






 本文详细介绍了如何在PyCharm中运行含有训练和评估功能的main函数,涉及mask_model、data_set和classifier_model的选择,以及如何根据项目需求配置参数如VGGLikeMaskModel、DCASE2013RemixedDataSet等。
本文详细介绍了如何在PyCharm中运行含有训练和评估功能的main函数,涉及mask_model、data_set和classifier_model的选择,以及如何根据项目需求配置参数如VGGLikeMaskModel、DCASE2013RemixedDataSet等。
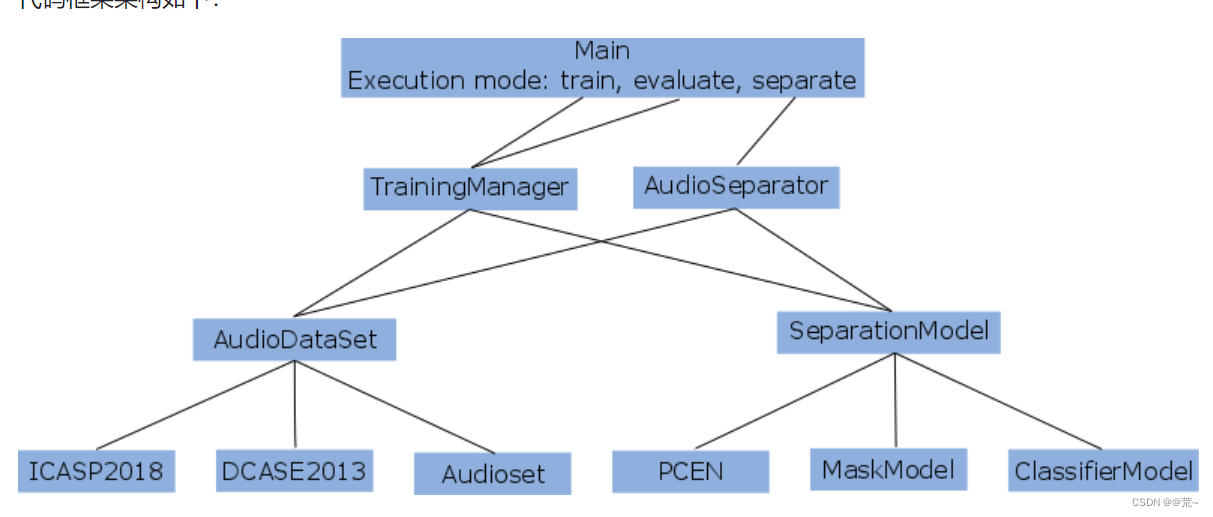
1、论文代码框架如下
2、运行main函数时,给出调试过程释意:
必须使用参数选择执行模式。选项是 和 。–mode train evaluate separate
对于训练模型,需要 3 个参数:要使用的数据集类型、掩码模型的类型和 分类器模型的类型。可用类型分别在函数 、 和 文件中报告。如果执行模式为 ,则必须传递这些参数。find_data_set_classfind_mask_model_classfind_classifier_model_classdata_set.pymask_model.pyclassifier_model.pytrain
