







第一章 Git入门
一、什么是版本控制
版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。
1. 版本控制的作用:
-
有了版本控制系统你就可以将选定的文件回溯到之前的状态,甚至将整个项目都回退到过去某个时间点的状态,你可以比较文件的变化细节,查出最后是谁修改了哪个地方,从而找出导致怪异问题出现的原因,又是谁在何时报告了某个功能缺陷等。
-
使用版本控制系统通常还意味着,就算你乱来一气把整个项目中的文件改的改删的删,你也照样可以轻松恢复到原先的样子。 但额外增加的工作量却微乎其微。
2. 本地版本控制系统
许多人习惯用复制整个项目目录的方式来保存不同的版本,或许还会改名加上备份时间以示区别。
这么做唯一的好处就是简单,但是特别容易犯错。 有时候会混淆所在的工作目录,一不小心会写错文件或者覆盖意想外的文件。
为了解决这个问题,人们很久以前就开发了许多种本地版本控制系统,大多都是采用某种简单的数据库来记录文件的历次更新差异。

3.集中版本控制系统
什么是集中版本控制系统:
集中版本控制系统都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。

集中化的版本控制的优点:
每个人都可以在一定程度上看到项目中的其他人正在做些什么。 而管理员也可以轻松掌控每个开发者的权限,并且管理一个 CVCS 要远比在各个客户端上维护本地数据库来得轻松容易。
集中化的版本控制的缺点:
最显而易见的缺点是中央服务器的单点故障。 如果宕机一小时,那么在这一小时内,谁都无法提交更新,也就无法协同工作。
如果中心数据库所在的磁盘发生损坏,又没有做恰当备份,毫无疑问你将丢失所有数据——包括项目的整个变更历史,只剩下人们在各自机器上保留的单独快照。
3.分布式版本控制系统
在这类系统中,像 Git、Mercurial、Bazaar 以及 Darcs 等,客户端并不只提取最新版本的文件快照, 而是把代码仓库完整地镜像下来,包括完整的历史记录。 这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。 因为每一次的克隆操作,实际上都是一次对代码仓库的完整备份。

这类系统都可以指定和若干不同的远端代码仓库进行交互。籍此,你就可以在同一个项目中,分别和不同工作小组的人相互协作。 你可以根据需要设定不同的协作流程
二. git是什么以及git的特点
特点一: 直接记录快照,而不是比较差异
Git 和其它版本控制系统大部分系统的主要差别在于 Git 对待数据的方式。其他版本控制系统以文件变更列表的方式存储信息, 将它们存储的信息看作是一组基本文件和每个文件随时间逐步累积的差异 。
其他版本控制系统原理图:

主要就是判断存储每个文件与初始版本的差异,进行版本控制。
git 版本系统控制原理图
存储项目随时间改变的快照

Git 更像是把数据看作是对小型文件系统的一系列快照。
在 Git 中,每当你提交更新或保存项目状态时,它基本上就会对当时的全部文件创建一个快照并保存这个快照的索引。 为了效率,如果文件没有修改,Git 不再重新存储该文件,而是只保留一个链接指向之前存储的文件。
特点二:大部分操作都是在本地执行
Git 中的绝大多数操作都只需要访问本地文件和资源,一般不需要来自网络上其它计算机的信息
特点三:Git保证数据的完整性
Git 中所有的数据在存储前都计算校验和,然后以校验和来引用。
Git 用以计算校验和的机制叫做 SHA-1 散列(hash,哈希)。 这是一个由 40 个十六进制字符(0-9 和 a-f)组成的字符串,基于 Git 中文件的内容或目录结构计算出来。
注意:Git 数据库中保存的信息都是以文件内容的哈希值来索引,而不是文件名。
特点四:Git一般只添加数据
你执行的 Git 操作,几乎只往 Git 数据库中 添加 数据。 你很难使用 Git 从数据库中删除数据,也就是说 Git 几乎不会执行任何可能导致文件不可恢复的操作。
特点五:Git状态 已修改(modified) 、 已暂存(staged)、已提交(committed)
- 已修改表示修改了文件,但还没保存到数据库中。
- 已暂存表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中
- 已提交表示数据已经安全地保存在本地数据库中。
Git 项目拥有三个阶段:工作区、暂存区以及 Git 目录。

