一、垃圾信息检测
1.1如何实现
- 收集一些样本,告诉计算机哪些是垃圾信息【监督学习】
- 计算机自动寻找垃圾信息的共同特征【部分特征:发件人、是否群发、网址、元、赢、微信、免费】
- 在新信息中检测是否包含垃圾信息特征内容,判断其是否为垃圾信息
二、分类预测
2.1定义
- 根据数据类别与部分特征信息,自动寻找类别与特征信息的关系,判断一个新的样本属于哪种类别
2.2流程
- 特征信息
- 数据类别
- 寻找关系

2.3方法
三、逻辑回归
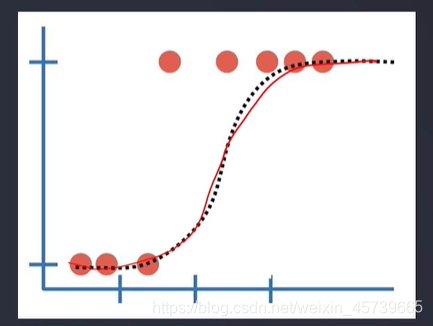
3.1更适合于分类场景的模型
3.2定义
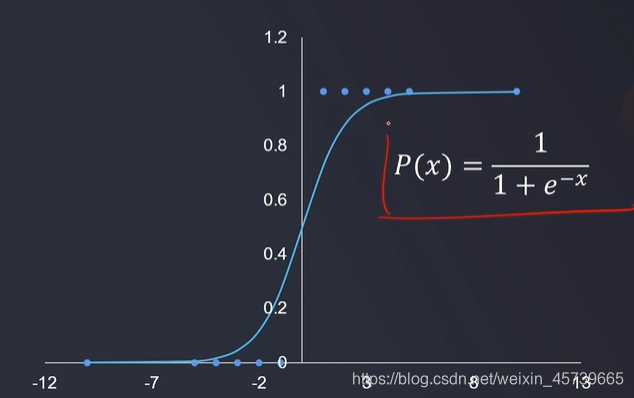
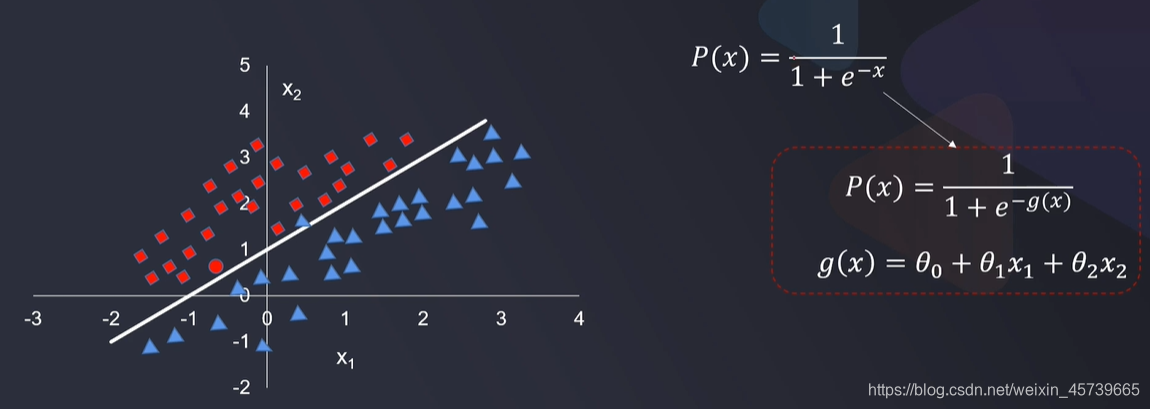
- 根据数据特征,计算样本归属于某一类类别的概率P(x),根据概率数值判断其所属类别
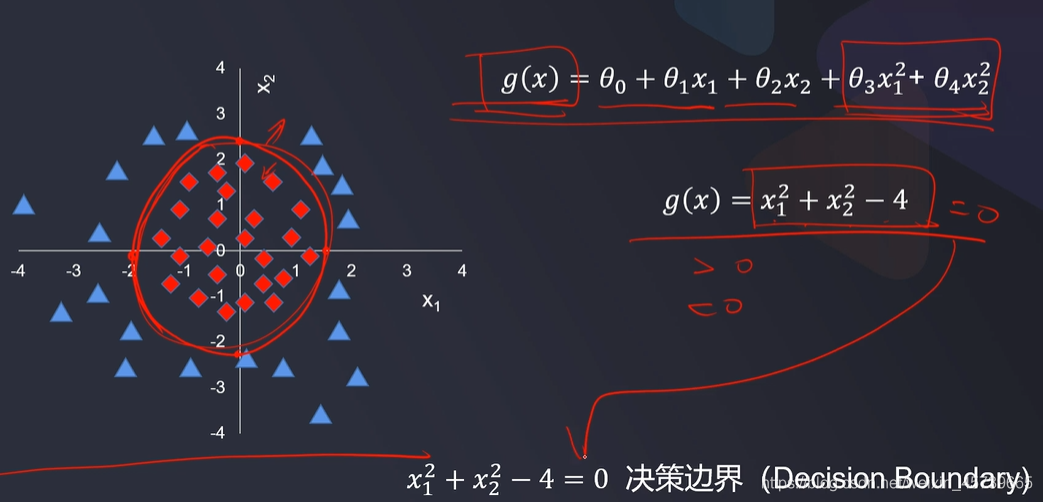
- 逻辑回归结合多项式边界函数可解决复杂的分类问题
- 模型求解的核心,在于寻找到合适的多项式边界函数
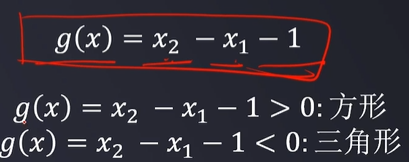
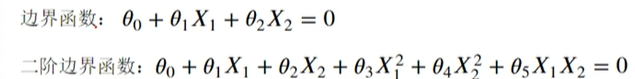
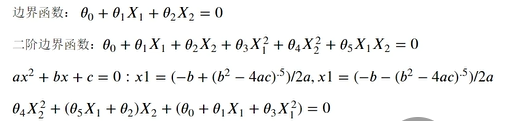
3.3模型求解
- 寻找损失函数最小值
- 分类问题,结果为离散数据,需要对损失函数进行调整以适应梯度下降法求解
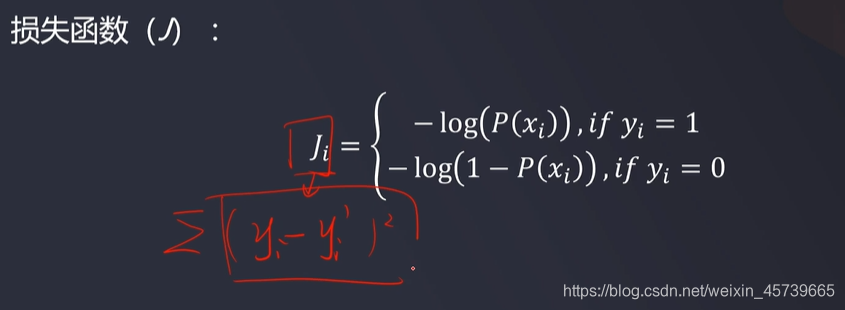
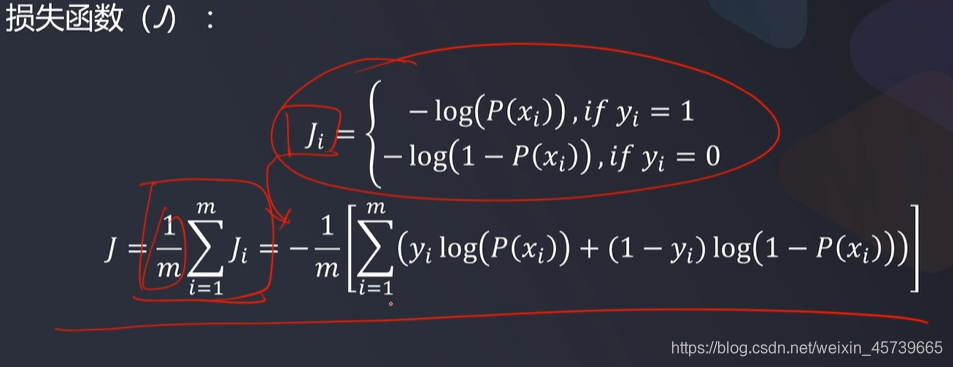

3.4流程

3.5求边界
3.5.1一次边界
theta0=model.intercept_[0]
theta1,theta2=model.coef_[0][0],model.coef_[0][1]
print(theta0,theta1,theta2)
x1=data.loc[:,'尺寸1']
X2_new=-(theta0+theta1*x1)/theta2
print(X2_new)
plt.plot(x,X2_new)
3.5.2二次边界
x1_2=x1*x1
x2_2=x2*x2
x1_x2=x1*x2
print(x1_2.shape,x2_2.shape,x1_x2.shape)
x_new={'x1':x1,'x2':x2,'x1_2':x1_2,'x2_2':x2_2,'x1_x2':x1_x2}
print(x_new)
x_new=pd.DataFrame(x_new)
print(x_new)
theta0=model2.intercept_
theta1,theta2,theta3,theta4,theta5=model2.coef_[0][0],model2.coef_[0][1],model2.coef_[0][2],model2.coef_[0][3],model2.coef_[0][4]
print(theta0,theta1,theta2,theta3,theta4,theta5)
x1_new=x1.sort_values()
a=theta4
b=theta5*x1_new+theta2
