







一、详细理解误差(error)与偏差(bias)和方差(variance)
1.偏差与方差

对图片的解释:
准:bias低,模型在样本上拟合地好不好。low bias相当于打靶时都落在靶心附近,但是手不一定稳(分布比较乱)。
确:variance低,模型在测试集上的表现好。low variance相当于打靶时手很稳,分布紧密,但是不一定在靶心附近。
与模型复杂度的关系:模型约复杂,拟合能力越好,对训练样本拟合地越好,偏差越小,但学到的非全局特征也多,方差就越大。所以,模型的寻优就是在bias 和variance直接寻找trade-off。
2.error与bias和variance的关系
总体上说,误差等于偏差加上方差,具体来看公式推导。
根据周志华《机器学习》,对偏差和方差以及噪声的定义:
偏差度量了学习算法的期望预测与真实结果的偏离程度,刻画了模型的拟合能力;
方差度量了同样大小的训练集的变动所导致的学习性能的变化,刻画了数据扰动造成的影响;
噪声表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
对一个测试样本,令为在数据集上的标记(不一定是正确的,可能有噪声);
令为的真实标记(一定是正确的);
令为在训练集上学到的模型,且在上给出的预测;
算法的期望预测为:

使用样本数相同的不用训练集产生的方差为:

(根据方差的定义推导: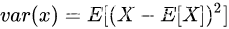 )
)
噪声为:

偏差等于期望的输出与真实标记之差:

假设噪声的期望值为0,即:
以线性回归的MSE误差为例:

公式说明:第四行,由于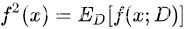 ,而
,而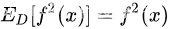 (因为
(因为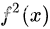 是一个常数),故第三项等于0。第八行,因为噪声的期望值为0,即
是一个常数),故第三项等于0。第八行,因为噪声的期望值为0,即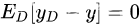 ,故第四项为0。
,故第四项为0。
这就是误差与偏差和方差的关系了。
3.过拟合与欠拟合
过拟合:bias很小,而variance很大,说明模型过于复杂,把训练样本的自身的非全局特征都学过去了。
欠拟合:bias很大。模型太简单,对训练样本的一般性质没有学到位。
二、鞍点
1.什么是鞍点
定义:
目标函数在此点上的梯度为0,但从该点出发的一个方向是函数的极大值点,而在另一个点方向是函数的极小值点。

2.鞍点给学习带来的困难
在机器学习算法寻优的过程中,鞍点造成的困难要比局部最小更麻烦;因为
1):在高位参数空间呢,鞍点存在更多;
2):大量表面局部最优解,对模型来说已经足够好了。
如果使用的是传统的梯度下降算法(GD),或者叫做最速梯度下降,沿着当前位置的最小梯度方向走,很容易陷在鞍点。
3.判断鞍点的充分条件
海森矩阵(Hession matrix)是由函数的二阶偏导组成的方阵:

根据矩阵的特征值可以将矩阵分成:
正定矩阵:所有特征值都大于零;
负定矩阵:所有特征值都小于零;
不定矩阵:特征值有正有负。
1.如果目标函数某一稳定点的H是正定的,即所有特征值都是正的,这个点是(局部)最小值,因为无论往什么方向看,导数都是正的。
2.如果H是负定的,说明这个点是(局部)最大值,同理,因为无论往什么方向看,导数都是负的。
3.如果H是不定的,导数有正有负,说明这个点是一个鞍点。
4.如果特征值都是0,这种情况无法判断没需要参照更高维度的导数。
注意以上对于鞍点的判断是充分条件,如果H不是不定矩阵,不能得出其一定不是鞍点的结论,或者说,如果一个点是鞍点,不能反推出这个点的H矩阵一定是不定矩阵。
4.逃离鞍点的方法
可以采用随机梯度下降法,或者小批量随机梯度下降法,引入一定的随机噪声,可以跳出鞍点。
或者采用更高级的优化方法:如深度学习中广泛使用的动量法,RMSprop,Adam等。
三、梯度下降
以线性回归为例:

