






之前的都是针对固定数据结构的题目,一看你就能知道要使用哪一个数据结构。但是从回溯开始,题目不会特别说明你要用哪种方法,回溯、穷举还是DP等,需要自己判断。所以有多种方法的最好都看一看,加深方法的理解,面试的时候可不会提示用什么方法。
回溯很有套路,会的觉得简单,不会的觉得难。
分类:

代码模板:
void backtracking(参数){
if(出口条件){
收集结果;
return;
}
for(子节点){
处理节点
递归
回溯,撤销处理结果
}
}只要有递归,就会有回溯,之前的二叉树很多递归,其实也跟上面的一样,只不过大部分没有处理节点和撤销的操作,要记录动态路径就得有处理和撤销操作。
因为回溯的本质是穷举,穷举所有可能,然后选出我们想要的答案,如果想让回溯法高效一些,可以加一些剪枝的操作,但也改不了回溯法就是穷举的本质。因为没得选,一些问题能暴力搜出来就不错了,撑死了再剪枝一下,还没有更高效的解法。
所有回溯法的问题都可以抽象为树形结构!回溯是对树形结构的前序遍历。

从图中看出for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。
每次回溯之前,想一下树形结构是什么样:
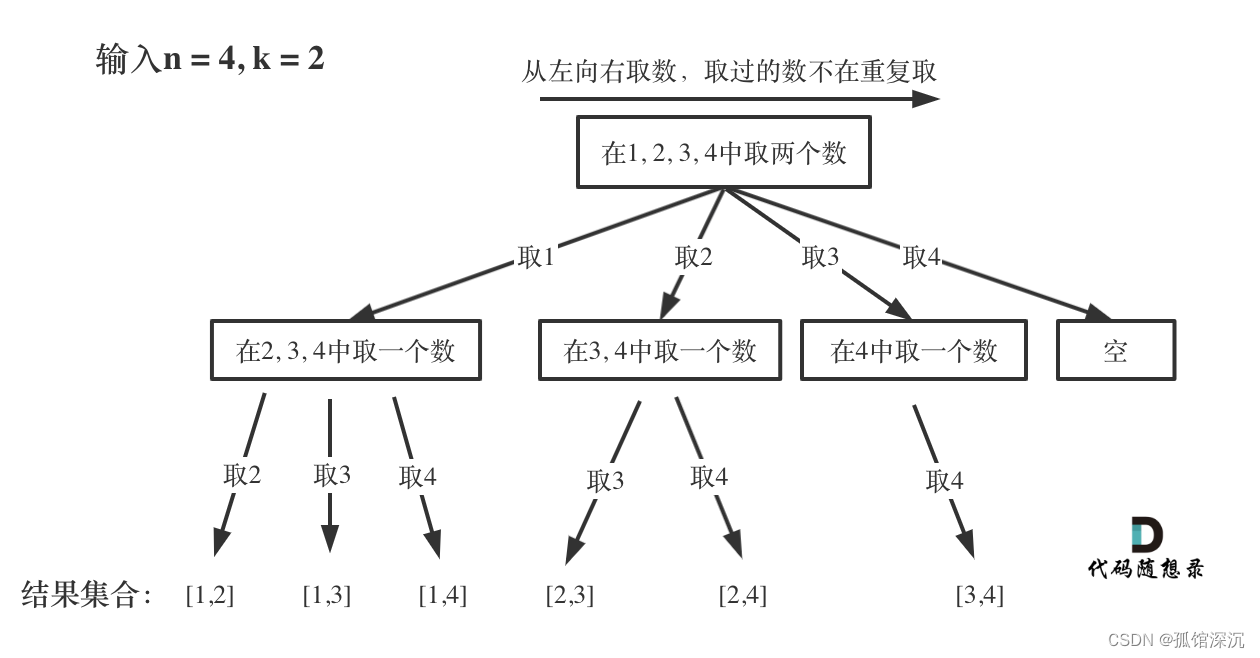
如果n=4,k=2的话。准确的说,这里4个循环,递归出口使得层次为2。
图片里面取4的时候是空,所以还可以剪枝。path长度(这条路径)加上还能放进去的数都不能到k则return。
class Solution {
public:
//回溯
vector<vector<int>> result;
vector<int> path;
void backtrack(int n,int k,int index)//在[index,n]中取一个数
{
if(path.size()+n-index+1<k)return;//剪枝
if(path.size()==k)
{
result.push_back(path);
return ;
}
for(int i=index;i<=n;++i)//节点数.[1, n]
{
path.push_back(i);
backtrack(n,k,i+1);
path.pop_back();
}
}
vector<vector<int>> combine(int n, int k) {
backtrack(n,k,1);
return result;
}
};时间复杂度:O(n*2^n)。
空间复杂度:O(n)。
和上面一样的组合回溯:
class Solution {
public:
vector<int> path;
vector<vector<int>> result;
int sum=0;
void backtrack(int k, int n,int index)
