







Tacotron2声谱预测网络
前置知识
1.注意力机制
2.RNN
3.CNN
- LSTM
5.梅尔波形(mel spectrogram)——一种中间声学特征表示
模型概述
该语音合成系统由两个组件组成,如下图所示
- 一个循环seq2seq声谱特征预测网络,它从输入字符序列预测mel谱图帧的序列;
- 一个改进的WaveNet,它根据预测的mel谱图帧生成时域波形样本。
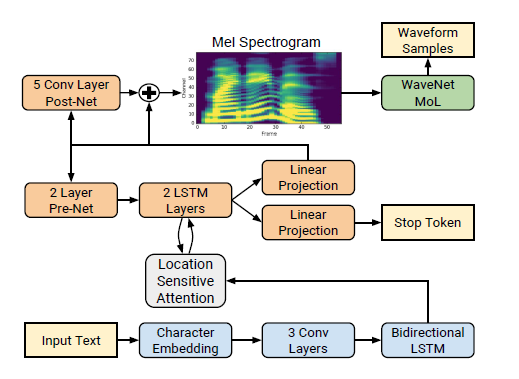
我们选择了一个低电平的声学表示:梅尔-频谱图,以连接这两个成分。使用一种很容易从时域波形计算出来的表示形式,可以让我们分别训练这两个分量。这种表示也比波形样本更平滑,更容易训练使用平方误差损失,因为它是不变的相位在每一帧。mel谱图与线性谱图有关,即短时傅里叶变换(STFT)幅度。
该方法是根据人类听觉系统的实测响应,对短时傅立叶变换的频率轴进行非线性变换,以较少的维数总结频率内容。
使用这种听觉频率标度可以强调对语音清晰度至关重要的低频细节,同时减少了对高频细节的强调,高频细节主要由摩擦和其他噪声爆发控制,通常不需要以高保真度建模。由于这些特性,从mel尺度衍生出来的特征已经被用作语音识别的基础表示几十年了
声谱预测网络
梅尔谱图生成
我们使用跨越125 Hz至7.6 kHz的80通道mel滤波器组将STFT幅度转换为梅尔尺度,然后进行对数动态范围压缩。在日志压缩之前,为了限制对数域的动态范围,滤波器组的输出幅度被裁剪到最小值0.01。
结构概述
该网络由编码器(Encoder)和解码器(Decoder)组成。编码器将字符序列转换为隐藏的特征表示,解码器使用该特征表示来预测谱图。输入字符使用学习过的512维字符嵌入(a learned 512-dimensional character embedding)表示,该字符嵌入经过3个卷积层的堆栈,每个卷积层包含512个形状为 5 x 1 的滤波器(filter),即每个滤波器跨越5个字符,然后是批量归一化和ReLU激活。
编码器(Encoder)
编码器输出由注意力网络消耗,该网络将完整编码序列总结为每个解码器输出步骤的固定长度上下文向量。我们使用位置敏感注意(location-sensitive attention),它扩展了可加性注意机制将先前解码器时间步骤中的累积注意权值作为额外的特征。这鼓励模型在输入过程中始终向前移动,减少解码程序重复或忽略某些子序列的潜在失败模式。在投射输入后计算注意力概率
在Tacotron2中,编码器将输入序列 X=[x1,x2,…,xTx] 映射成序列H=[h1,h2,…,hTx] ,其中序列H被称作“编码器隐状态”(encoder hidden states)。注意:编码器的输入输出序列都拥有相同的长度,hi之于相邻分量hj拥有的信息等价于xi之于xj所拥有的信息。
在Tacotron2中,每一个输入分量xi就是一个字符。Tacotron2的编码器是一个3层卷积层后跟一个双向LSTM层形成的模块,在Tacotron2中卷积层给予了神经网络类似于N−gramN−gram感知上下文的能力。这里使用卷积层获取上下文主要是由于实践中RNN很难捕获长时依赖,并且卷积层的使用使得模型对不发音字符更为鲁棒(如’know’中的’k’)。
经词嵌入(word embedding)的字符序列先送入三层卷积层以提取上下文信息,然后送入一个双向的LSTM中生成编码器隐状态,即:
其中,F1、F2、F3F1、F2、F3为3个卷积核,ReLUReLU为每一个卷积层上的非线性激活E¯表示对字符序列X做embedding,EncoderRecurrency表示双向LSTM。
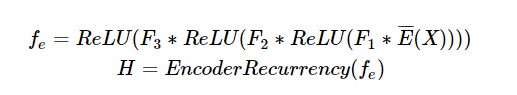
Tacotron2注意力机制-Location Sensitive Attention
其中,si为当前解码器隐状态而非上一步解码器隐状态,偏置值b被初始化为0。位置特征fi使用累加注意力权重cαi卷积而来

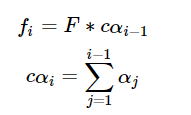
解码器(Decoder)
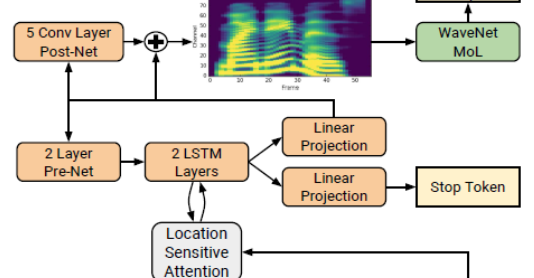
该解码器是一种自回归递归神经网络,它从编码后的输入序列一帧一帧地预测mel谱图。
其处理步骤如下:
- 前一个时间步的预测首先通过一个包含2个完全连接的256个隐藏ReLU单元的pre-net。
- 将pre-net输出和注意上下文向量串联起来,并通过一个包含1024个单元的2个单向LSTM层的堆栈。
- 将LSTM输出与注意上下文向量串联起来,通过线性变换进行投影,对目标谱图帧进行预测。
- 最后,将预测的mel谱图通过5层卷积post-net(5-layer convolutional post-net)进行预测,并将残差添加到预测中以改善预测的梅尔谱图质量。post-net由512个滤波器组成,形状为5 x 1,批量归一化,然后在最后一层上进行tanh激活。
声码器(Vocoder)
该论文使用的声码器是一个改进的WaveNet,不是本次论文重点提出的模型,也不是我们本次项目使用到的声码器模型。故略。之后再对melgan等声码器进行分析。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









