







在IDEA中使用JavaAPI对Hadoop进行操作
简介
在本期博客中,笔者会详细的介绍自己通过IDEA开发工具使用Java API接口对Hadoop的HDFS文件系统进行操作,其中包括安装Hadoop在Windows的环境配置,以及通过IDEA创建Maven项目并配置相关文件。
一、 Java API相关的简单介绍
功能描述
通过Java API我们可以在Windows系统中编写Java程序来对HDFS文件系统进行操作。
Hadoop官方的Hadoop API文档,可以访问如下网站,查看各个API的功能:
Overview (Apache Hadoop Main 3.3.1 API)
在这里简单介绍一些基础知识。
Hadoop中关于文件操作类基本上全部是在“org.apache.hadoop.fs”包中,这些API能够支持的操作包含:打开文件,读写文件,删除文件等。
在这说明一下文件在 Hadoop 中表示一个Path对象,通常封装一个URI。如HDFS上有个test文件,则URI表示成hdfs://master:9000/test。
首先,介绍Hadoop中的Configuration类,该类的对象封装了客户端或者服务器的配置,每次开始一个对hdfs进行操作的Java程序都要进行的一步,就是创建配置文件。
例:Configuration conf= new Configuration()
接下来是Hadoop中最终面向用户提供的接口类FileSystem,该类的对象是文件系统对象,是个抽象类,只能通过类的 get 方法得到具体的类,可以用该对象的一些方法来对文件进行操作。
例:FileSystem fs = FileSystem.get(conf)
综上所述,我们可以得到一个操作文件的程序框架:
operator()
{
得到Configuration对象
得到FileSystem对象
进行文件操作
}
文件操作:
1. 上传文件
通过 “fs.copyFromLocalFile(Path src,Path dst)” 可将本地文件上传到HDFS指定的位置上,其中 src 和 dst 均为文件完整路径,但src是本地文件的路径,dst是在hdfs中存放文件的路径。
例:
fs.copyFromLocalFile(new Path("C:\\app\\2.txt"),new Path("/test3"));
2. 新建文件
通过 “fs.mkdirs(Path f)”可在 HDFS 上创建文件,其中 f为文件的完整路径。
例:
fs.mkdirs(new Path("/test3"));
3. 下载文件
通过“fs.copyToLocalFile(Path src, Path dst)”可在hdfs中下载文件。其中 src 为HDFS上的文件, dst为要下载到本地的文件名.
例:
fs. copyToLocalFile(new Path("/hdfsfile"),new Path("C:\\app"));