{
if(path.size()+n-index+1<k)return;
if(path.size()==k){
if(sum==n)result.push_back(path);
return;
}
for(int i=index;i<10;++i)
{
sum+=i;
path.push_back(i);
backtrack(k,n,i+1);
path.pop_back();
sum-=i;
}
}
vector<vector<int>> combinationSum3(int k, int n) {
backtrack(k,n,1);
return result;
}
};但是sum类变量,时间有点长。
把sum定为局部变量,快一些:
class Solution {
public:
vector<int> path;
vector<vector<int>> result;
void backtrack(int k, int n,int index)
{
if(path.size()+n-index+1<k)return;
if(path.size()==k){//到叶子
int sum=0;
for(auto i:path)sum+=i;
if(sum==n)result.push_back(path);
return;
}
for(int i=index;i<10;++i)
{
path.push_back(i);
backtrack(k,n,i+1);
path.pop_back();
}
}
vector<vector<int>> combinationSum3(int k, int n) {
backtrack(k,n,1);
return result;
}
};先想一下树形结构。
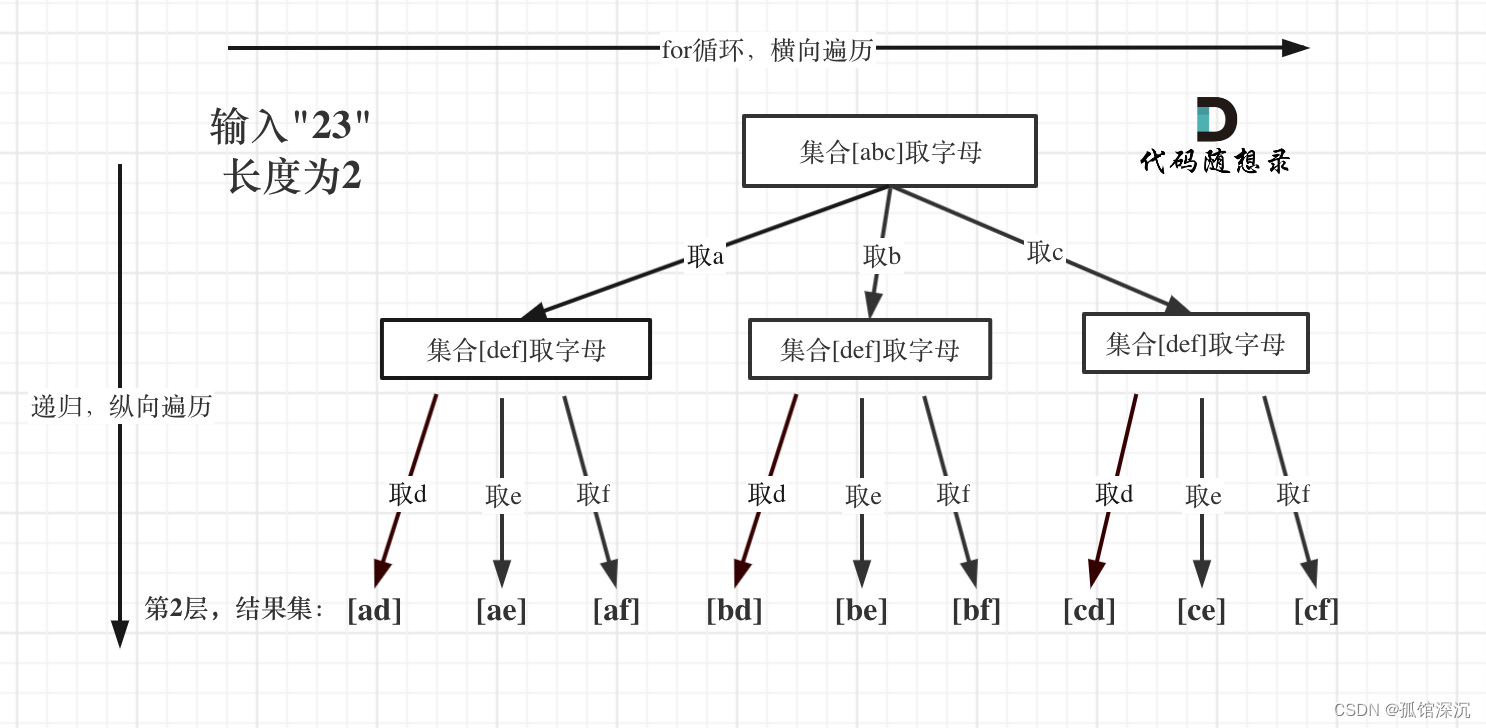
树形结构没问题的,但是回溯的循环,没能写对。
每个节点都会执行一次函数,观察每个节点,子节点都是从0到某个string的末尾,这个string就是digits[层次]对应的字符串。
所以for循环是从0到这个string.size()-1。先把string 求出来,需要知道当前节点的层次,肯定是上一次递归(也就是父子节点的层次)+1,所以这个得当做参数传递。
在循环内,path加入的是这个str[i]。
class Solution {
public:
vector<string> dhMap={
"",
"",
"abc",
"def",
"ghi",
"jkl",
"mno",
"pqrs",
"tuv",
"wxyz"
};
string path;
vector<string> result;
void backTrack(string digits,int dindex)
{
