









MySQL索引
简介
官方定义:一种帮助mysql提高查询效率的数据结构
优点
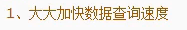
缺点

索引的分类

主键索引
主键索引在建表时自动创建,无需手动创建
查看索引语法
show index from [表名];
普通索引
普通索引创建有两种方式:建表时创建、建表后创建
建表时创建
create table t_user(id varchar(20) primary key,name varchar(20),key(name))
建表后创建
create index [索引名] on [表名]([列名]);
删除索引
drop index [索引名] on [表名];
唯一索引
建表时创建
create table t_user(id varchar(20) primary key,name varchar(20),unique(name));
建表后创建
create unique index [索引名] on [表名]([列名]);
复合索引
建表时创建
create table t_user(id varchar(20) primary key,name varchar(20), age int,key(name,age));
建表后创建
create index [索引名] on [表名]([列名],[列名]);
最左前缀原则
- 最左前缀原则,
- mysql在查询过程中为了更好的利用索引,会自当将搜索语句进行排序,以便符合最左前缀原则

索引底层——B+树
mysql的数据底层使用链表的形式排列,其中一个叶子节点存储了【键值】、【数据】和【指针】,每个指针又指向下一个节点的键值。
PS:这也就决定了MYSQL中进行索引的前提是**【排序】**,这也就造成了索引的缺点,即会影响增删改时的效率。

此时,以默认16kb的大小将数据进行分页,每页的第一条数据抽取出其键值和指针,组成页目录。页目录的基础上还可以再抽取出上一层的页目录,一个三层的B+树大概可以维护10亿条数据
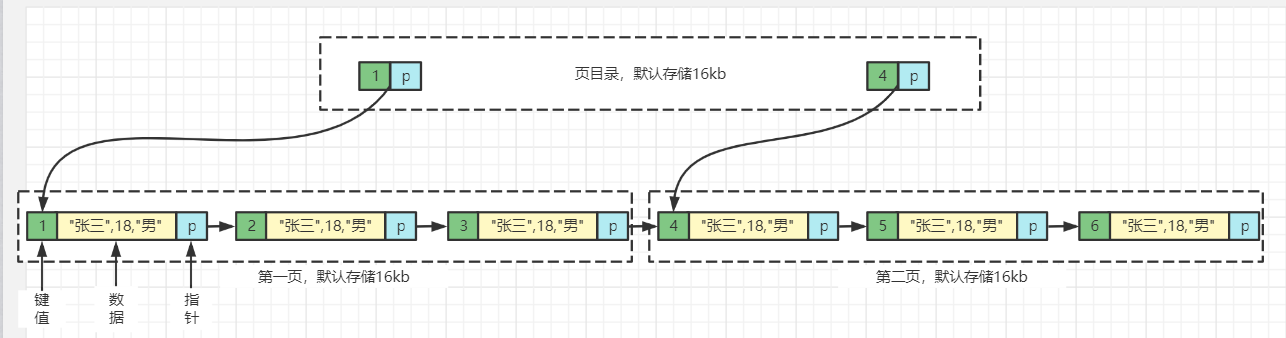
B+树相比于B树的不同点
- B树的非叶子节点只存储键值信息
- 所有叶子节点之间都有一个链指针
- 数据记录都存放于叶子节点中
**PS:**这也就是为什么在MYSQL中建议使用自增列做主键,使用自增列(INT/BIGINT)做主键,这时候写入顺序是自增的,和B+树叶子节点分裂顺序一致。
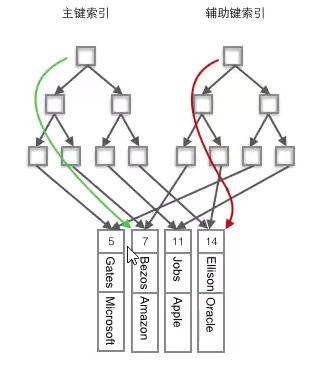
聚簇索引与非聚簇索引
- 聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据
- 非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
InnoDB引擎

非聚簇索引:
- 第一步在非聚簇索引B+树中检索对应值,获取其主键
- 第二步在聚簇索引B+树中检索其主键,获得最后的数据值
问:为什么非聚簇索引不直接存储数据地址?
因为当我们对数据进行修改时,也需要对索引进行相应的变动,我们只针对聚簇索引做变动,因此宁愿进行二次查找,也不会在非聚簇索引存储数据地址


MYISAM引擎

详细分析:https://www.jianshu.com/p/fa8192853184
[外链图片转存中…(img-qmwu4T0D-1647242684683)]
[外链图片转存中…(img-vixJ4i5L-1647242684683)]
详细分析:https://www.jianshu.com/p/fa8192853184
本科计算机bi-ye-she-ji辅导,远程安装运行+部署,欢迎各位小伙伴打扰~企鹅号:298-150-5753















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