4. 删除文件
通过“ fs.delete(Path path, Boolean b)”可删除hdfs文件,其中 path 为要删除的文件。
例:
fs.delete(new Path("/test"),true);
5. 新建文件并写入数据
通过 “FileSystem.create(Path f, Boolean b)” 可在 HDFS 上创建文件,其中 f 为文件的完整路径, b 为判断是否覆盖。
例:
Path dfs = new Path("/test2/hdfsfile");
//创建新文件,如果有则覆盖(true)
FSDataOutputStream create = fs.create(dfs, true);
//向新创建的文件中写入数据
create.writeBytes("Hello,HDFS!");
注意:
由于hdfs不支持并发写入,所以每次操作完都要关闭文件系统对象。
例: fs.close();
相关链接:
Hadoop API 使用介绍_learn_tech的博客-CSDN博客
hadoop java API 使用 - 简书 (jianshu.com)
HDFS 中 Java API 的使用 - 简书 (jianshu.com)
二、 操作步骤
第一步:Windows环境下Hadoop环境变量配置
参考链接:
在Windows中安装Hadoop(非虚拟机安装)_Niclas的博客-CSDN博客
winutils/hadoop-2.6.5/bin at master · cdarlint/winutils · GitHub
Windows平台下载安装Hadoop_剁椒鱼不要头的博客-CSDN博客_hadoop平台下载
说明:以上连接用来参考如何修改Hadoop的bin文件,不是要求在Windows中安装虚拟机,因为笔者的Hadoop是2.6.5的所以只把2.6.5的版本放在上面,要是读者需要其他版本的,请自行百度选择需要替换的Hadoop版本对应的bin目录。
补充小知识:winutils.exe是模拟Linux环境,如果缺少这个程序,会报空指针异常。
当你替换完之后,可在自己的hadoop文件夹的bin目录下面看到多了很多东西,如下图所示

接下来就是去此电脑->高级系统设置->环境变量->系统变量中进行设置,详情请看上面开始的链接,和兄弟萌配置jdk环境变量的操作类似。
最后怎么看成功了呢???请看下图:
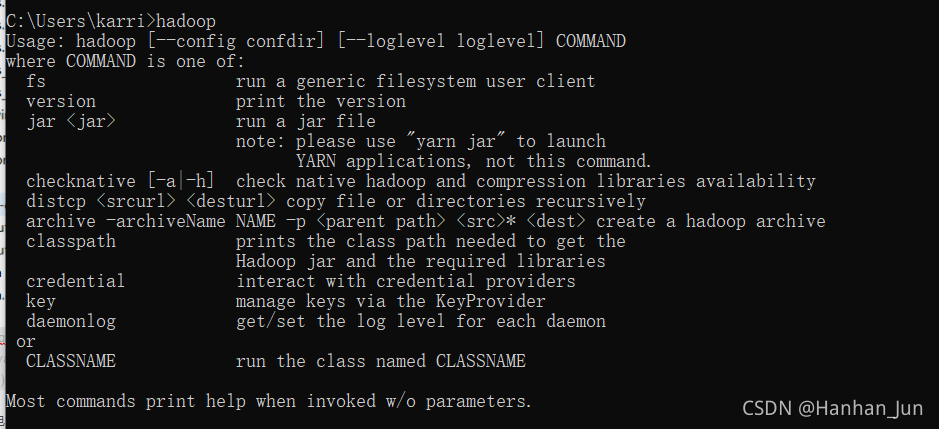
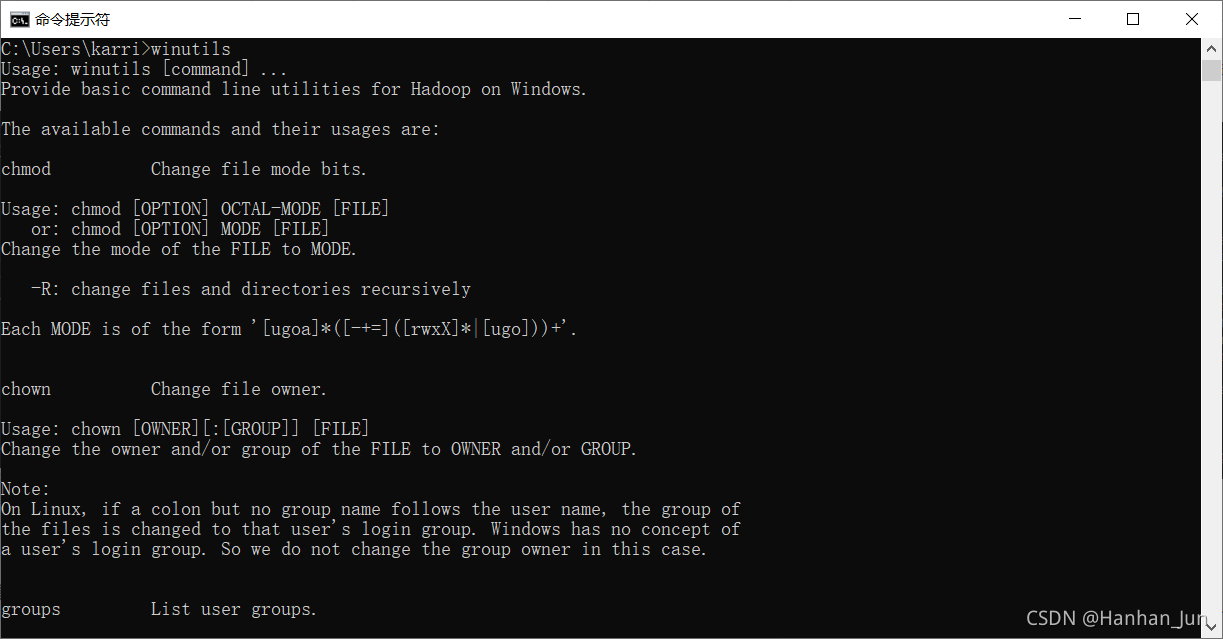
输入hadoop 以及 winutils 不报错就完成了第一步Hadoop的环境配置。
第二步:Windows和Linux中的JDK版本要一致
链接:
官方JDK版本列表下载