c=theta0+theta1*x1_new+theta3*x1_new*x1_new
x2_new_2=(-b+np.sqrt(b*b-4*a*c))/(2*a)
print(x2_new_2)
fig2=plt.figure()
abnormal=plt.scatter(data.loc[:,'pay1'][mask],data.loc[:,'pay2'][mask])
normal=plt.scatter(data.loc[:,'pay1'][~mask],data.loc[:,'pay2'][~mask])
plt.plot(x1_new,x2_new_2)
plt.title('pay1_pay2')
plt.xlabel("pay1")
plt.ylabel("pay2")
plt.legend((abnormal,normal),('abnormal','normal'))
plt.show()
3.6 预测消费者是否会购买商品,我们通常做些什么
- 前期工作:调研、讨论并确认影响购买意愿的因素;数据采集
- 数据预处理:异常数据处理、信息量化
- 建模与训练:从简单到复杂的决策边界模型
- 预测、评估、优化:引入不同的评估指标、尝试不同的模型
- 总结与汇报:结果整理并分析、输出项目报告
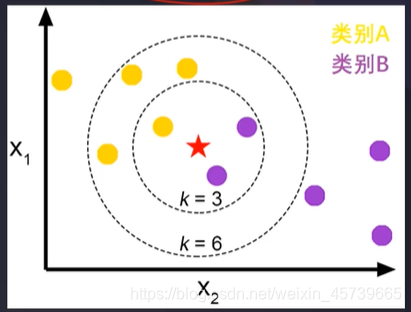
四、KNN
4.1建立、训练、预测、评估模型
from sklearn.neighbors import KNeighborsClassifier
KNN=KNeighborsClassifier(n_neighbors=3)
KNN.fit(X,y)
y_predict_knn=KNN.predict(X)
from sklearn.metrics import accuracy_score
accuracy=accuracy_score(y,y_predict_knn)
print(accuracy)
五、任务
5.1 基于线性二分类案例与数据,建立逻辑回归模型,计算并绘制边界曲线,并预测X1=1,X2=10数据点属于什么类别
- 基于数据,建立逻辑回归模型,评估模型表现
- 预测X1=1,X2=10时,该产品是良品还是次品
- 获取边界函数参数,绘制边界函数
import numpy as np
import pandas as pd
data=pd.read_csv("data1_lgicRg.csv")
data.head()
from matplotlib import pyplot as plt
fig1=plt.figure()
plt.scatter(data.loc[:,'尺寸1'],data.loc[:,'尺寸2'])
plt.title('Size1-Size2')
plt.xlabel("size1(x)")
plt.ylabel("size2(y)")
plt.show()
mask=data.loc[:,'y']==1
print(mask)
ok=plt.scatter(data.loc[:,'尺寸1'][mask],data.loc[:,'尺寸2'][mask])
ng=plt.scatter(data.loc[:,'尺寸1'][~mask],data.loc[:,'尺寸2'][~mask])
