







一、调试处理
给超参数取值:网格中取样点,随机取值,由粗糙到精细的策略。

为超参数选择合适的范围:随机取值不是在有效范围内随即均匀取值,选择合适的步进值很重要。
比如搜索学习率α,在0.0001到1之间,如果随机均匀取值,则在0.1到1之间应用了90%的资源,在0.0001到0.1之间只有10%的搜索资源。
因此,不使用线性轴,而使用对数轴会更加合理。



β越接近于1越敏感,需要密集取值。
超参数调试实践:
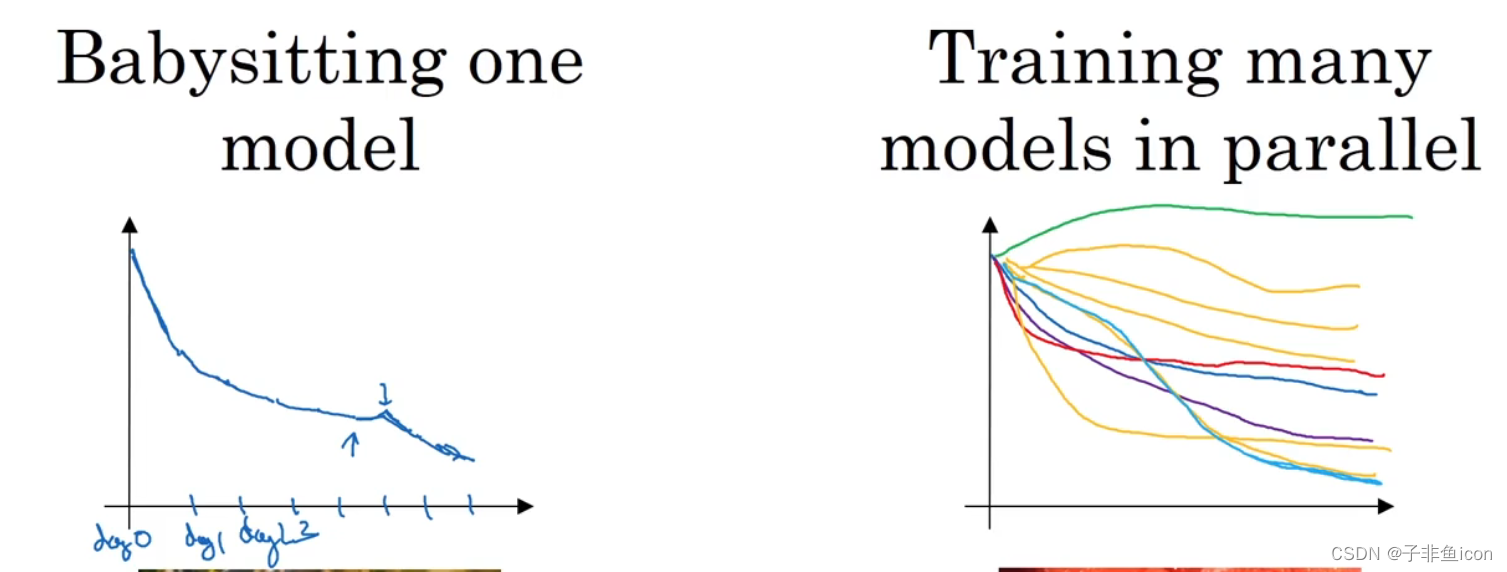
照看一个模型,慢慢修改 vs 同时实验多种模型
二、归一化网络的激活函数
归一化激活函数前的z,又利用 γ \gamma γ和 β \beta β调整为其他平均值和方差。
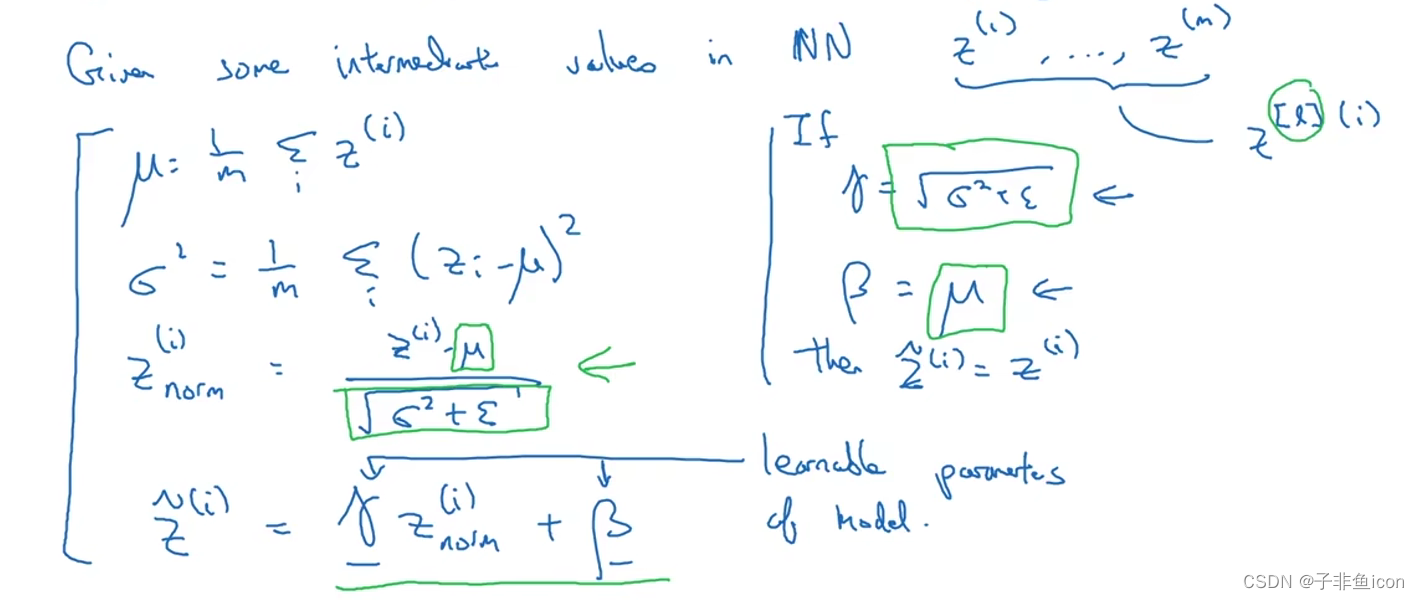
隐藏单元值不必全是平均值0和方差1

三、Batch Norm
在mini-batch上归一化z值,并更新β和γ的参数。

Batch Norm有效的原因:
1.归一化输入特征,加速学习。不仅对输入值,还有隐藏单元的值。
2.减弱了前层参数的作用与后层参数的作用之间的联系,使得网络每一层可以自己学习,稍微独立于其他层,降低依赖。
3.有轻微的正则化的效果。因为在mini-batch上计算的方差和均值与整个数据集上的相比,有一些小的噪声,但很小,所以是轻微的正则化。类似于dropout,因为给隐藏单元增加了噪音,使得后部单元不过分依赖于任何一个隐藏单元。
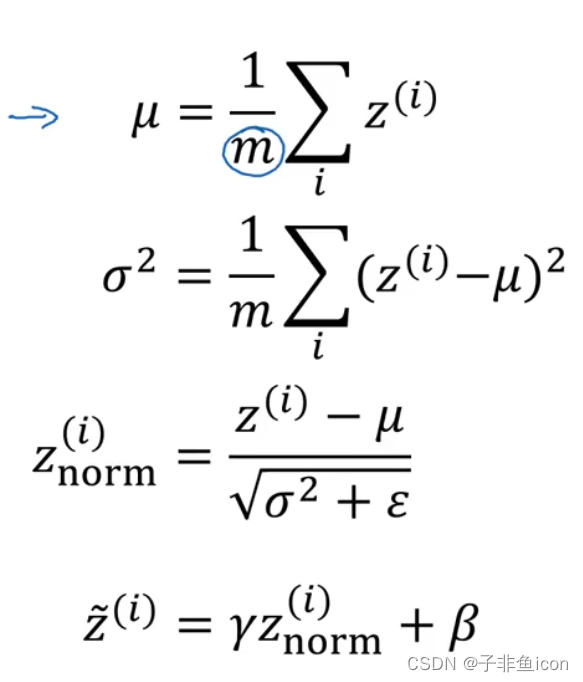
测试时的Batch Norm
在测试时,需要用其他的方式来得到
μ
\mu
μ和
σ
2
\sigma^{2}
σ2,用指数加权平均来估算。

四、softmax
此前学过,参考链接。
五、编程作业——手势识别
PS:一直就没有学过tensorflow,也不想花时间再安装库,配置各种环境,也不想跟pytorch混淆了,所以不同于参考链接,这里直接用pytorch实现。
代码:
import h5py
import time
import torch
import numpy as np
import torch.nn as nn
import matplotlib.pyplot as plt
# 加载数据集
def load_dataset():
train_dataset = h5py.File('datasets/train_signs.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_signs.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((train_set_y_orig.shape[0], 1))
test_set_y_orig = test_set_y_orig.reshape((test_set_y_orig.shape[0], 1))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