就好比我自己的JDK在Linux中的版本是8u151,是1.8的,我就将自己原来Windows的JDK删了再弄了一个1.8的版本安装。

如果在第一步中hadoop -version命令出jdk的错,十有八九就是Windows的jdk路径有问题,需要打开Hadoop文件夹etc目录中的hadoop-env.cmd文件,把自己的路径修改,如图所示:
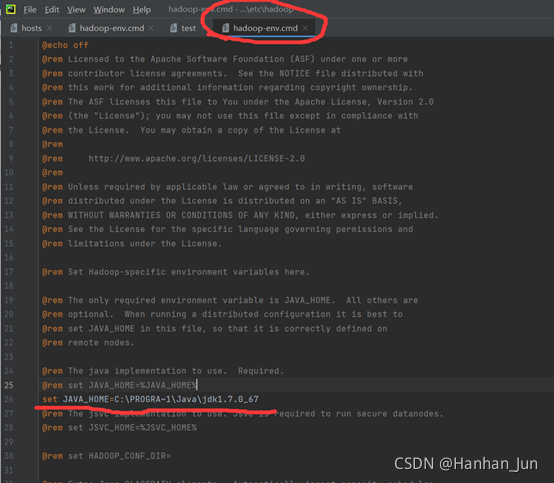
中间的PROGRA~1是program file的缩写,可以避免一些路径空格的问题。
第三步、创建一个Maven项目
参考链接:
maven安装和配置阿里云镜像(各种详细配置) - Yan_Yang - 博客园 (cnblogs.com)
在官网下载apache的maven包,链接如下:
Maven官网下载
在下载完之后,有两个小步骤:1.修改镜像地址 2.修改本地仓库地址
配置maven国内镜像:(远程仓库)
1、在不配置镜像的情况下,maven默认会使用中央库.
2、maven中央库在国外,访问会很慢,甚至有时候会出现无法下载的情况.
3、为了解决依赖下载速度的问题,需要配置maven国内镜像
镜像:如果仓库X可以提供仓库Y存储的所有内容,那么就可以认为X是Y的一个镜像。
换句话说,任何一个可以从仓库Y获得的构件,都能够从它的镜像中获取。
本地仓库是远程仓库的一个缓冲和子集,存储所有项目的依赖关系,构建Maven项目的时候,首先会从本地仓库查找资源,如果没有,Maven会从远程仓库下载到本地仓库,在下次使用时就不需要从远程下载。
Maven默认的本地仓库路径为${user.home}/.m2/repository,如C:/Users/admin/.m2/repository。
项目较多时,会占用过多C盘资源,因此可以自定义本地资源库。
使用仓库配置的优先级顺序:pom.xml>用户级别>全局级别。
补充说明:setting.xml主要用于配置maven的运行环境等一系列通用的属性,是全局级别的配置文件;而pom.xml(下面会出现)主要描述了项目的maven坐标,依赖关系,开发者需要遵循的规则,缺陷管理系统,组织和licenses,以及其他所有的项目相关因素,是项目级别的配置文件。
接下来就是操作步骤:
1.找到maven安装目录conf文件夹下的settings.xml文件进行修改,在原settings文件中的"mirrors"标签中
<!--阿里云镜像-->
<mirrors>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
2. 同一个settings.xml文件中找到下面这行修改即可(这只是为了改变下载路径,自己自定义就行)
<localRepository>此处修改</localRepository>
如图所示:
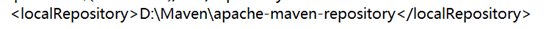
3.开始创建