if(path.size()==digits.size())
{
result.push_back(path);
return;
}
string str=dhMap[digits[dindex]-'0'];
for(int i=0;i<str.size();++i)
{
path.push_back(str[i]);
backTrack(digits,dindex+1);//下一层走
path.pop_back();
}
}
vector<string> letterCombinations(string digits) {
if(digits.size()==0)return result;
backTrack(digits,0);
return result;
}
};还写了两层循环,是不必要的。因为每一个节点的子节点样子都是统一的。感觉没做到过回溯要用两层循环。所以一定专注树形结构,找规律,指标参数别搞混。
for循环的首尾也是一样,0到str.size()。
以后回溯,专注于树形结构。看节点的子节点找他的统一规律(然后得到for循环)。像上面的组合每个节点子节点开始位置是不一样,所以要有个参数传递这个位置。这里就不用。但是这里得记录层次数得到str,所以记录dindex。
总的,想复杂了。
注意:
![]()
所以传递的参数index是i而不是i+1。但是不再加条件,会无限递归下去。
所以加一个>target了就return。
class Solution {
public:
vector<vector<int>> result;
vector<int> path;
void backTrack(vector<int>& candidates, int target,int index)
{
if(0>target)return;
if(0==target)
{
result.push_back(path);
return ;
}
for(int i=index;i<candidates.size();++i)
{
path.push_back(candidates[i]);
backTrack(candidates,target-candidates[i],i);
path.pop_back();
}
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
backTrack(candidates,target,0);
return result;
}
};和上题的区别:有重复元素但是要求 解集不能包含重复的组合。
所以比前面的几个题目,又进阶了。
怎么去重呢,一刷还有一点记忆,在一个节点下面(就是一个for里面),如果已经选择了一个值为x的元素了,想的是记录本循环里面本元素之前的元素,放unordered_set里面,如果 本元素 在里面找得到,就continue。
怎么实现?