print(X_train_orig.shape) # (1080, 64, 64, 3),训练集1080张,图像大小是64*64
print(Y_train_orig.shape) # (1080, 1)
print(X_test_orig.shape) # (120, 64, 64, 3),测试集120张
print(Y_test_orig.shape) # (120, 1)
print(classes.shape) # (6,) 一共6种类别,0,1,2,3,4,5
# 查看其中的一张
index = 11
plt.imshow(X_train_orig[index])
plt.show()
print("Y = " + str(np.squeeze(Y_train_orig[index])))
# 处理并归一化数据
X_train_flatten = X_train_orig.reshape(X_train_orig.shape[0],-1) #每一行就是一个样本
X_test_flatten = X_test_orig.reshape(X_test_orig.shape[0],-1)
X_train = X_train_flatten / 255
X_test = X_test_flatten / 255
Y_train = Y_train_orig
Y_test = Y_test_orig
'''
# 转换为独热矩阵
def convert_to_one_hot(Y, C):
Y = np.eye(C)[Y.reshape(-1)] # 大小为6*6的单位矩阵
return Y
Y_train = convert_to_one_hot(Y_train_orig, 6)
Y_test = convert_to_one_hot(Y_test_orig, 6)
'''
# 转成Tensor方便后面的训练
X_train = torch.tensor(X_train, dtype=torch.float)
X_test = torch.tensor(X_test, dtype=torch.float)
Y_train = torch.tensor(Y_train, dtype=torch.float)
Y_test = torch.tensor(Y_test, dtype=torch.float)
print(X_train.shape)
print(X_test.shape)
print(Y_train.shape)
print(Y_test.shape)
# 建立模型
num_inputs, num_outputs, num_hiddens_1, num_hiddens_2 = X_train.shape[1], 6, 25, 12
net = nn.Sequential(
nn.Linear(num_inputs, num_hiddens_1), nn.ReLU(),
#nn.Dropout(p=0.2),
nn.Linear(num_hiddens_1, num_hiddens_2), nn.ReLU(),
#nn.Dropout(p=0.5),
