







漫画抓取:python网络爬虫与html对应结合抓取讲解

前言
本次以漫画抓取为例,来一步一步结合浏览器后台与爬虫编程讲解,也可以延伸到应对其他不同的网页抓取
一、实现目的
首先说明一下本次抓取的网站:XKCD, 是一个流行的极客漫画网站。
首页url:http://xkcd.com/
但是其中的重点在于:它有一个“Prev”按钮,让用户导航到前面的漫画。
这就很关键了,直接影响到我们抓取漫画的连贯性,换句话说,我们下载完一个漫画之后,下面一个漫画的链接在同一个页面已经存在(整个系统沟通的重点所在)
实现:下载这些XKCD网上的漫画。
二、开始旅程
1.明确思路
- 得到起始的URL。
- 利用 requests 模块下载页面。
- 利用 Beautiful Soup 找到页面中漫画图像的 URL。
- 一起逐步分析html的结构
- 利用 iter_content()下载漫画图像,并保存到硬盘。
- 找到前一张漫画的链接 URL,然后可以重复操作。
2.下载网页
#下载漫画
#! python3
import requests,os,bs4
os.chdir(r'C:\Users\LX\Desktop')
url='http://xkcd.com/'+input('enter number')+'/'
#url='http://xkcd.com/'
os.makedirs('xkcd',exist_ok=True)
while not url.endswith('#'):
print('DownLoading page |%s...' %url)
res=requests.get(url)
res.raise_for_status()
soup=bs4.BeautifulSoup(res.text,features='html.parser')
不急,我们一步一步来看
第三行开始
3. 导入相应的库requests,os,bs4(应该没有问题哈)
4. 确定我的目录(我用的是桌面哈)
5. 确定url,为什么后面有input()?请看下图分析:
可以看到,目前这一幅漫画的url是 https://xkcd.com/1/,意味着我们输入的input(),会直接决定我们下载下来的漫画是哪一个,甚至还决定我们下载下来的漫画数量。