3、在pycharm上,运行main时需要配置的地方
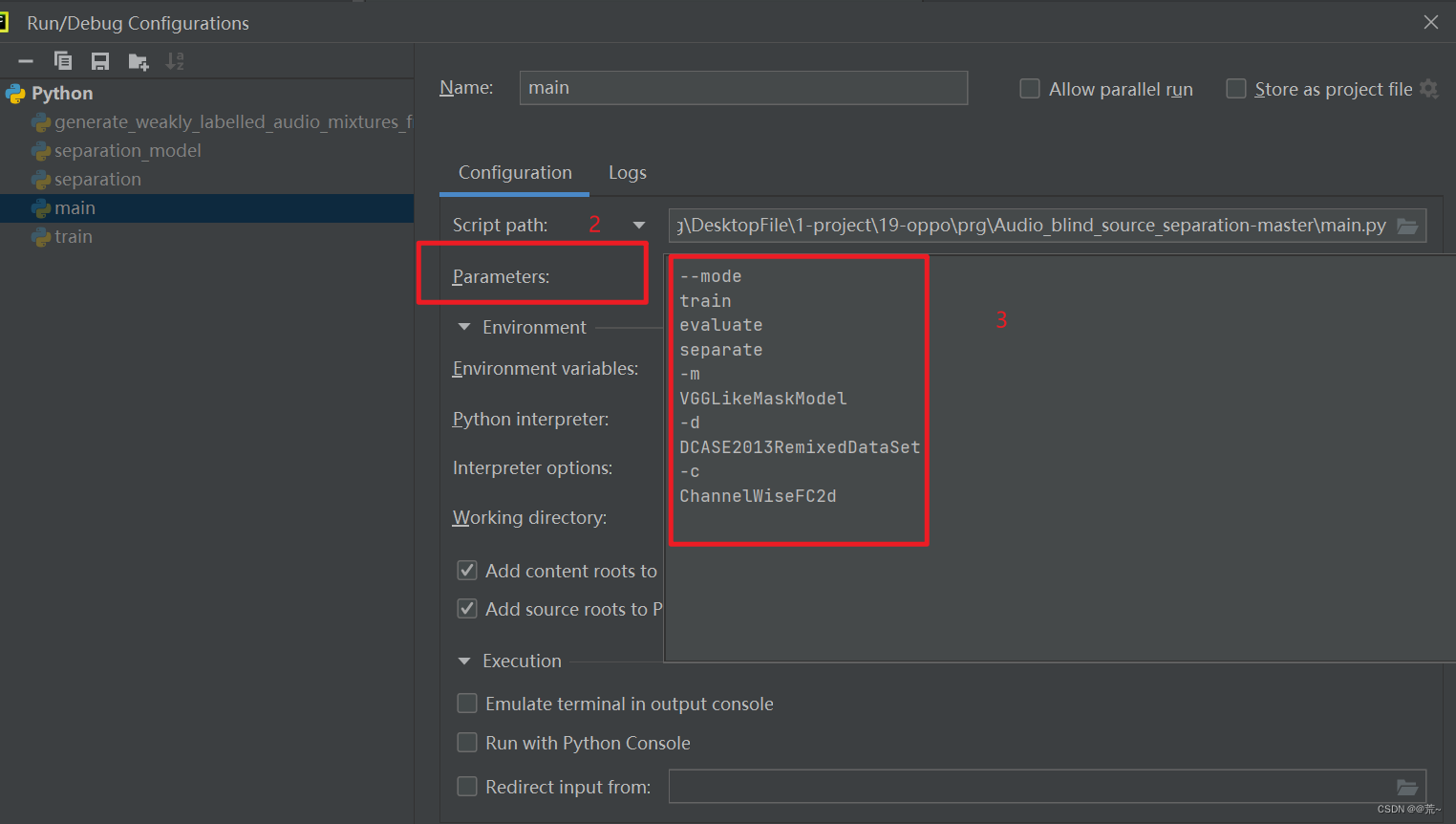
参数为:–mode train evaluate separate
-m
VGGLikeMaskModel
-d
DCASE2013RemixedDataSet
-c
ChannelWiseFC2d
其中,-m -d -c 后面的参数可以根据实际项目进行调整
m(mask_model)包括VGGLikeMaskModel
d(data_set)包括DCASE2013RemixedDataSet、ICASSP2018JointSeparationClassificationDataSet、AudiosetSegments和 AudiosetSegmentsOnDisk
c(classifier_model)包括 ChannelWiseFC2d、ChannelWiseRNNClassifier和DepthWiseCNNClassifier
4、数据集
为了生成DCASE2013 Sound Event Detection data set的数据集,应


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