plt.title('Size1-Size2')
plt.xlabel('size1')
plt.ylabel('size2')
plt.legend((ok,ng), ('ok','ng'))
plt.show()
x=data.drop(['y'],axis=1)
y=data.loc[:,'y']
x.head()
from sklearn.linear_model import LogisticRegression
model=LogisticRegression()
print(model)
model.fit(x,y)
y_predict=model.predict(x)
print(y_predict)
y_test=model.predict([[1,10]])
print('ok'if y_test==1 else'ng')
from sklearn.metrics import accuracy_score
accuracy=accuracy_score(y, y_predict)
print(accuracy)
print(model.intercept_)
print(model.coef_)
theta0=model.intercept_[0]
theta1,theta2=model.coef_[0][0],model.coef_[0][1]
print(theta0,theta1,theta2)
x1=data.loc[:,'尺寸1']
X2_new=-(theta0+theta1*x1)/theta2
print(X2_new)
plt.plot(x,X2_new)
ok=plt.scatter(data.loc[:,'尺寸1'][mask],data.loc[:,'尺寸2'][mask])
ng=plt.scatter(data.loc[:,'尺寸1'][~mask],data.loc[:,'尺寸2'][~mask])
plt.title('Size1-Size2')
plt.plot(x1,X2_new,'g')
plt.xlabel('size1')
plt.ylabel('size2')
plt.legend((ok,ng), ('ok','ng'))
plt.show()
5.2基于数据,建立二阶多项式逻辑回归模型,根据预测,与线性逻辑回归模型结果进行对比
- 建立线性边界的逻辑回归模型,评估模型表现
- 建立二阶多项式边界的逻辑回归模型,对比其与线性边界的表现
- 预测pay1=80,pay2=20时对应消费是否为异常消费
- 获取边界函数参数、绘制边界函数
import numpy as np
import pandas as pd
data=pd.read_csv("data2_lgicRg.csv")
data.head()
from matplotlib import pyplot as plt
fig1=plt.figure()
plt.scatter(data.loc[:,'pay1'],data.loc[:,'pay2'])
plt.title('pay1_pay2')
plt.xlabel("pay1")
plt.ylabel("pay2")
plt.show()
mask=data.loc[:,'y']==1
print(mask)
fig1=plt.figure()