nn.Linear(num_hiddens_2, num_outputs), nn.Softmax(dim=1))
# 随机初始化模型的权重参数
for params in net.parameters():
nn.init.normal_(params, mean=0, std=0.01)
# 定义损失函数
loss = nn.CrossEntropyLoss()
# 训练模型
def model(X_train, Y_train, lr=0.0001, batch_size=32, num_epochs=1500, print_loss=True, is_plot=True):
# 定义优化器
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
# 将训练数据的特征和标签组合
dataset = torch.utils.data.TensorDataset(X_train, Y_train)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
train_l_list, train_acc_list = [], []
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
y_hat = net(X)
y = y.squeeze(
1).long() # .squeeze()用来将[batch_size,1]降维至[batch_size],.long用来将floatTensor转化为LongTensor,loss函数对类型有要求
l = loss(y_hat, y).sum()
# print(y.shape,y_hat.shape)
# print(l)
# 梯度清零
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
# print(y_hat.argmax(dim=1).shape,y.shape)
n += y.shape[0]
train_l_list.append(train_l_sum / n)
train_acc_list.append(train_acc_sum / n)
if print_loss and ((epoch + 1) % 100 == 0):
print('epoch %d, loss %.4f, train acc %.3f' % (epoch + 1, train_l_sum / n, train_acc_sum / n))
# 画图展示
if is_plot:
epochs_list = range(1, num_epochs + 1)
plt.subplot(211)
plt.plot(epochs_list, train_acc_list, label='train acc', color='r')
plt.title('Train acc')
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.tight_layout()
plt.legend()
plt.subplot(212)
