







Look Closer to See Better
Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition
从论文的名称来看是看的更近看的更好,在通读了论文之后确实如此,看需要关注的区域,看的更加精细,结果的正确率也更加高。
文章中的创新点
- 提出了
APN注意力建议网络,可通过网络来自动生成最具判别性特征的精细化区域,并优化区域 - 交替的优化方式,先将分类的损失在3个尺度上的结果优化至收敛再修正卷积和分类层上的参数,最后来优化
APN网络 - 结合特征和特征的区域的相互作用对网络的学习
- 提出
Lrank函数,计算两个不同尺度之间的准确率损失
个人看法:
- 相比之前人工的标注,网络自动生成的区域准确性高,且可以对区域的合理调整
- 这种优化方式,可以降低训练时间,APN的参数才是网络的只要开销,再其他参数收敛的情况下,训练APN更快了
- 合理的将两个主要问题进行结合,且这俩个问题本来就具备相关性
- 使精细化的尺寸准确率更高
主要结构
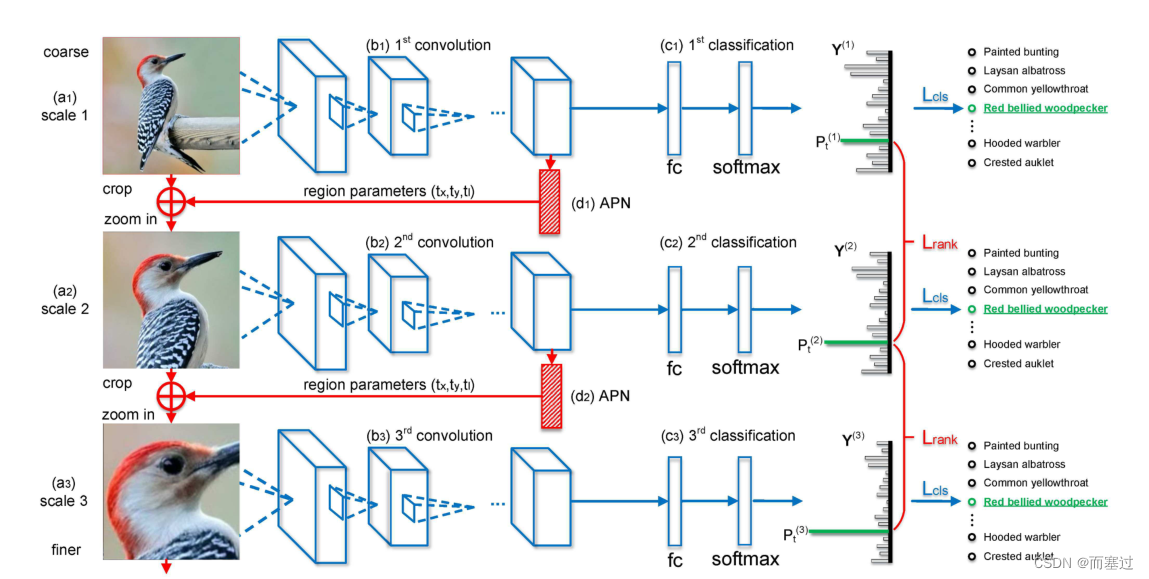
-
分类网络
-
将一张未经过处理的图片(
A1)放入网络(VGG19的conv5_4)来提取特征features -
将
features经过pooling,full-connection,softmax来获取预测分类结果 Y 1 Y^{1} Y1 -
将经过裁剪的图片
A2放入神经网络,获取更精细的特征features_scale_2,再次获取预测结果 Y 2 Y^2 Y2 -
将经过裁剪的图片
A3放入神经网络,获取更精细的特征features_scale_3,再次获取预测结果 Y 3 Y^3 Y3
-
-
注意力建立网络
-
将
features放入 A P N APN APN中获取区域参数信息 t x , t y , t l t_{x},t_{y},t_{l} tx,ty,tl -
通过位置信息对原始图片(
A1)进行裁剪,放大至原始比例,得到图片A2 -
将
features_scale_2放入 A P N APN APN获取更加精细的区域参数 t x 1 , t y 1 , t l 1 t_{x1},t_{y1},t_{l1} tx1,ty1,tl1 -
通过获取的更加精细的区域参数信息,对
A2进行裁剪,放大,得到图片A3
-
损失函数:
- L c l s L_{cls} Lcls:分类损失(优化卷积层和分类层的参数)
-
L
r
a
n
k
L_{rank}
Lrank:正确类别标签上的预测概率
- 比较相邻的两个尺度的分类,且要求在尺度放大的情况下,准确率提高(比margin多),否则损失为0(
来保证精细尺度下的图像更具有可高准确率)
- 比较相邻的两个尺度的分类,且要求在尺度放大的情况下,准确率提高(比margin多),否则损失为0(
区域裁剪
裁剪的图像框位置
假设原始图像的左上角是坐标系的原点
t
x
(
t
l
)
=
t
x
−
t
l
,
t
y
(
t
l
)
=
t
y
−
t
l
t
x
(
b
r
)
=
t
x
+
t
l
,
t
y
(
b
r
)
=
t
y
+
t
l
t
l
:
t
o
p
−
l
e
f
t
b
r
:
b
o
t
t
o
m
−
r
i
g
h
t
(
t
x
,
t
y
)
:
(
中
心
点
x
,
中
心
点
y
)
,
t
l
:
中
心
点
到
四
周
的
垂
直
距
离
t_{x(tl)} = t_{x} - t_{l} \ ,t_{y(tl)} = t_{y} - t_{l} \\t_{x(br)} = t_{x} + t_{l} \ ,t_{y(br)} = t_{y} + t_{l} \\ tl:top-left \\ br:bottom- right \\(t_{x},\ t_{y}):(中心点x ,中心点y), \ t_{l}:中心点到四周的垂直距离