1.批量梯度下降(BGD):一次迭代对所有m个训练样本都遍历一遍

也被称为最速梯度下降,迭代的步数较少,但要一次遍历所有数据,数据量较大时会比较耗时。
2.随机梯度下降(SGD):对每个样本来进行一次更新迭代


SGD的噪音比BGD多,每次迭代的路线并不一定是最优的,但整体是向着最优的方向,而且SGD可以跳出局部最小和鞍点。
3.小批量梯度下降(MBGD)
在BGD与SGD之间去一个平衡,兼具两者的特点,既保证梯度方向的正确,也加快了速度,又引入了一定的噪声。
假设批量大小为k:

选择问题:
如果数据量不大,使用批量梯度下降;
如果数据量较大,使用 小批量随机梯度下降,具体需要调参,看硬件条件
代码如下:
#下面实现的是批量梯度下降法
def batchGradientDescent(x, y, theta, alpha, m, maxIterations):
xTrains = x.transpose() #得到它的转置
for i in range(0, maxIterations):
hypothesis = np.dot(x, theta)
loss = hypothesis - y
# print loss
gradient = np.dot(xTrains, loss) / m #对所有的样本进行求和,然后除以样本数
theta = theta - alpha * gradient
return theta
#下面实现的是随机梯度下降法
def StochasticGradientDescent(x, y, theta, alpha, m, maxIterations):
data = []
for i in range(10):
data.append(i)
xTrains = x.transpose() #变成3*10,没一列代表一个训练样本
# 这里随机挑选一个进行更新点进行即可(不用像上面一样全部考虑)
for i in range(0,maxIterations):
hypothesis = np.dot(x, theta)
loss = hypothesis - y #注意这里有10个样本的,我下面随机抽取一个进行更新即可
index = random.sample(data,1) #任意选取一个样本点,得到它的下标,便于下面找到xTrains的对应列
index1 = index[0] #因为回来的时候是list,我要取出变成int,更好解释
gradient = loss[index1]*x[index1] #只取这一个点进行更新计算
theta = theta - alpha * gradient.T
return theta
四、交叉验证法(corss validation)
先将数据集D划分成k个大小相似的互斥子集:

每个子集的分布尽量保持一致
训练时,每次使用k-1个子集作为训练集,1个子集作为测试集,这样就有种选择,进行k-1次训练和测试,返回k个结果的均值。
一般也称为k折交叉验证法,可以取5,10,20等。
子集的划分可能存在多种方式,为了减小因样本划分不同而引入的差别,折交叉验证通常需要随机使用不同的划分重复p次,并取均值,这叫做p次k折交叉验证。
k越大,模型的实际训练效果与样本数据集D的期望预测结果越相似,特别的,当k等于中全部样本m个数时,意味着只保留一个样本作为测试集,也被称为留一法。
留一法的评估结果比较准确,但是在样本较大时很费时间。
五、归一化和标准化
以房价预测为例,令

其中是房间数,代表面积,面积的数值可能远远大于房间数。
未归一化时,目标函数的等高线如下图所示:
未归一化时:

在寻找最优解的时候,由于数据尺度不同,等高线比较“扁”,寻优路径歪歪扭扭。
归一化后:

归一化之后,等高线比较“圆”,寻优过程更加平缓,更容易收敛。
归一化的公式:

标准化公式:

归一化和标准化的本质都是线性变换,先压缩,后平移,线性变换不会改变数值的排序,反而还能提高数据的表现。
归一化与标准化的区别:
归一化:缩放仅跟数据的最大值,最小值的差别有关;输出在[0,1]之间;
标准化:跟每个数据都有关;输出范围是
什么时候用哪个?
1)对输出范围有要求时,用归一化;
2)数据较为稳定,不存在极值和噪音,用归一化;
3)若数据存在较多极端值和噪音,用标准化
一般都先采用标准化看看效果。
六、回归模型的评价指标
一般常用的评价指标有:
RMSE(平方根误差):

MAE(平均绝对误差):

MSE(平均平方误差):
















 1214
1214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









