







reamsets-datacollector-all-3.21.0 安装步骤
1.安装jdk8
jdk安装网上教程很多,在这就不详细记录了
2.下载 streamsets
官网 https://archives.streamsets.com/index.html 注册账户后
下载 Full Tarball Tarball for Linux (Tarball sha1)
Linux wget下载证书报错末尾加上–no-check-certificate
在下载的过程中 我们可以创建几个能用到的文件夹
mkdir /data/streamsets/data
mkdir /data/streamsets/log 存放log的地方
mkdir /data/streamsets/resources
3.下载完成后解压
cd /opt/streamsets-datacollector-3.21.0/
tar zxf streamsets-datacollector-all-3.21.0.tgz
4.配置
1)配置环境变量
切换root用户
vi /etc/profile
在文件最后添加
export SDC_DIST=/opt/streamsets-datacollector-3.21.0
export SDC_JAVA_OPTS="${SDC_JAVA_OPTS} -Xmx10240m -Xms10240m -server" 这个加不加都行
保持退出
wq
应用环境变量
source /etc/profile
测试环境变量
echo $SDC_DIST
2)配置strameset环境
cd /opt/streamsets-datacollector-3.21.0/libexec/
vim sdc-env.sh
这块改下 jvm 看需求改 改不改都行
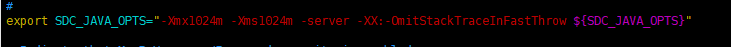
在就是添加
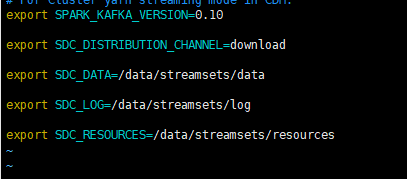
export SDC_DATA=/data/streamsets/data
export SDC_LOG=/data/streamsets/log
export SDC_RESOURCES=/data/streamsets/resources
3)配置 sdc.properties
cd /opt/streamsets-datacollector-3.21.0/etc
在这个配置文件里主要配置这几项
production.maxBatchSize 一次抽取数量 (按照自身需求和硬件配置来调整)
runner.thread.pool.size 一次可以开多少个线程,换句话说就是能开几个pipeline 如果你需要的抽取的表比较多 建议多开启 要不会报错
其他的 暂时都不用动,如果有需求可以去官网看看
4)如果需要kafka hbase等 需要配置hosts文件
5)如果需要使用mysql数据库的话
需要开启mysql binlog
6)目录配置
bin目录:是Streamset DC运行脚本目录
etc目录:是Streamset DC默认的配置文件目录,包括系统配置、权限配置、邮件配置、日志配置等;
data目录:是Streamset DC默认的数据目录,用于存储你设计的数据流等;
log目录:是Streamset DC默认的日志目录,包括GC日志和系统日志;
libexec目录:是Streamset DC默认的运行时环境配置目录
streamsets-libs目录:是Streamset DC默认的系统自带组件的目录
user-libs目录:是Streamset DC放置用户自定义开发组件的目录
edge-binaries目录:是Streamset DC存放Streamsets DC Edge的各种类型的安装包。
本科计算机bi-ye-she-ji辅导,远程安装运行+部署,欢迎各位小伙伴打扰~企鹅号:298-150-5753















 1428
1428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