tx(tl)=tx−tl ,ty(tl)=ty−tltx(br)=tx+tl ,ty(br)=ty+tltl:top−leftbr:bottom−right(tx, ty):(中心点x,中心点y), tl:中心点到四周的垂直距离
注意力掩码公式
h
(
x
)
=
1
{
1
+
e
−
k
x
}
M
(
⋅
)
=
[
h
(
x
−
t
x
(
t
l
)
)
−
h
(
x
−
t
x
(
b
r
)
)
]
⋅
[
h
(
y
−
t
y
(
t
l
)
)
−
h
(
y
−
t
y
(
b
r
)
)
]
\\h(x) = \frac{1}{\{1+e^{-kx}\}} \\M(·)=[h(x-t_{x(tl)})-h(x-t_{x(br)})]·[h(y-t_{y(tl)})-h(y-t_{y(br)})]
h(x)={1+e−kx}1M(⋅)=[h(x−tx(tl))−h(x−tx(br))]⋅[h(y−ty(tl))−h(y−ty(br))]
-
h ( x ) h(x) h(x)公式
- 当 x > 0 x>0 x>0时, e − k x = 0 e^{-kx}=0 e−kx=0,所以 h ( x ) = 1 h(x)=1 h(x)=1
- 当 x < 0 x<0 x<0时, e − k x = + ∞ e^{-kx}=+\infty e−kx=+∞,所以 h ( x ) = 0 h(x)=0 h(x)=0
-
M ( ⋅ ) M(·) M(⋅)公式
M ( ⋅ ) = 1 { if x ∈ [ t x ( t l ) , x ( b r ) ] if y ∈ [ t y ( t l ) , y ( b r ) ] M(·)=1\begin{cases} & \text{ if } x \in[t_{x(tl),x(br)}] \\ & \text{ if } y \in[t_{y(tl),y(br)}] \end{cases} M(⋅)=1{ if x∈[tx(tl),x(br)] if y∈[ty(tl),y(br)]
用于区分图像是否属于
建议区域中,只有当属于建议区域的时候,掩码值趋向于1,其余为0相比于分段函数, M ( ⋅ ) M(·) M(⋅)是连续可导的,故可以对位置的参数进行优化
放大
通过双线性插值法,对关注的区域放大至原始图像大小
注意力区域位置的参数优化
通过计算 t x , t y , t l t{x},t{y},t{l} tx,ty,tl导数来说明注意力机制,并展示了对区域裁剪的影响。文中提到导数范数的负平方是与人们感知的优化方向一致,故可以通过此来进行位置区域的优化。
导数的矩阵示意图
-
M
′
(
x
)
M'(x)
M′(x)
[ − 1 − 1 − 1 0 0 0 1 1 1 ] \begin{bmatrix} -1&-1 &-1 \\ 0& 0& 0\\ 1& 1 &1 \end{bmatrix} ⎣⎡−101−101−101⎦⎤
通过对x的求导来确定关注区域的左右位置移动 -
M
′
(
y
)
M'(y)
M′(y)
[ − 1 0 1 − 1 0 1 − 1 0 1 ] \begin{bmatrix} -1&0 &1 \\ -1& 0& 1\\ -1& 0 &1 \end{bmatrix} ⎣⎡−1−1−1000111⎦⎤
通过对y的求导来确定关注区域的上下位置移动 -
M
′
(
l
)
M'(l)
M′(l)
[ 1 1 1 1 − 1 1 1 1 1 ] \begin{bmatrix} 1&1 &1 \\ 1& -1& 1\\ 1& 1 &1 \end{bmatrix} ⎣⎡1111−11111⎦⎤
通过对l的求导来确定关注区域的放大缩小















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