工作区是对项目的某个版本独立提取出来的内容。
暂存区是一个文件,保存了下次将要提交的文件列表信息,一般在 Git 仓库目录中。
Git 仓库目录是 Git 用来保存项目的元数据和对象数据库的地方。
从其它计算机克隆仓库时,复制的Git 仓库目录中的数据。
基本的 Git 工作流程如下:
-
在工作区中修改文件。
-
将你想要下次提交的更改选择性地暂存,这样只会将更改的部分添加到暂存区。
-
提交更新,找到暂存区的文件,将快照永久性存储到 Git 目录。
三、Git的安装
官方版本可以在 Git 官方网站下载。 打开 https://git-scm.com/download/win,下载会自动开始。

选择安装路径,一直下一步即可!
安装结束后,进入测试阶段
- 打开

- 测试 以下链接,git clone git://git.kernel.org/pub/scm/git/git.git

- 出现这里,代表正常

git的简单的配置用户信息
安装完 Git 之后,要做的第一件事就是设置你的用户名和邮件地址。 这一点很重要,因为每一个 Git 提交都会使用这些信息,它们会写入到你的每一次提交中,不可更改:
git config --global user.name "John Doe"
git config --global user.email johndoe@example.com
用户名,用户邮箱配置自己的。
再次强调,如果使用了 --global 选项,那么该命令只需要运行一次,因为之后无论你在该系统上做任何事情, Git 都会使用那些信息。 当你想针对特定项目使用不同的用户名称与邮件地址时,可以在那个项目目录下运行没有 --global 选项的命令来配置。
检查配置信息
如果想要检查你的配置,可以使用 git config --list 命令来列出所有 Git 当时能找到的配置。

结束!!!
第二章 Git 基础
一、获取 Git 仓库
有两种获取Git项目仓库的方式
- 将本地目录初始化为Git仓库
- 从其他服务器克隆一个已经存在的Git仓库
1. 将本地目录初始化为Git仓库
step1:
进入要初始化的项目路径
step2:
执行 `git init`

该命令将创建一个名为 .git 的子目录,这个子目录含有你初始化的 Git 仓库中所有的必须文件,这些文件是 Git 仓库的骨干。
如果在一个已经存在的文件的文件夹进行版本控制,那么我们就要开始追踪这些文件进行初始提交。
git add命令来指定所需的文件来追踪,然后 git commit
$ git add *.c
$ git add LICENSE
$ git commit -m 'initial project version'

2. 克隆现有的仓库
如果你想获得一份已经存在了的 Git 仓库的拷贝,就要用到 git clone命令。
Git 克隆的是该 Git 仓库服务器上的几乎所有数据,而不是仅仅复制完成你的工作所需要文件。 当你执行 git clone命令的时候,默认配置下远程 Git 仓库中的每一个文件的每一个版本都将被拉取下来。
https://github.com/loloazz/gittest.git
克隆仓库的命令 git clone < url >。比如我要克隆 https://github.com/loloazz/gittest.git
可以使用
git clone https://github.com/loloazz/gittest.git
注意在克隆时的路径。。。。
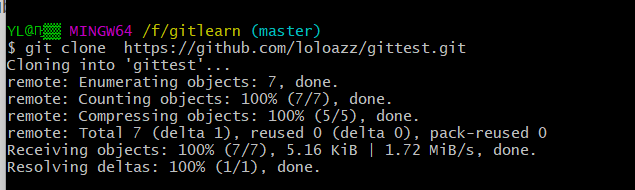

已经克隆下来了。

原来的仓库。如何在Github创建仓库,后面在讲。
如果你想在克隆远程仓库的时候,自定义本地仓库的名字,你可以通过额外的参数指定新的目录名:
git clone https://github.com/loloazz/gittest.git fristGit