abnormal=plt.scatter(data.loc[:,'pay1'][mask],data.loc[:,'pay2'][mask])
normal=plt.scatter(data.loc[:,'pay1'][~mask],data.loc[:,'pay2'][~mask])
plt.title('pay1_pay2')
plt.xlabel("pay1")
plt.ylabel("pay2")
plt.legend((abnormal,normal),('abnormal','normal'))
plt.show()
x=data.drop(['y'],axis=1)
y=data.loc[:,'y']
print(x.shape,y.shape)
from sklearn.linear_model import LogisticRegression
model=LogisticRegression()
model.fit(x,y)
y_predict=model.predict(x)
print(y_predict)
from sklearn.metrics import accuracy_score
accuracy=accuracy_score(y,y_predict)
print(accuracy)
theta0=model.intercept_
theta1,theta2=model.coef_[0][0],model.coef_[0][1]
print(theta0,theta1,theta2)
x1=data.loc[:,'pay1']
x2=data.loc[:,'pay2']
x2_new=-(theta0+theta1*x1)/theta2
fig2=plt.figure()
abnormal=plt.scatter(data.loc[:,'pay1'][mask],data.loc[:,'pay2'][mask])
normal=plt.scatter(data.loc[:,'pay1'][~mask],data.loc[:,'pay2'][~mask])
plt.plot(x1,x2_new)
plt.title('pay1_pay2')
plt.xlabel("pay1")
plt.ylabel("pay2")
plt.legend((abnormal,normal),('abnormal','normal'))
plt.show()
x1_2=x1*x1
x2_2=x2*x2
x1_x2=x1*x2
print(x1_2.shape,x2_2.shape,x1_x2.shape)
x_new={'x1':x1,'x2':x2,'x1_2':x1_2,'x2_2':x2_2,'x1_x2':x1_x2}
print(x_new)
x_new=pd.DataFrame(x_new)
print(x_new)
model2=LogisticRegression()
model2.fit(x_new,y)
y2_predict=model2.predict(x_new)
print(y2_predict)
accuracy2=accuracy_score(y,y2_predict)
print(accuracy2)
theta0=model2.intercept_