比如我输入1,那就定位了这个页面,以此类推
6. 如果用这个,会下载所有漫画,因为没有指定嘛,很好理解的哈(如果觉得有问题可以提出来,我们再细讲哈)
7. 创建文件夹,exist_ok=True,即便存在,也不会报错
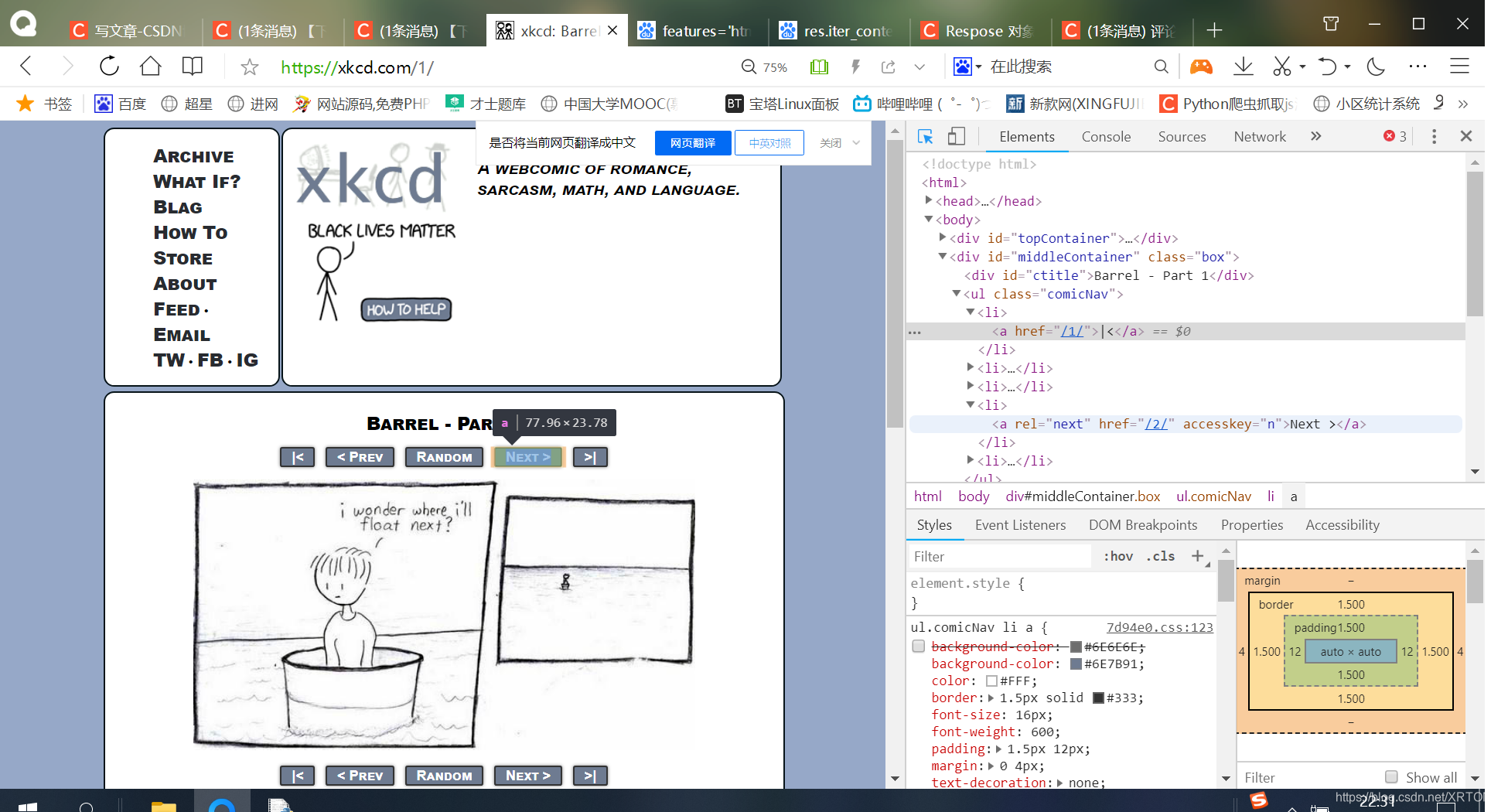
8. 当我点击了最后一幅漫画,我们的浏览器右侧的href属性会成为这样:(直接上图,每个网页都共通性,会这个,其他的也大差不差(不过也具体情况具体分析))
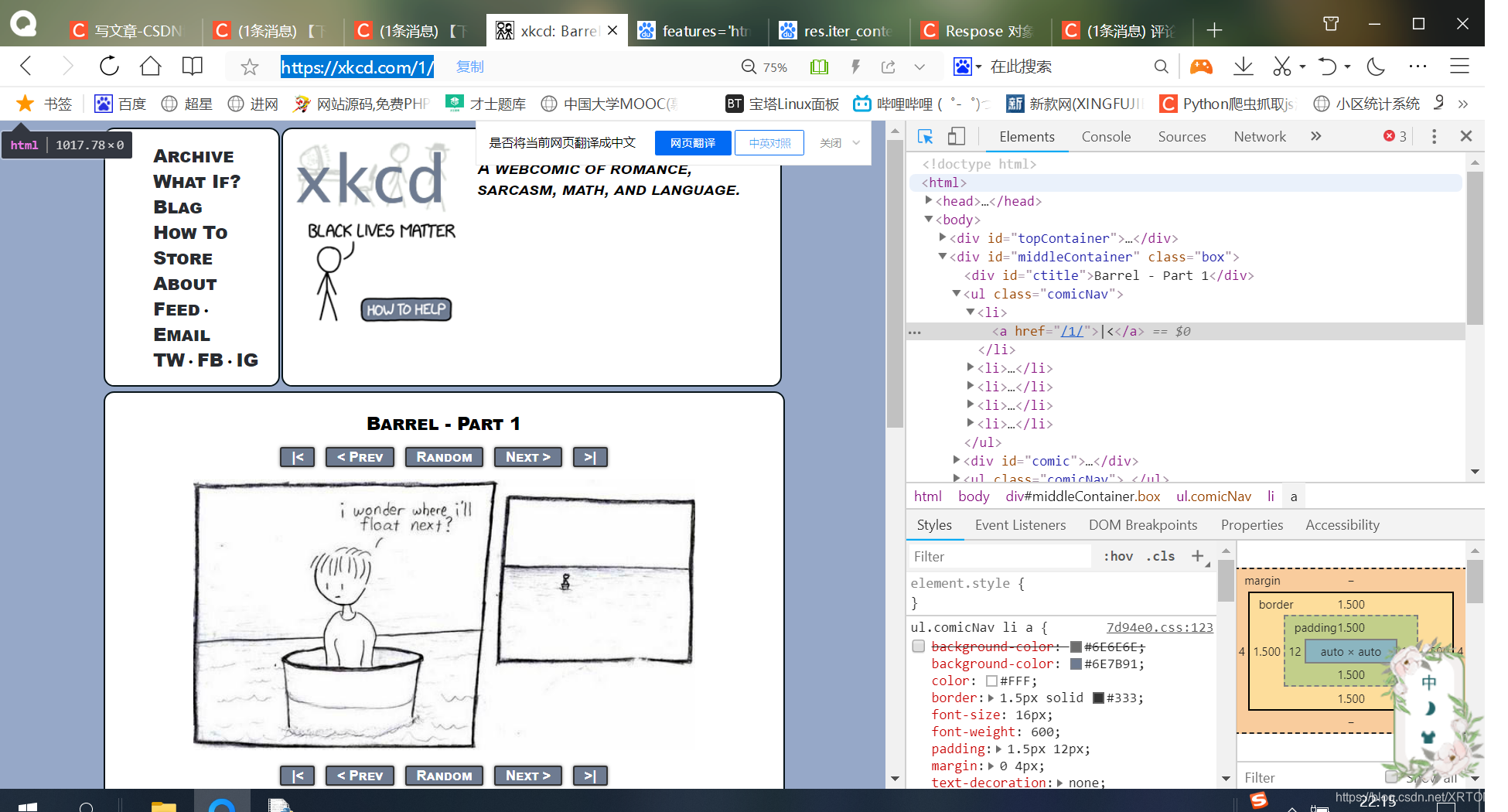
这是最后一张漫画的next按钮的href="#",这就是我们结束的关键,对比一下其他href,大家可能会更加明白html的布局和结构
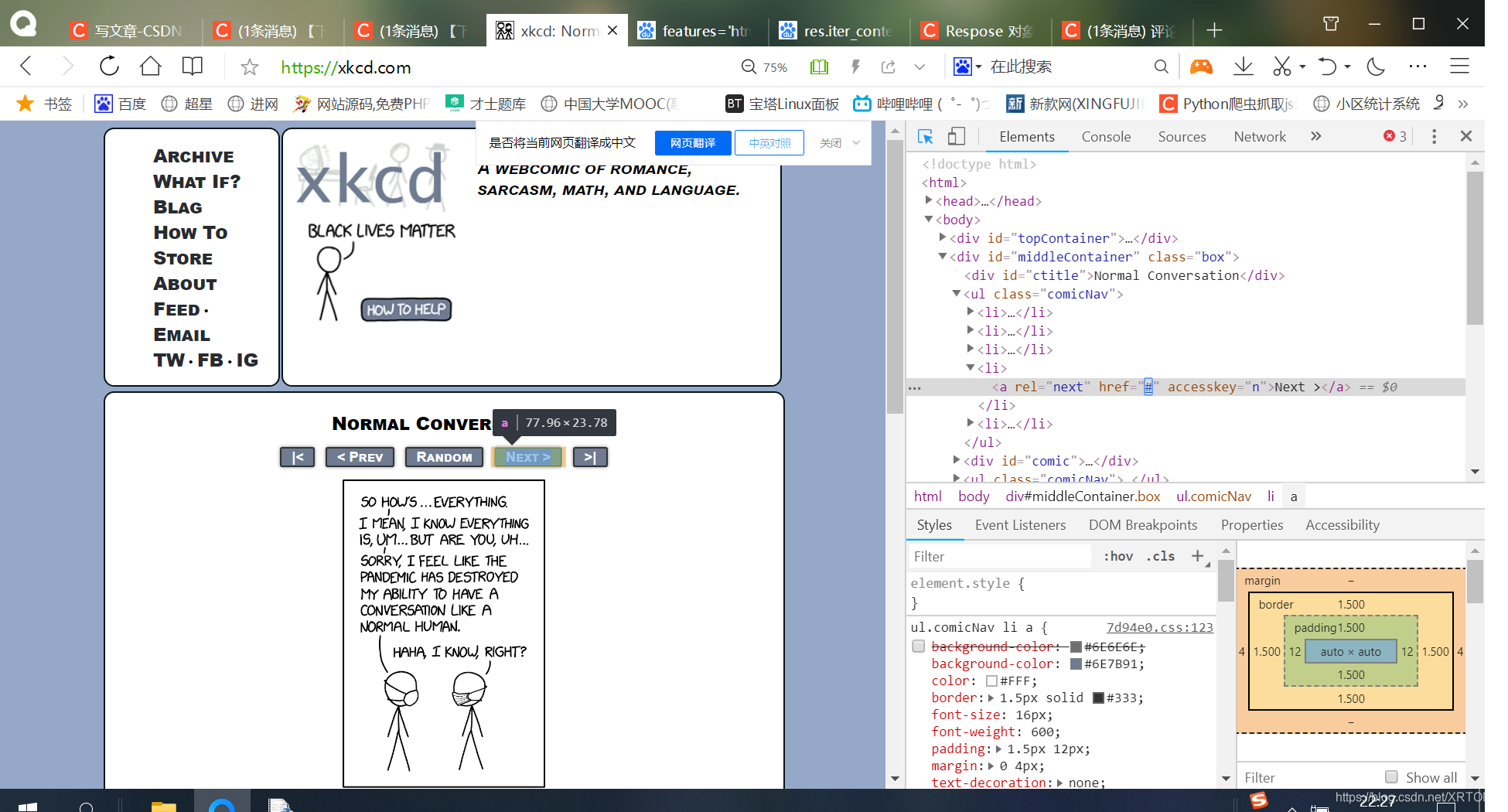
这是第一张next按钮的href图片:href="/2/"
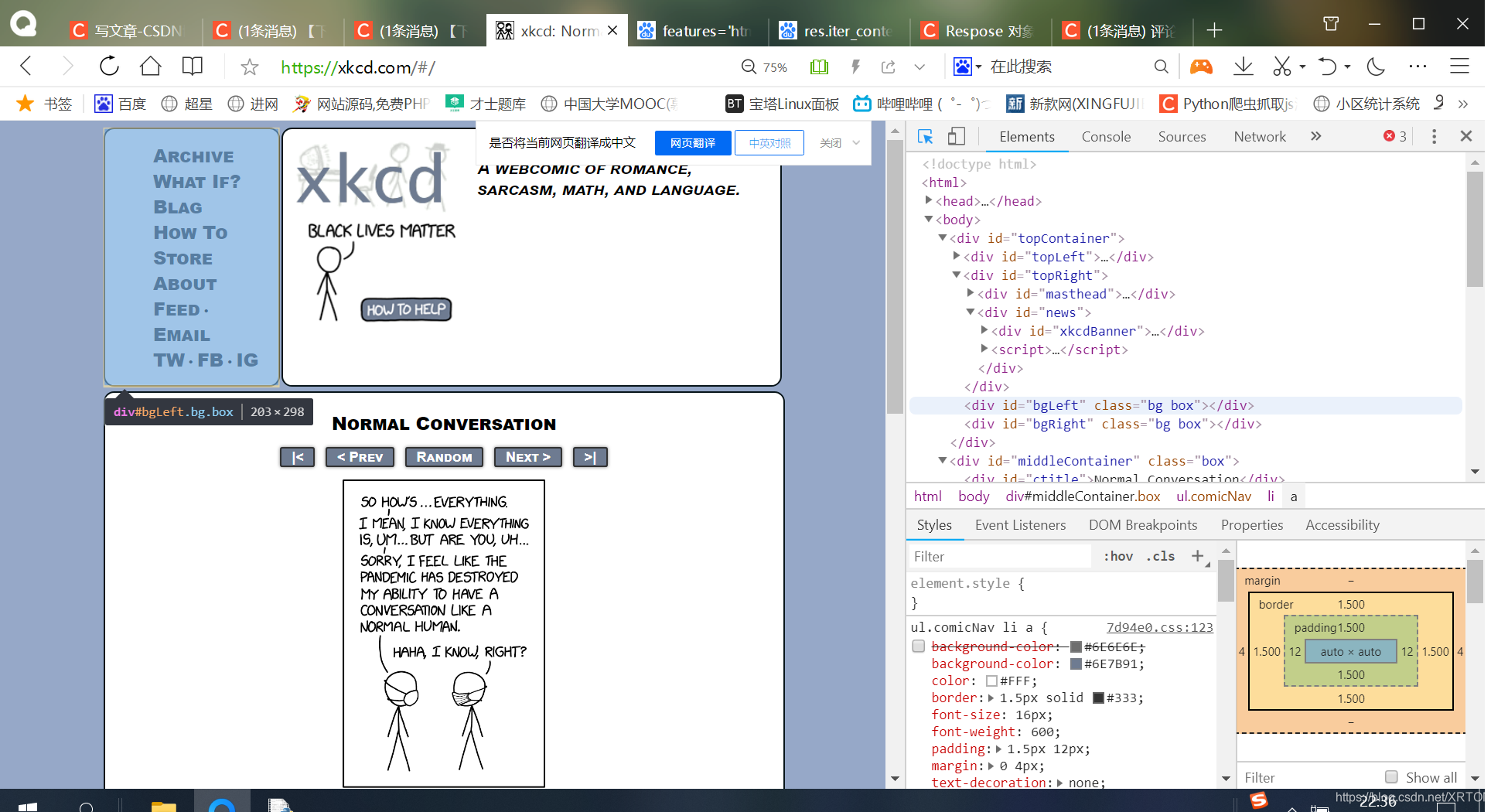