与上面的项目一致!!
3. 记录每次更新到仓库
工作目录下的每一个文件都无外乎这两种状态:已跟踪 或 未跟踪。
已跟踪的文件就是 Git 已经知道的文件。
工作目录中除已跟踪文件外的其它所有文件都属于未跟踪文件
初次克隆某个仓库的时候,工作目录中的所有文件都属于已跟踪文件,并处于未修改状态,因为 Git 刚刚检出了它们, 而你尚未编辑过它们。
编辑过某些文件之后,由于自上次提交后你对它们做了修改,Git 将它们标记为已修改文件。 在工作时,你可以选择性地将这些修改过的文件放入暂存区,然后提交所有已暂存的修改,如此反复。
检查当前文件状态
可以用git status命令查看哪些文件处于什么状态。
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
fristGit/
nothing added to commit but untracked files present (use "git add" to track)
这说明你现在的工作目录相当干净。换句话说,所有已跟踪文件在上次提交后都未被更改过。 此外,上面的信息还表明,当前目录下没有出现任何处于未跟踪状态的新文件,否则 Git 会在这里列出来。 最后,该命令还显示了当前所在分支,并告诉你这个分支同远程服务器上对应的分支没有偏离。 现在,分支名是“master”,这是默认的分支名。
现在,让我们在项目下创建一个新的 README 文件。 如果之前并不存在这个文件,使用 git status 命令,你将看到一个新的未跟踪文件:
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
README
fristGit/
nothing added to commit but untracked files present (use "git add" to track)
在状态报告中可以看到新建的 README 文件出现在 Untracked files 下面。 未跟踪的文件意味着 Git 在之前的快照(提交)中没有这些文件;Git 不会自动将之纳入跟踪范围,除非你明明白白地告诉它“我需要跟踪该文件”。
跟踪新文件
使用命令 git add开始跟踪一个文件。 所以,要跟踪 README 文件
$ git add README
warning: LF will be replaced by CRLF in README.
The file will have its original line endings in your working directory
$ git status
On branch master
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file: README
只要在 Changes to be committed 这行下面的,就说明是已暂存状态。
跟踪文件夹
git add命令使用文件或目录的路径作为参数;如果参数是目录的路径,该命令将递归地跟踪该目录下的所有文件。
查看提交历史
在提交了若干更新,又或者克隆了某个项目之后,你也许想回顾下提交历史。 完成这个任务最简单而又有效的工具是 git log命令。
4. 远程仓库的使用
为了能在任意 Git 项目上协作,你需要知道如何管理自己的远程仓库。 远程仓库是指托管在因特网或其他网络中的你的项目的版本库。 你可以有好几个远程仓库,通常有些仓库对你只读,有些则可以读写。 与他人协作涉及管理远程仓库以及根据需要推送或拉取数据。 管理远程仓库包括了解如何添加远程仓库、移除无效的远程仓库、管理不同的远程分支并定义它们是否被跟踪。
查看远程仓库
如果想查看你已经配置的远程仓库服务器,可以运行git remote 命令。 它会列出你指定的每一个远程服务器的简写。
如果你已经克隆了自己的仓库,那么至少应该能看到 origin ——这是 Git 给你克隆的仓库服务器的默认名字:
$ git remote
origin
你也可以指定选项-v,会显示需要读写远程仓库使用的 Git 保存的简写与其对应的 URL
$ git remote -v
origin https://github.com/loloazz/gittest.git (fetch)
origin https://github.com/loloazz/gittest.git (push)
添加远程仓库
运行git remote add <shortname> <url> 添加一个新的远程 Git 仓库,同时指定一个方便使用的简写:
$ git remote add yl https://github.com/loloazz/gittest.git
$ git remote
origin
yl
现在你可以在命令行中使用字符串yl 来代替整个 URL。 例如,如果你想拉取 Paul 的仓库中有但你没有的信息,可以运行git fetch yl: fetch 是取得的意思。
$ git fetch yl
From https://github.com/loloazz/gittest
* [new branch] main -> yl/main
第三章
几乎所有的版本控制系统都以某种形式支持分支。 使用分支意味着你可以把你的工作从开发主线上分离开来,以免影响开发主线。 在很多版本控制系统中,这是一个略微低效的过程——常常需要完全创建一个源代码目录的副本。对于大项目来说,这样的过程会耗费很多时间。
有人把 Git 的分支模型称为它的“必杀技特性”,也正因为这一特性,使得 Git 从众多版本控制系统中脱颖而出。 为何 Git 的分支模型如此出众呢? Git 处理分支的方式可谓是难以置信的轻量,创建新分支这一操作几乎能在瞬间完成,并且在不同分支之间的切换操作也是一样便捷。 与许多其它版本控制系统不同,Git 鼓励在工作流程中频繁地使用分支与合并,哪怕一天之内进行许多次。 理解和精通这一特性,你便会意识到 Git 是如此的强大而又独特,并且从此真正改变你的开发方式。
分支简介
为了真正理解 Git 处理分支的方式,我们需要回顾一下 Git 是如何保存数据的。
Git 保存的不是文件的变化或者差异,而是一系列不同时刻的 快照 。
在进行提交操作时,Git 会保存一个提交对象(commit object)。 知道了 Git 保存数据的方式,我们可以很自然的想到——该提交对象会包含一个指向暂存内容快照的指针。 但不仅仅是这样,该提交对象还包含了作者的姓名和邮箱、提交时输入的信息以及指向它的父对象的指针。 首次提交产生的提交对象没有父对象,普通提交操作产生的提交对象有一个父对象, 而由多个分支合并产生的提交对象有多个父对象,
为了更加形象地说明,我们假设现在有一个工作目录,里面包含了三个将要被暂存和提交的文件。 暂存操作会为每一个文件计算校验和(使用我们在 起步 中提到的 SHA-1 哈希算法),然后会把当前版本的文件快照保存到 Git 仓库中 (Git 使用 blob 对象来保存它们),最终将校验和加入到暂存区域等待提交:
$ git add README test.rb LICENSE
$ git commit -m 'The initial commit of my project'
当使用 git commit 进行提交操作时,Git 会先计算每一个子目录(本例中只有项目根目录)的校验和, 然后在 Git 仓库中这些校验和保存为树对象。随后,Git 便会创建一个提交对象, 它除了包含上面提到的那些信息外,还包含指向这个树对象(项目根目录)的指针。 如此一来,Git 就可以在需要的时候重现此次保存的快照。
现在,Git 仓库中有五个对象:三个 blob 对象(保存着文件快照)、一个 树 对象 (记录着目录结构和 blob 对象索引)以及一个 提交 对象(包含着指向前述树对象的指针和所有提交信息)。