确实还是比较复杂,一刷使用used数组。而且必须得先排序了再操作。因为先排序,重复一样的元素才会连续在一起。
但是也可以不用used数组,且不设置 sum 类变量。更简洁:
class Solution {
public:
vector<vector<int>> result;
vector<int> path;
void backTrack(vector<int>& candidates, int target,int index)
{
if(target<0)return;//纵向剪枝
if(target==0)
{
result.push_back(path);
return;
}
for(int i=index;i<candidates.size();++i)
{
if(i>index && candidates[i]==candidates[i-1])continue;//横向剪枝
path.push_back(candidates[i]);
backTrack(candidates,target-candidates[i],i+1);
path.pop_back();
}
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(),candidates.end());
backTrack(candidates,target,0);
return result;
}
};记住这个技巧,不设sum变量而是变化target参数;排序之后顺序搜索,从for循环的第二个开始(i>index),发现和前一个相同就跳过——是横向剪枝。所以第一个和后面不重复的元素会统计路径,其他被剪枝。
这个图说的好:

顺便学一下调试java程序,点击行数打断点,然后debug:

所以以后设置合适的断点按debug就看到整个程序运行过程。
不看答案想不到,设两个参数a和b,其实不用。
每个循环体里面,只管一个子串,一个循环有多个子串,用i代表上届即可代表多个变化的子串,i这头变化,index那一头是固定的。所以循环里面,看s[i,index]这个子串是不是回文,不是就continue。和前面一样,只有符合条件的(回文的)才会进行回溯,否则被剪枝。
用图更形象:

所以还是得学会怎么统一地表示出这个树形结构来。
class Solution {
public:
vector<string> path;
vector<vector<string>> result;
bool isPalindrome(string s,int a,int b)
{
for(int i=a;i<=(a+b)/2;++i)
{
if(s[i]!=s[b+a-i])return false;
}
return true;
}
void backTrack(string s,int index)
{
if(index>=s.size())
{
result.push_back(path);
return;
}
for(int i=index;i<=s.size()-1;++i)
{
//重点还是在剪枝
if(!isPalindrome(s,index,i))continue;//[index,i]的子串
string str=s.substr(index,i-index+1);
path.push_back(str);
backTrack(s,i+1);//是i+1不是index+1
path.pop_back();
}
}
vector<vector<string>> partition(string s) {
backTrack(s,0);
return result;
}
};跟上一题差不多,但是多几个条件,注意考虑清楚:
class Solution {
public:
string path;
vector<string> result;
int dian=0;//dian必须也是回溯的一部分而不是收集的时候归零。
void backTrack(string s,int index)
{
if(index >= s.size() && dian==3 )
{
result.push_back(path);
return;
}
for(int i=index;i<s.size();++i)
{
//剪枝
string str=s.substr(index,i-index+1);
if( str.size() > 1 && str[0]=='0')continue;//前导0
if(str.size()>3 || dian >3)continue;//点数多了
int num=stoi(str);
if(num >= 256)continue;//超过255
if(i!=s.size()-1)
{
str+='.';
dian++;
}
path+=str;
backTrack(s,i+1);
if(i!=s.size()-1)
{
dian--;
}
path.erase(path.size()-str.size(),str.size());
}
}
vector<string> restoreIpAddresses(string s) {
backTrack(s,0);
return result;
}
};path代表路径,一定是跟随着回溯的(在递归前后操作与撤销操作),同时剪枝还需要用到加的点数dian,这个也要跟随回溯。
时间开销还比较大,可以再优化一下。
有的可以用break而不是continue,就是下面这个语句:
if(str.size()>3 || dian >3)break;//点数多了ok快多了。
这两道题可以多练练。
有的条件还可以省略:
class Solution {
public:
vector<string> result;
//path和dian 参与回溯
string path;
int dian=0;
void backTrack(string s,int index)
{
if(dian == 3 && index>=s.size())
{
result.push_back(path);
return;
}
for(int i=index;i<s.size();++i)//[index,i]的子串
{
//剪枝
string str=s.substr(index,i-index+1);
if(i-index>0 && s[index]=='0')continue;//前导0