plt.plot(epochs_list, train_l_list, label='train loss', color='b')
plt.title('Train loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.tight_layout()
plt.legend()
plt.show()
return train_l_list, train_acc_list
#开始时间
start_time = time.clock()
#开始训练
train_l_list, train_acc_list = model(X_train, Y_train, lr=0.0001, batch_size=32, num_epochs=1500, print_loss=True, is_plot=True)
#结束时间
end_time = time.clock()
#计算时差
print("CPU的执行时间 = " + str(end_time - start_time) + " 秒" )
#计算分类准确率
def evaluate_accuracy(X_test, Y_test, net):
acc = (net(X_test).argmax(dim=1) == Y_test.squeeze()).sum().item()
acc = acc / X_test.shape[0]
return acc
accuracy = evaluate_accuracy(X_test, Y_test, net)
print("测试集的准确率:", accuracy)
输出:
(话说这张图刚弹出来的时候,我以为是在对我竖中指…)
(1080, 64, 64, 3)
(1080, 1)
(120, 64, 64, 3)
(120, 1)
(6,)
Y = 1
torch.Size([1080, 12288])
torch.Size([120, 12288])
torch.Size([1080, 1])
torch.Size([120, 1])
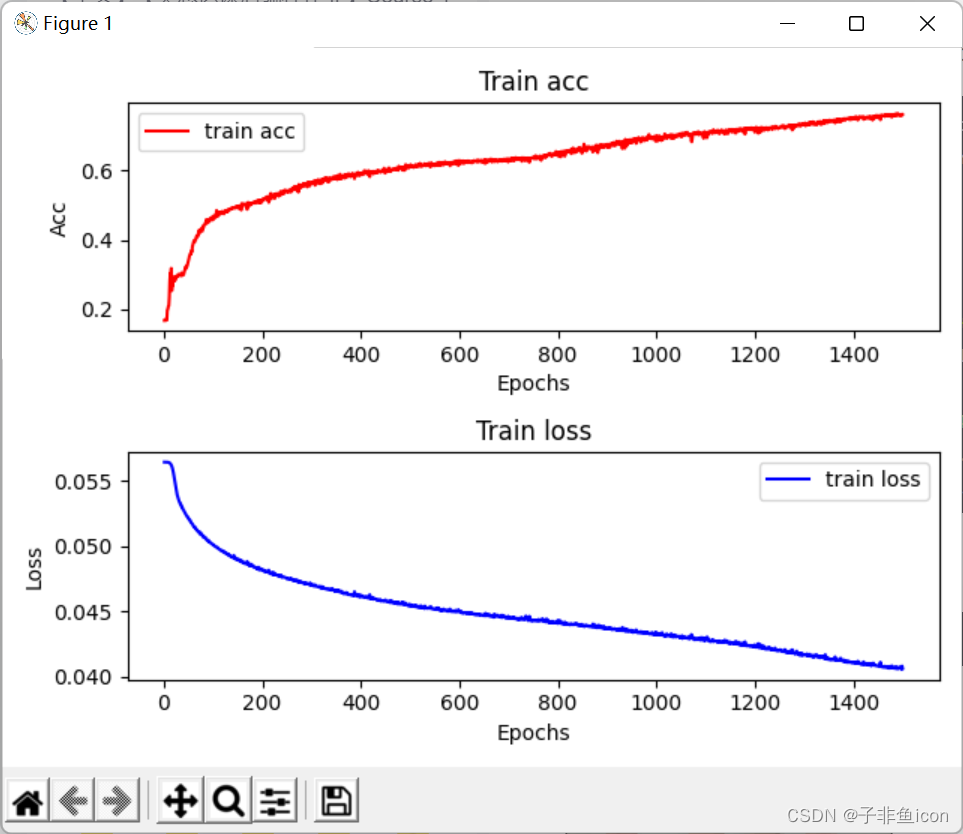
epoch 100, loss 0.0489, train acc 0.494
epoch 200, loss 0.0464, train acc 0.584
epoch 300, loss 0.0440, train acc 0.683
epoch 400, loss 0.0416, train acc 0.750
epoch 500, loss 0.0402, train acc 0.791
epoch 600, loss 0.0391, train acc 0.817
epoch 700, loss 0.0381, train acc 0.850
epoch 800, loss 0.0375, train acc 0.864
epoch 900, loss 0.0372, train acc 0.869
epoch 1000, loss 0.0368, train acc 0.877