首次提交对象及其树结构。
做些修改后再次提交,那么这次产生的提交对象会包含一个指向上次提交对象(父对象)的指针。
提交对象及其父对象。

Git 的分支,其实本质上仅仅是指向提交对象的可变指针。 Git 的默认分支名字是 master。 在多次提交操作之后,你其实已经有一个指向最后那个提交对象的 master 分支。 master 分支会在每次提交时自动向前移动。
注意:
Git 的 master 分支并不是一个特殊分支。 它就跟其它分支完全没有区别。 之所以几乎每一个仓库都有 master 分支,是因为
git init 命令默认创建它,并且大多数人都懒得去改动它。

分支及其提交历史。
分支创建
Git 是怎么创建新分支的呢? 很简单,它只是为你创建了一个可以移动的新的指针。 比如,创建一个 testing 分支, 你需要使用 git branch命令:
$ git branch testing
这会在当前所在的提交对象上创建一个指针。

两个指向相同提交历史的分支。
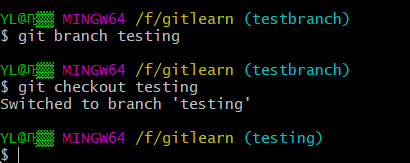
那么,Git 又是怎么知道当前在哪一个分支上呢? 也很简单,它有一个名为 HEAD 的特殊指针。 请注意它和许多其它版本控制系统(如 Subversion 或 CVS)里的 HEAD 概念完全不同。 在 Git 中,它是一个指针,指向当前所在的本地分支(译注:将 HEAD 想象为当前分支的别名)。 在本例中,你仍然在 master 分支上。 因为 git branch 命令仅仅 创建 一个新分支,并不会自动切换到新分支中去。