if(dian> 3 || stoi(str)>255) break;
if(i<s.size()-1)
{
str+='.';
dian ++;
}
path+=str;
backTrack(s,i+1);
if(i<s.size()-1)dian--;
path.erase(path.size()-str.size(),str.size());
}
}
vector<string> restoreIpAddresses(string s) {
backTrack(s,0);
return result;
}
};下面开始子集问题:
跟之前的问题不同的是,树形结构的每个节点都要手机path的结果:
class Solution {
public:
vector<int> path;
vector<vector<int>> result;
void backTrack(vector<int>& nums,int index)
{
if(index>=nums.size())
{
//result.push_back(path);
return;
}
for(int i=index;i<nums.size();++i){
path.push_back(nums[i]);
result.push_back(path);//每个节点都收集而不是叶子结点收集
backTrack(nums,i+1);
path.pop_back();
}
}
vector<vector<int>> subsets(vector<int>& nums) {
backTrack(nums,0);
result.push_back(path);
return result;
}
};即结合了上题和组合去重的那一题:
class Solution {
public:
vector<vector<int>> result;
vector<int> path;
void backTrack(vector<int>& nums,int index)
{
if(index>nums.size())
{
return;
}
for(int i=index;i<nums.size();++i)
{
if(i>index && nums[i]==nums[i-1] )continue;//剪枝
path.push_back(nums[i]);
result.push_back(path);
backTrack(nums,i+1);
path.pop_back();
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(),nums.end());
result.push_back(path);
backTrack(nums,0);
return result;
}
};想用以前的剪枝套路,但是压根不能改变原有的序列顺序。
不想用Used数组,我用find数组判断回溯的本次for循环子序列(即[index,i-1]范围,i之前)有没有nums[i],但是会多剪去一些枝。
class Solution {
public:
vector<int> path;
vector<vector<int>> result;
void backtrack(vector<int>& nums,int index)
{
if(index >= nums.size())
{
return ;
}
for(int i=index;i<nums.size();++i)
{
//剪枝
if(index>0 && nums[i]<nums[index-1])continue;//比父节点大
if(i>index && std::find(nums.begin()+index, nums.begin()+i, nums[i])!=nums.end())continue ;
//if(nums.find(index,i-1))continue;
path.push_back(nums[i]);
if(path.size()>1)result.push_back(path);
backtrack(nums,i+1);
path.pop_back();
}
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
//不能排序
backtrack(nums,0);
return result;
}
};
debug了一下,没想出来。
发现是,find()函数用错,find(nums.begin()+a, nums.begin()+b, nums[i]),没找到的话应该是返回nums.begin()+b这个位置的迭代器,而不是.end()。所以思路还是没有问题。
class Solution {
public:
vector<int> path;
vector<vector<int>> result;
void backtrack(vector<int>& nums,int index)
{
if(index >= nums.size())
{
return ;
}
for(int i=index;i<nums.size();++i)
{
//剪枝
if(index>0 && nums[i]<nums[index-1])continue;//比父节点大
bool f=(find(nums.begin()+index, nums.begin()+i, nums[i]) != (nums.begin()+i));
if(i>index && f)continue ;//[index,i)有没有
path.push_back(nums[i]);
if(path.size()>1)result.push_back(path);
backtrack(nums,i+1);
path.pop_back();
}
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
//不能排序
backtrack(nums,0);
return result;
}
};
所以对有的函数不太熟悉不确定的话就去查用法,用法用对了还错就是思路问题。
回溯,每个for循环又可以看成从现在开始的子树可分配的元素是 [ index.nums.size() ) 。一种感觉。
也是有剪枝的,因为排列不像之前的组合,[1,2,3]和[2,1,3]是2个答案,所以循环得从0到尾。如果path里面已经放入某个元素,就continue。