epoch 1100, loss 0.0367, train acc 0.881
epoch 1200, loss 0.0363, train acc 0.891
epoch 1300, loss 0.0362, train acc 0.894
epoch 1400, loss 0.0361, train acc 0.897
epoch 1500, loss 0.0359, train acc 0.902
CPU的执行时间 = 169.80180710000002 秒
测试集的准确率: 0.7916666666666666
从结果可见,训练集上的准确率能达到90.2%,测试集上有79.17%,跟参考链接的取得的结果差不多,已经是可以识别0-5的手势符号了。
但其中需要注意的是,pytorch中的交叉熵损失函数并不需要你提前将标签转为one-hot编码,自己就可以处理。
另外,其CPU执行时间,也与你什么时候叉掉弹出来的结果图有关,所以为了精确确定时间,可以将损失图和准确率图设置为不予展示。
而且因为没有像之前的作业那样,使用固定的随机化种子初始参数,所以每次运行得到的最终结果,会有细微的差异。
使用自己拍的手势图:

from skimage.transform import resize
fname = r"D:\PyCharm files\deep learning\吴恩达\L2W3\5.jpg"
image = np.array(plt.imread(fname))
num_px = 64
print(image.shape)
my_image = resize(image,output_shape=(num_px,num_px)) # 修改尺寸为64*64
plt.imshow(my_image)
plt.show()
my_image = my_image.reshape((1, num_px*num_px*3)) # 转换成向量便于预测
my_image = torch.tensor(my_image, dtype=torch.float)
print(my_image.shape)
my_label_y = [5]
pred = net(my_image).detach().numpy()
pred_label = pred.argmax()
if my_label_y == pred_label:
print("预测正确!这个手势就是{}".format(my_label_y[0]))
else:
print("预测错误!你的模型认为这是{},但其实这个手势是{}".format(pred_label, my_label_y[0]))
输出:
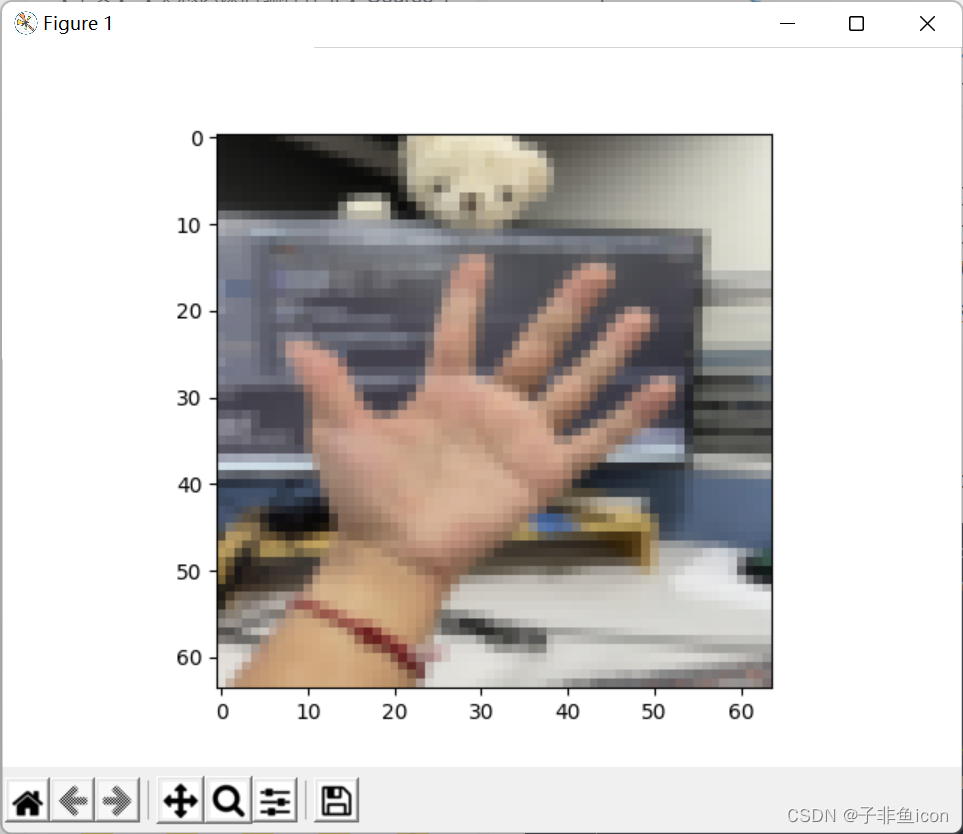
(3730, 2982, 3)
torch.Size([1, 12288])
预测错误!你的模型认为这是4,但其实这个手势是5
遇到了以前作业遇到的问题,这个识别不太行。但也懒得做其他的图了















 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









