







爬虫实战—动态网页内部加载
动态网页的爬取和静态网页的爬取不一样,静态网页我们想要的资料都可以在HTML源码的页面找到,但是在动态页面中就找不到了(动态网页的内部加载可以)。下面的复现的例子是动态网页的内部加载:
复现爬虫漫画
目标漫画网站:请点击这里:动漫之家
目标漫画:请点击这里:妖神记
思路
- 找到所有漫画章节的url
- 找到所有章节漫画内容
- 保存漫画
所有章节的标题和URL
- 找到目标漫画后往下拉就可看到漫画的章节标题列表:

- F12>元素>选择页面一个元素检查就可以定位到章节列表了:

- 提取目录和目录URL
目录所在位置:

# 要引入的库:
import os
import re
import time
import requests
from bs4 import BeautifulSoup
listurl = 'https://www.dmzj.com/info/yaoshenji.html' # 目标URL
req = requests.get(url=listurl) # 获取对应网页
req.encoding = req.apparent_encoding # 解决乱码问题
html = BeautifulSoup(req.text, features='lxml')
html = html.find_all('ul', class_='list_con_li autoHeight') # 由上图可知,目录在一个ul,calss=list_con_li autoHeight里
# print(html)
a_bf = BeautifulSoup(str(html), features='lxml')
a = a_bf.find_all('a') # ul里还有一个<a href……></a>,进一步筛选
names = [] # 初始化目录列表
urls = [] # 初始化目录URL列表
for net in a[253:]: # 前253个目录和后面的重复
names.append(net.text) # 保存文字目录
urls.append(net.get('href')) # 保存目录URL
代码效果:


找到所有章节漫画内容
- 随便点一个章节,F12查看网页源码。检查页面元素后发现漫画图片的URL。

但是,如果按照静态网页的思维,这章节的漫画图片都应该在这里,但是刚才我们在“元素”的网页源码有看到漫画图片的链接,当我们在pycharm获取网页源码后发现,返回的网页源码并没有我们想要的漫画图片链接(见下图运行结果),还是因为图片是动态加载的,所以我们在网页源码时找不到想要的。
# 随机找一章漫画看是否返回漫画图片链接
import requests
from bs4 import BeautifulSoup
listurl = 'https://www.dmzj.com/info/yaoshenji.html'
req = requests.get(url=listurl)
req.encoding = req.apparent_encoding
html = BeautifulSoup(req.text, features='lxml')
html = html.find_all('ul', class_='list_con_li autoHeight')
# print(html)
a_bf = BeautifulSoup(str(html), features='lxml')
a = a_bf.find_all('a')
names = []
urls = []
for net in a[253:]:
names.append(net.text)
urls.append(net.get('href'))
headers ={
'Referer': 'https://www.dmzj.com/view/yaoshenji/41919.html'
}
picreq = requests.get(url=urls[1], headers=headers)
req.encoding = req.apparent_encoding
print(picreq.text)

但是,因为这个网站的漫画时动态内部加载的,所以肯定通过某种规则来生成图片链接(写出来的代码肯定有规律的),那么我们开始吧!
- 寻找漫画图片链接的规律
以第二章第一张图片为例,选择复制链接,去掉前后,留下这么一串数字:

CTRL+F搜索,有三处定位:
第一处定位:

第二处定位:

第三处定位:
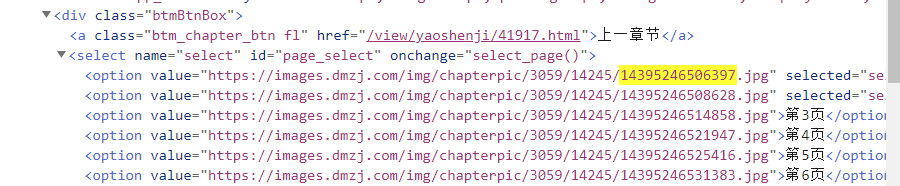
然后在pycharm返回的网页源码中也CTRL+F搜索发现,只有第一处定位是重合出现的,那么真相只有一个!就是它~规律就出来了:
import requests
from bs4 import BeautifulSoup
import re
url = 'https://www.dmzj.com/view/yaoshenji/41917.html'
r = requests.get(url=url)
html = BeautifulSoup(r.text, 'lxml')
script_info = html.script
pics = re.findall('\d{13,14}', str(script_info)) # 正则
chapterpic_hou = re.findall('\|(\d{5})\|', str(script_info))[0] # 正则表达式,始终是逃不掉……
chapterpic_qian = re.findall('\|(\d{4})\|', str(script_info))[0] # 正则
for pic in pics:
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic + '.jpg' # 合成URL
print(url)
代码运行结果:

保存漫画
找到漫画的所有图片后,就要按章节来保存漫画:
组合代码:
import os
import re
import time
import requests
from bs4 import BeautifulSoup
# 获取漫画目录
listurl = 'https://www.dmzj.com/info/yaoshenji.html'
req = requests.get(url=listurl)
req.encoding = req.apparent_encoding
html = BeautifulSoup(req.text, features='lxml')
html = html.find_all('ul', class_='list_con_li autoHeight')
# print(html)
a_bf = BeautifulSoup(str(html), features='lxml')
a = a_bf.find_all('a')
names = []
urls = []
for net in a[253:]:
names.append(net.text)
urls.append(net.get('href'))
# 获取每章的漫画
i = 0
headers = {
'Referer': 'https://www.dmzj.com/view/yaoshenji/41919.html'
}
for url in urls:
headers = {
'Referer': url
}
filename = names[i]
i += 1
os.mkdir(filename) # 创建每一章节的文件夹
req = requests.get(url=url)
req.encoding = req.apparent_encoding
html = BeautifulSoup(req.text, features='lxml')
# html = html.script
pics = re.findall(r'\d{13,14}', str(html))
chapterpic_hou = re.findall(r'\|(\d{5})\|', str(html))[0] # 输出是这样子的:['14237', '41917'],[0]的作用是选择列表第一个元素14237
chapterpic_qian = re.findall(r'\|(\d{4})\|', str(html))[0]
for pic in pics:
if pic[-1] == '0': # 这一段代码是排序用的,因为爬取的网址不是按照漫画顺序的,需要调整,末尾补0比较大小。
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic[:-1] + '.jpg'
picturename = pic[:-1] + '.jpg'
else:
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic + '.jpg'
picturename = pic + '.jpg'
dirname = filename + '/' + picturename # 路径
# print(url)
data = requests.get(url=url, headers=headers).content
# print(data)
with open(dirname, 'wb') as f: # 保存图片
f.write(data)
print('.')
time.sleep(10)
运行结果:

没有开异步,会慢很多。
原文链接:请点击这里














 3622
3622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









