的状态数字)推父节点的情况然后决定要不要设置摄像头,设置几种状态呢?所有节点就3种情况:0有摄像头、1没摄像头但被覆盖、2没被覆盖。
所以2个孩子的情况就有6种,不区分左右了,对称的。返回的是root应该的值:
1、左0右0。root得是1
2、左0右1。root得是1
3、左0右2。root得是0,所以摄像头数++。
4、左1右1。root得是0吗,不能确定,应该优先root的父节点设置,所以得是2。
5、左1右2。root得是0,所以摄像头数++。
6、左2右2。root得是0,所以摄像头数++。
综上根据root的赋值,可以得到3种情况:
a、root是2:左1右1。即root没有被覆盖。不++,因为指望父节点设置摄像头
b、root是0:左右至少有一个2。即左右有一个没被覆盖,root这时候必须得设置了
c、root是1:剩余的都是这种情况(注意顺序)。
注意:
1、递归出口怎么写?叶子节点不放,所以遇 递归出口空节点 的时候,要保证叶子结点不会摄像头数++,而且叶子结点没有被覆盖,所以空节点要返回的是1。对应情况a。
2、最后还需要检查root是否被覆盖,因为情况a的话,root没有被覆盖不会result++,而是抛出2,但是上面没有节点了,所以在root这只能设置一个摄像头。
综上:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
int result;
int traversal(TreeNode* root)
{
if(!root)return 1;
//0有摄像头、1没摄像头但被覆盖、2没被覆盖。
int left=traversal( root->left);
int right=traversal( root->right);
if(left==1&&right==1)
{
return 2;
}
else if (left == 2 || right == 2) {
result++;
return 0;
}
return 1;
}
public:
int minCameraCover(TreeNode* root) {
result = 0;
if (traversal(root) == 2) { // 最后检查 root 无覆盖
result++;
}
return result;
}
};
贪心总结:
1、在出现两个维度相互影响的情况时,两边一起考虑一定会顾此失彼,要先确定一个维度,再确定另一个一个维度。要确定是排序哪一个维度。
在讲解本题的过程中,还强调了编程语言的重要性,模拟插队的时候,使用C++中的list(链表)替代了vector(动态数组),效率会高很多。
(opens new window)详细讲解了,为什么用list(链表)更快!
2、
关于区间问题,大家应该印象深刻,有一周我们专门讲解的区间问题,各种覆盖各种去重。
- (opens new window)
- 贪心算法:跳跃游戏II
- (opens new window)
- 贪心算法:用最少数量的箭引爆气球
- (opens new window)
- 贪心算法:无重叠区间
- (opens new window)
- 贪心算法:划分字母区间
- (opens new window)
- 贪心算法:合并区间
上面的气球、无重叠区间、合并区间 的方法都比较像,用变量存储覆盖的边界。
其实是动态规划的题目,但贪心性能更优,很多同学也是第一次发现贪心能比动规更优的题目。
可能以为是一道模拟题,但就算模拟其实也不简单,需要把while用的很娴熟。但其实是可以使用贪心给时间复杂度降低一个数量级。
最后贪心系列压轴题目贪心算法:我要监控二叉树!
,不仅贪心的思路不好想,而且需要对二叉树的操作特别娴熟,这就是典型的交叉类难题了。主要体现在尽量选择父节点和状态的总结以及分类讨论.















 1027
1027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