class Solution {
public:
vector<vector<int>> result;
vector<int> path;
void backTrack(vector<int>& nums){
if(path.size()==nums.size())
{
result.push_back(path);
return;
}
for(int i=0;i<nums.size();++i)
{
if(find(path.begin(),path.end(),nums[i])!=path.end())continue;//剪枝
path.push_back(nums[i]);
backTrack(nums);
path.pop_back();
}
}
vector<vector<int>> permute(vector<int>& nums) {
backTrack(nums);
return result;
}
};这得用辅助数组了,像上一题那样path里面剪枝(纵向去重)的话不行因为nums有重复元素。
再者横向剪枝的话,如果认为这一层在本节点前面有重复的点就跳过,是×的。
比如例题[1,1,2]。正确的递归树形结构应该是下面这样:

但是单纯检查nums数组中,本节点前面是否出现重复值是不行,比如1下面第二个1 ,前面有一个1 ,认为回溯过了所以这个子树都会跳过,但其实前面那个1是下标为0的1,也是跳过了没有回溯的,所以会多剪枝。
那么横向剪枝在上面错误的基础上,再+个条件:前面那个重复节点已经回溯过(即不是当前节点的祖先) 即可。所以已经回溯过后used值一定是false。
不用find函数的话就先sort排序,就可used[i]=used[i-1]检查重复。
class Solution {
public:
vector<int> path;
vector<vector<int>> result;
vector<bool> used;
void backTrack(vector<int>& nums,int index)
{
if(path.size()==nums.size())
{
result.push_back(path);
return;
}
for(int i=0;i<nums.size();++i)
{
if(used[i]==true)continue;//被用过了
if(i>0 && nums[i] ==nums[i-1] && used[i-1]==false)continue;//同一层已经回溯了相同的。
path.push_back(nums[i]);
used[i]=true;
backTrack(nums,i);
used[i]=false;
path.pop_back();
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
used.resize(nums.size(),false);
sort(nums.begin(),nums.end());
backTrack(nums,0);
return result;
}
};想用find()函数,然后不用sort(),还有问题,比如[3,3,0,3]就过不了。
class Solution {
public:
vector<int> path;
vector<vector<int>> result;
vector<bool> used;
void backTrack(vector<int>& nums,int index)
{
if(path.size()==nums.size())
{
result.push_back(path);
return;
}
for(int i=0;i<nums.size();++i)
{
if(used[i]==true)continue;//被用过了
auto it=find(nums.begin(),nums.begin()+i,nums[i]);
if(i>0 && it!=nums.begin()+i && used[it-nums.begin()]==false)continue;//同一层已经回溯了相同的。nums[i] ==nums[i-1]
path.push_back(nums[i]);
used[i]=true;
backTrack(nums,i);
used[i]=false;
path.pop_back();
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
used.resize(nums.size(),false);
//sort(nums.begin(),nums.end());
backTrack(nums,0);
return result;
}
};如果在解题的过程中没有对集合元素处理好,就会死循环。

回忆回溯模板,下面回溯前是 处理节点,回溯后是 撤销处理结果。不要记个死板的Push_back()、pop_back()。

又是bool backTrack(),参数又不是我想的vector<vector<string>>& tickets,有难度。
其实参数好说,用几个全局变量代替函数的参数就行了,比如代码随想录的唯一一个参数ticketNum,也可以用全局变量,这样就没有一个参数(tickets用全局变量unordered_map类型的hash表代替)。
从答案分析是怎么满足题目所有要求的:
1、为了方便使用树形结构,用unordered_map<string,map<string,int>>存储tickets的所有信息,因为要求字典序,某个节点的子节点必须有序排列,所以里面用map;根节点都是从"JFK"开始,不用有序,so外面用unordered_map。
2、返回类型定为bool,因为这道题的结果就是单个的路径,那么这里resul=path。所以发现了这条路径直接就返回true,第一次发现的就是字典序排在前面的,直接返回true,后面同样合理但是字典序排在后面的路径就不会再遍历到。
就像下面的路径②是合理的,但是根本不会遍历到,①路径递归完,会一直往上返回true,最终JFK这层返回true,backTrack()结束,result存储了①路径的所有机场点。

树形结构好像也不难,但是对容器的操作还是要比较熟练。
3、终止条件是什么?当到达一个节点,这条路径上的机场数==票数+1就可以返回true了。因为这条路径都是合法的,一条分支用一张票。