theta1,theta2,theta3,theta4,theta5=model2.coef_[0][0],model2.coef_[0][1],model2.coef_[0][2],model2.coef_[0][3],model2.coef_[0][4]
print(theta0,theta1,theta2,theta3,theta4,theta5)
a=theta4
b=theta5*x1+theta2
c=theta0+theta1*x1+theta3*x1*x1
x2_new_2=(-b+np.sqrt(b*b-4*a*c))/(2*a)
print(x2_new_2)
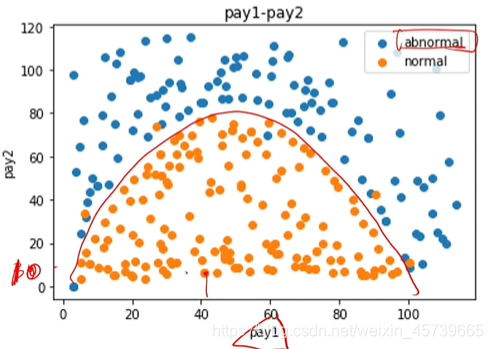
fig2=plt.figure()
abnormal=plt.scatter(data.loc[:,'pay1'][mask],data.loc[:,'pay2'][mask])
normal=plt.scatter(data.loc[:,'pay1'][~mask],data.loc[:,'pay2'][~mask])
plt.plot(x1,x2_new_2)
plt.title('pay1_pay2')
plt.xlabel("pay1")
plt.ylabel("pay2")
plt.legend((abnormal,normal),('abnormal','normal'))
plt.show()
x1_new=x1.sort_values()
a=theta4
b=theta5*x1_new+theta2
c=theta0+theta1*x1_new+theta3*x1_new*x1_new
x2_new_2=(-b+np.sqrt(b*b-4*a*c))/(2*a)
print(x2_new_2)
fig2=plt.figure()
abnormal=plt.scatter(data.loc[:,'pay1'][mask],data.loc[:,'pay2'][mask])
normal=plt.scatter(data.loc[:,'pay1'][~mask],data.loc[:,'pay2'][~mask])
plt.plot(x1_new,x2_new_2)
plt.title('pay1_pay2')
plt.xlabel("pay1")
plt.ylabel("pay2")
plt.legend((abnormal,normal),('abnormal','normal'))
plt.show()
X_test=np.array([[80,20]])
y_predict=model.predict(X_test)
print('abnormal' if y_predict==1 else'normal')
X_test=np.array([[80,20,80*80,20*20,80*20]])
y_predict=model2.predict(X_test)
print('abnormal' if y_predict==1 else'normal')








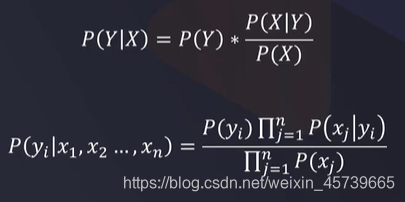















 715
715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