打开idea,file新建一个project,选择左边的Maven,如图所示:
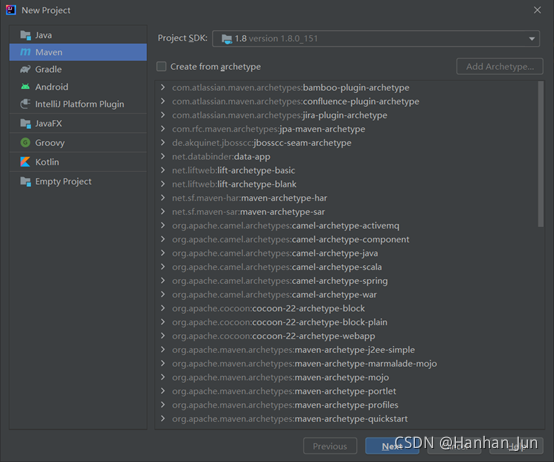
注意!!! JDK一定要选和自己版本对应的
一直Next就好了,新建好之后,接下来就是配置maven,打开File->Settings,搜索Maven,点击之后,看右边,如图所示:
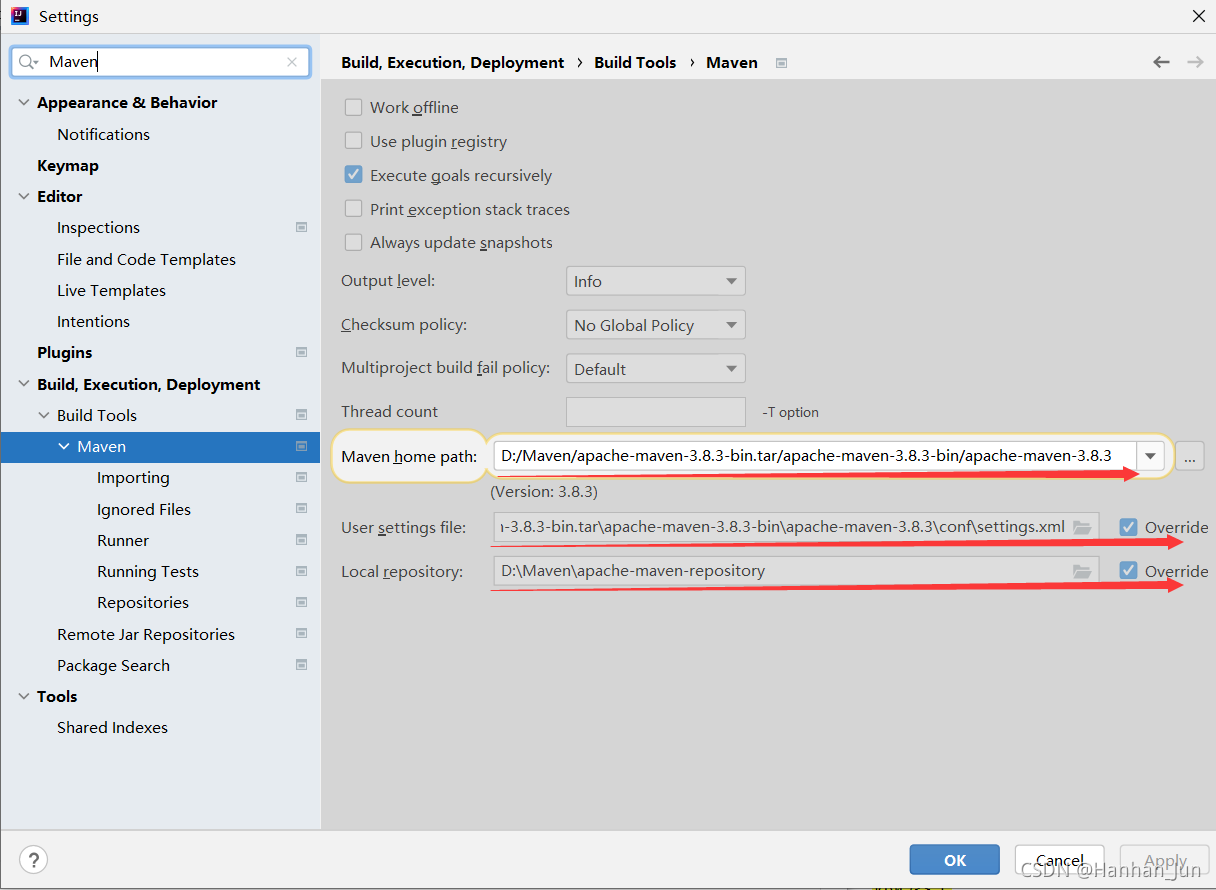
修改上图三个红线所在的地方。
第一个修改Maven home path,找到你存放下载好的Maven包就可(不需要是bin目录);
第二个修改User settings file,点击override,选择在上面步骤修改的settings.xml文件所在路径即可;
第三个修改Local repository,这是本地仓库地址,在上面步骤有过自定义路径,同样点击override,把自己自定义的本地仓库路径选上即可。
以上操作完成之后,会看到IDEA的界面会出现一个pom.xml文件(如果没有在左边的导航栏自行寻找),往其中添加以下内容:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.5</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
上面内容添加的是各种依赖包
关于pom.xml文件中各个依赖包的介绍
- Junit:Junit是测试工具包,功能非常强大,无需把方法放入main函数中直接测试,就如示例代码中的@Test和@Before、@After等。
- commons-logging:是apache最早提供的日志的门面接口。提供简单的日志实现以及日志解耦功能。使用commons-logging能够灵活的选择使用那些日志方式,而且不需要修改源代码。
- log4j:Log4j是Java的一个日志工具,是Apache的一个开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件,甚至是套接口服务器、NT的事件记录器、UNIX Syslog守护进程等;我们也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。最令人感兴趣的就是,这些可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。
接下来就是在idea左边的src/main/sources目录下,新建一个文件,命名为log4j.properties
往其中添加以下内容:
hadoop.root.logger=DEBUG, console
log4j.rootLogger=INFO,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
一切顺利进行下来,接下来就进入测试代码环节。打开自己的虚拟机并且启动集群!!!