HEAD 指向当前所在的分支。
正如你所见,当前 master 和 testing 分支均指向校验和以 f30ab 开头的提交对象。
分支切换
要切换到一个已存在的分支,你需要使用 git checkout命令。 我们现在切换到新创建的 testing 分支去:
$ git checkout testing
这样 HEAD 就指向 testing 分支了。
HEAD 指向当前所在的分支。

那么,这样的实现方式会给我们带来什么好处呢? 现在不妨再提交一次:
$ vim test.rb
$ git commit -a -m 'made a change'
HEAD 分支随着提交操作自动向前移动。

如图所示,你的 testing 分支向前移动了,但是 master 分支却没有,它仍然指向运行 git checkout 时所指的对象。 这就有意思了,现在我们切换回 master 分支看看:
$ git checkout master

检出时 HEAD 随之移动。
这条命令做了两件事。 一是使 HEAD 指回 master 分支,二是将工作目录恢复成 master 分支所指向的快照内容。 也就是说,你现在做修改的话,项目将始于一个较旧的版本。 本质上来讲,这就是忽略 testing 分支所做的修改,以便于向另一个方向进行开发。
总结: 分支切换会改变你工作目录中的文件 在切换分支时,一定要注意你工作目录里的文件会被改变。
如果是切换到一个较旧的分支,你的工作目录会恢复到该分支最后一次提交时的样子。 如果 Git 不能干净利落地完成这个任务,它将禁止切换分支。
我们不妨再稍微做些修改并提交:
$ vim test.rb
$ git commit -a -m 'made other changes'
现在,这个项目的提交历史已经产生了分叉(参见 项目分叉历史)。 因为刚才你创建了一个新分支,并切换过去进行了一些工作,随后又切换回 master 分支进行了另外一些工作。 上述两次改动针对的是不同分支:你可以在不同分支间不断地来回切换和工作,并在时机成熟时将它们合并起来。 而所有这些工作,你需要的命令只有branch、checkout 和 commit。

项目分叉历史。
创建新分支的同时切换过去
通常我们会在创建一个新分支后立即切换过去,这可以用 git checkout -b <newbranchname>一条命令搞定。
分支的新建与合并
让我们来看一个简单的分支新建与分支合并的例子,实际工作中你可能会用到类似的工作流。 你将经历如下步骤:
- 开发某个网站。
- 为实现某个新的用户需求,创建一个分支。
- 在这个分支上开展工作。
正在此时,你突然接到一个电话说有个很严重的问题需要紧急修补。 你将按照如下方式来处理:
-
切换到你的线上分支(production branch)。
-
为这个紧急任务新建一个分支,并在其中修复它。
-
在测试通过之后,切换回线上分支,然后合并这个修补分支,最后将改动推送到线上分支。
-
切换回你最初工作的分支上,继续工作。
新建分支
我们假设你正在你的项目上工作,并且在 master 分支上已经有了一些提交。

你已经决定要解决你的公司使用的问题追踪系统中的 #53问题。 想要新建一个分支并同时切换到那个分支上,你可以运行一个带有 -b参数的git checkout命令:
$ git checkout -b iss53
Switched to a new branch "iss53"
它是下面两条命令的简写:
$ git branch iss53
$ git checkout iss53

你继续在#53 问题上工作,并且做了一些提交。 在此过程中,iss53 分支在不断的向前推进,因为你已经检出到该分支 (也就是说,你的HEAD指针指向了 iss53 分支)
$ vim index.html
$ git commit -a -m 'added a new footer [issue 53]'