另外可以从结构看出来,for循环就是遍历unordered_map<string,map<string,int>>里面的<string,map<string,int>>对,就是result尾部元素对应的多个目的机场。怎么剪枝呢?当去某个目的机场没有票了就跳过。
初始化result得push_back"JFK",才能得以从"JFK"开始。
class Solution {
public:
unordered_map<string,map<string,int>> hash;
vector<string> result;
int ticketNum;
bool backTrack()
{
//终止条件:遇机场个数等于票数+1
if(result.size()==ticketNum+1)
{
return true;
}
string curjichang=result.back();
for(pair<const string,int> &p:hash[curjichang]){//遍历curjichang的目的机场;必须要是引用
if(p.second<=0)continue;//剪枝:不可以飞
//还有票,可以飞
p.second--;
result.push_back(p.first);
if(backTrack())return true;
result.pop_back();
p.second++;
}
return false;//没有找到
}
vector<string> findItinerary(vector<vector<string>>& tickets) {
//初始化
hash.clear();
for( vector<string> vec:tickets)
{
hash[vec[0]][vec[1]]++;
}
result.push_back("JFK");
ticketNum=tickets.size();//票数
backTrack();
return result;
}
};代码随想录原话:
一定要加上引用即 & target,因为主要原因是后面有对 target.second 做减减操作,如果没有引用,单纯复制,这个结果就没记录下来,那最后的结果就不对了。当然也比较节省空间。
加上引用之后,就必须在 string 前面加上 const,因为map中的key 是不可修改了,这就是语法规定了。
for(auto)循环:只读:const +&;需要改变原本值:&;
上面用pair<const string,int> &p:string值,用const+&。int值要改写,只用&。所以在pair整体后面加&。
结构:每个棋子肯定单独放每一行,所以for循环(横向)就是考虑每个棋子放的列数;纵向就是考虑放旗子的行数,也就是放的第几个棋子。从上到下、从左到右遍历所有情况。

出口:什么时候收集结果?当放完了第n个棋子的时候,也就是行坐标等于n的时候就可以收集结果了,result.push_back()。回溯函数里面的chessBoard(相当于之前的path,只不过path是一维,chessBoard二维)只会放入合法的棋子,所以不合法的路径在放入第一个不合法的位置的时候就会被剪枝。
所以剪枝就需要考虑3种情况:左上角对角线、右上角对角线、列。这里回溯结构就是从上到下一行一行放一个旗子的,所以不用考虑行的情况。
class Solution {
public:
vector<vector<string>> result;
vector<string> chessBoard;
bool isValid(int x,int y,int n)//棋子在(x,y)坐标处
{
for(int i=0;i<x;++i){//当前列是否有棋子
if(chessBoard[i][y]=='Q')return false;
}
int a=x-1,b=y-1;
while(a>=0 && b>=0)//当前对角线(135度)是否有棋子
{
if(chessBoard[a][b]=='Q')return false;
a--;
b--;
}
a=x-1;
b=y+1;
while(a>=0 && b<n)//当前对角线(45度)是否有棋子
{
if(chessBoard[a][b]=='Q')return false;
a--;
b++;
}
return true;
}
void backTrack(int n,int row)//第row个旗子放第row行
{
if(row==n){
result.push_back(chessBoard);
return;
}
for(int i=0;i<n;++i)//放第1-n列,n种情况
{
//关键:判断合法性然后不合法的剪枝:列、对角线
if(!isValid(row,i,n))continue;
chessBoard[row][i]='Q';
backTrack(n,row+1);
chessBoard[row][i]='.';
}
}
vector<vector<string>> solveNQueens(int n) {
//初始化
chessBoard.resize(n, std::string(n, '.'));
backTrack(n,0);
return result;
}
};总的就是找到row这一行的这个棋子合法的位置(x,y),记录在chessBoard里面,然后去看下一行的棋子合法的位置……直到叶子结点或者被剪枝,又换一个分支再深度搜索,可以把所有结果搜索出来。
上一道题返回是bool因为只要返回字典序第一的结果,所以用返回值表示是否已经找到第一条合法路径,但是这里是返回所有结果,所以也是没有返回值的。
这几道困难题的path或者result和之前的不一样,因为处理的是二/多维数组。但是模板还是一样的,所以关键还是理清回溯的结构。
N皇后是一次放一个,一行就一个,所以一行就递归一次。但是数独一行里面所有空的都要放。
所以之前做的都是一维递归,这里是2维递归。每个位置都要递归,所以两层for循环才能涉及到所有位置。
for(int i=0;i<board.size();++i){//行
for(int j=0;j<board[0].size();++j){//列
}
}即:
一个for循环遍历棋盘的行,一个for循环遍历棋盘的列,一行一列确定下来之后,递归遍历这个位置放9个数字的可能性!