三、代码测试
先建一个Java Class文件,先测试一下能不能连接自己的master:
package test.Hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import java.io.IOException;
public class Demo01 {
public static void main(String[] args) throws IOException {
//1.创建配置文件
//封装了客户端或者服务器的配置
Configuration conf= new Configuration();
//在之前Linux系统中配置Hadoop时的core—site.xml文件中,有相关默认设置,用来指定我们要操作的文件系统hdfs
conf.set("fs.defaultFS","hdfs://192.168.30.140:8020");
//指定用户名root
//System.setProperty("HaDOOP_USER_NAME","root");
//2.获取文件系统对象
FileSystem fs = FileSystem.get(conf);
System.out.println(fs.toString());
}
}
有相应的输出:

接下来就是文件操作:
package test.Hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
public class Demo03 {
private FileSystem fs;
@Before
public void before() throws IOException,InterruptedException{
System.setProperty("hadoop.home.dir", "D:\\windowsHadoop\\hadoop-2.6.5");
Configuration conf = new Configuration();
fs = FileSystem.get(URI.create("hdfs://192.168.30.140:8020"),conf,"root");
//测试
System.out.println("执行了before");
}
//创建
@Test
public void mk() throws IOException {
fs.mkdirs(new Path("/test3"));
}
//上传
@Test
public void put() throws IOException {
fs.copyFromLocalFile(new Path("C:\\app\\2.txt"),new Path("/test3"));
}
//重命名
@Test
public void rename() throws IOException {
fs.rename(new Path("/test3"),new Path("/test4"));
}
//下载
@Test
public void get() throws IOException {
fs. copyToLocalFile(new Path("/hdfsfile"),new Path("C:\\app"));
}
//删除
@Test
public void delete() throws IOException{
fs.delete(new Path("/test"),true);
}
//新建文件并写入数据
//通过 "FileSystem.create(Path f, Boolean b)" 可在 HDFS 上创建文件,
// 其中 f 为文件的完整路径, b 为判断是否覆盖。
@Test
public void write() throws IOException{
//定义新文件
Path dfs = new Path("/test2/hdfsfile");
//创建新文件,如果有则覆盖(true)
FSDataOutputStream create = fs.create(dfs, true);
//向新创建的文件中写入数据
create.writeBytes("Hello,HDFS!");
}
@After
public void after() throws IOException{
System.out.println("执行了after");
fs.close();
}
}
代码说明:
- before是每运行一个方法都会执行的函数(@Before),after也一样,before()是连接虚拟机,而after()是每次操作结束之后自动关闭(这么写代码只是为了测试,这就用到了我们的依赖包junit)。
- 代码会有许多异常,直接抛出即可。
- 运行不是直接run,是点击左侧的绿标运行。
- 需要在before()中修改成自己的IP地址。
- 要是下载的操作有问题,需要在hadoop所在文件夹的bin目录中找到hadoop.dll文件,将其拷贝到Windows文件系统的C:\Windows\System32所在目录中。
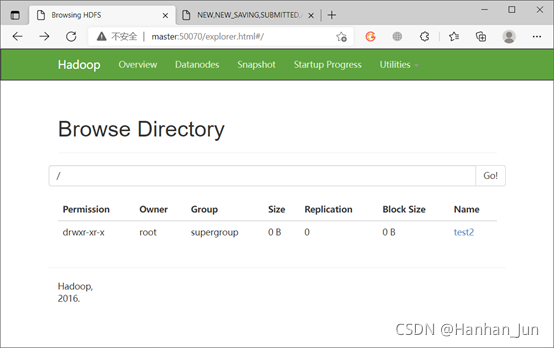
怎么看结果呢??一方面我们看在idea的输出,另外一方面我们可以打开master:50070,查看相应结果:
四、总结
以上操作过程只要兄弟萌细心耐心,就可以完成,如果以上步骤有错误或不妥之处,还请多多指教。














 5470
5470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