现在你接到那个电话,有个紧急问题等待你来解决。 有了 Git 的帮助,你不必把这个紧急问题和 iss53 的修改混在一起, 你也不需要花大力气来还原关于53# 问题的修改,然后再添加关于这个紧急问题的修改,最后将这个修改提交到线上分支。 你所要做的仅仅是切换回 master 分支。
但是,在你这么做之前,要留意你的工作目录和暂存区里那些还没有被提交的修改, 它可能会和你即将检出的分支产生冲突从而阻止 Git 切换到该分支。 最好的方法是,在你切换分支之前,保持好一个干净的状态。 有一些方法可以绕过这个问题(即,暂存(stashing) 和 修补提交(commit amending))
$ git checkout master
Switched to branch 'master'
这个时候,你的工作目录和你在开始 #53 问题之前一模一样,现在你可以专心修复紧急问题了。 请牢记:当你切换分支的时候,Git 会重置你的工作目录,使其看起来像回到了你在那个分支上最后一次提交的样子。 Git 会自动添加、删除、修改文件以确保此时你的工作目录和这个分支最后一次提交时的样子一模一样。
接下来,你要修复这个紧急问题。 我们来建立一个 hotfix 分支,在该分支上工作直到问题解决:
$ git checkout -b hotfix
Switched to a new branch 'hotfix'
$ vim index.html
$ git commit -a -m 'fixed the broken email address'
[hotfix 1fb7853] fixed the broken email address
1 file changed, 2 insertions(+)
基于 master 分支的紧急问题分支(hotfix branch)。

你可以运行你的测试,确保你的修改是正确的,然后将hotfix分支合并回你的 master 分支来部署到线上。 你可以使用git merge命令来达到上述目的:
$ git checkout master
$ git merge hotfix
Updating f42c576..3a0874c
Fast-forward
index.html | 2 ++
1 file changed, 2 insertions(+)
在合并的时候,你应该注意到了“快进(fast-forward)”这个词。 由于你想要合并的分支 hotfix 所指向的提交 C4 是你所在的提交 C2 的直接后继, 因此 Git 会直接将指针向前移动。换句话说,当你试图合并两个分支时, 如果顺着一个分支走下去能够到达另一个分支,那么 Git 在合并两者的时候, 只会简单的将指针向前推进(指针右移),因为这种情况下的合并操作没有需要解决的分歧——这就叫做 “快进(fast-forward)”。
现在,最新的修改已经在 master 分支所指向的提交快照中,你可以着手发布该修复了。

关于这个紧急问题的解决方案发布之后,你准备回到被打断之前时的工作中。 然而,你应该先删除 hotfix 分支,因为你已经不再需要它了 —— master 分支已经指向了同一个位置。 你可以使用带-d选项的git branch 命令来删除分支:
$ git branch -d hotfix
Deleted branch hotfix (3a0874c).
现在你可以切换回你正在工作的分支继续你的工作,也就是针对 #53问题的那个分支(iss53 分支)。

你在hotfix 分支上所做的工作并没有包含到iss53分支中。 如果你需要拉取 hotfix 所做的修改,你可以使用 git merge master 命令将 master 分支合并入iss53 分支,或者你也可以等到 iss53 分支完成其使命,再将其合并回 master 分支。
你已经修正了 #53 问题,并且打算将你的工作合并入 master 分支。 为此,你需要合并 iss53 分支到 master 分支,这和之前你合并 hotfix 分支所做的工作差不多。 你只需要检出到你想合并入的分支,然后运行 git merge 命令:
$ git checkout master
Switched to branch 'master'
$ git merge iss53
Merge made by the 'recursive' strategy.
index.html | 1 +
1 file changed, 1 insertion(+)
这和你之前合并 hotfix分支的时候看起来有一点不一样。 在这种情况下,你的开发历史从一个更早的地方开始分叉开来(diverged)。 因为,master 分支所在提交并不是iss53分支所在提交的直接祖先,Git 不得不做一些额外的工作。 出现这种情况的时候,Git 会使用两个分支的末端所指的快照(C4 和 C5)以及这两个分支的公共祖先(C2),做一个简单的三方合并。

和之前将分支指针向前推进所不同的是,Git 将此次三方合并的结果做了一个新的快照并且自动创建一个新的提交指向它。 这个被称作一次合并提交,它的特别之处在于他有不止一个父提交。

既然你的修改已经合并进来了,就不再需要 iss53 分支了。 现在你可以在任务追踪系统中关闭此项任务,并删除这个分支。
$ git branch -d iss53














 1666
1666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