所以回溯的for循环,就是从'1'到'9'。剪枝就是找这个分支代表的字符放在(x,y)这个位置合不合理(跟上面一样用isValid()函数)。不过上面N皇后的坐标(x,y),x是递归的参数,因为确定一层了就讨论下一层(row+1),y是for循环遍历而来的。这里的(x,y)就是普通双层循环,双层循环里面才是之前模板里面的回溯for循环(for(……k……))。相当于确定一个位置了,之后每次都从坐标(0,0)开始检查整个表:如果是数字就跳过,否则进入回溯for循环确定这个坐标的字符。

在这里,回溯函数和上面机场的一样,返回类型用bool。因为只有一个答案,全部填满了就直接返回了。
class Solution {
public:
bool isValid(int x,int y,char c,vector<vector<char>>& board){
for(int i=0;i<9;++i){
if(board[i][y]==c)return false;
}
for(int i=0;i<9;++i){
if(board[x][i]==c)return false;
}
for(int i=(x/3)*3;i<(x/3+1)*3;++i){
for(int j=(y/3)*3;j<(y/3+1)*3;++j){
if(board[i][j]==c)return false;
}
}
return true;
}
bool backTrack(vector<vector<char>>& board){
for(int i=0;i<board.size();++i){//行
for(int j=0;j<board[0].size();++j){//列
if(board[i][j]!='.')continue;//是数字
for(char k='1';k<='9';++k){//挨个试,横向for循环
if(!isValid(i,j,k,board))continue;//(i,j)放k不合适,剪枝
board[i][j]=k;
if(backTrack(board))return true;
board[i][j]='.';
}
return false;
}
}
return true;
}
void solveSudoku(vector<vector<char>>& board) {
backTrack(board);
}
};上面代码随想录的代码,过程是:每次调用backTrack(),从(0,0)开始检查,(i,j)如果已经有数字,跳过看下一个坐标(i,j+1);如果不是数字,进入回溯for循环,挨个检查'1'到'9'是否合法,不合法则剪枝,合法则记录在board里面(肯定有一个分支合法,(i,j)被数字覆盖),然后接着调用backTrack(),从(0,0)开始检查……当到最后的位置(8,8)坐标,board(8,8)记录下来,再次调用backTrack(),在两层循环里面,所有的board[i][j]都是数字,都会跳过,然后在两层循环外面返回true,这就是递归出口,递归结束。然后往上走,唯一一条正确的分支,backTrack()会一直往上返回true,否则返回false(下面有分支不合格,没有事先返回true)。
class Solution {
public:
bool isValid(int x,int y,char c,vector<vector<char>>& board){
for(int i=0;i<9;++i){
if(board[i][y]==c)return false;
}
for(int i=0;i<9;++i){
if(board[x][i]==c)return false;
}
for(int i=(x/3)*3;i<(x/3+1)*3;++i){
for(int j=(y/3)*3;j<(y/3+1)*3;++j){
if(board[i][j]==c)return false;
}
}
return true;
}
bool backTrack(vector<vector<char>>& board){
for(int i=0;i<board.size();++i){//行
for(int j=0;j<board[0].size();++j){//列
if(board[i][j]!='.')continue;//是数字
for(char k='1';k<='9';++k){//挨个试,横向for循环
if(!isValid(i,j,k,board))continue;//(i,j)放k不合适,剪枝
board[i][j]=k;
if(backTrack(board))return true;
board[i][j]='.';
}
return false;
}
}
return true;
}
void solveSudoku(vector<vector<char>>& board) {
backTrack(board);
}
};这里3个return放的位置很有讲究,第一个return true:为了找到答案(正确的分支)就返回;第二个return false,表明下面有分支不合法(没有返回true,所以撤销了设置为k的操作);第三个return,是照顾最后一种情况,所有空都填好了,所有坐标都会continue,就不会在这个出口返回。
所以没有模板那种显式的递归出口。这个树形结构长度是整个表里面空着的个数。
三刷再看别的题解吧,还有什么枚举优化、位运算优化。
回溯总结篇
统一的模板+剪枝。
重要的就是往模板里面填什么,for循环是从多少到多少,递归传什么参数,剪枝条件是什么……
回溯算法能解决如下问题:
- 组合问题:N个数里面按一定规则找出k个数的集合。
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 棋盘问题:N皇后,解数独等等















 787
787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