直接输入https://xkcd.com/#/试试。(可见就是最后一幅漫画)
当我们的https://xkcd.com/#/出现,那么意味着是最后一幅漫画
相信大家应该可以明白这个标志的重要性!
9. 第九行print(‘DownLoading page |%s…’ %url) 输出一下
10. 开始用requests库get(url),返回response对象,因为后面要用到response对象嘛,创建一个,无可厚非哈
11.调用response对象的方法,检验一下连接是否成功,会不会报错,尽早发现问题
12.调用bs4,创建一个BeatuifulSoup对象,等待后面用,features='html.parser 1'在确定我们的解释器,非常必要。(html.parser在注脚解释)【features='lxml’也可以,我用的比较多,不拘泥,这里不赘述了】
这一部分的解释结束了,也不知道我解释的是否清楚,我们继续分析。
3.寻找下载漫画
--snip--
comicElem=soup.select('#comic img')
if comicElem==[]:
print('Could not find comic image.')
else:
comicUrl='http:'+comicElem[0].get('src')
print('DownLoading imgae|%s...' %(comicUrl))
res=requests.get(comicUrl)
res.raise_for_status()
imageFile=open(os.path.join('xkcd',os.path.basename(comicUrl)),'wb')
for chunk in res.iter_content(100000):
imageFile.write(chunk)
imageFile.close()
prevLink=soup.select('a[rel="prev"]')[0]
url='http://xkcd.com'+prevLink.get('href')
print('Done.')
从第二行开始分析
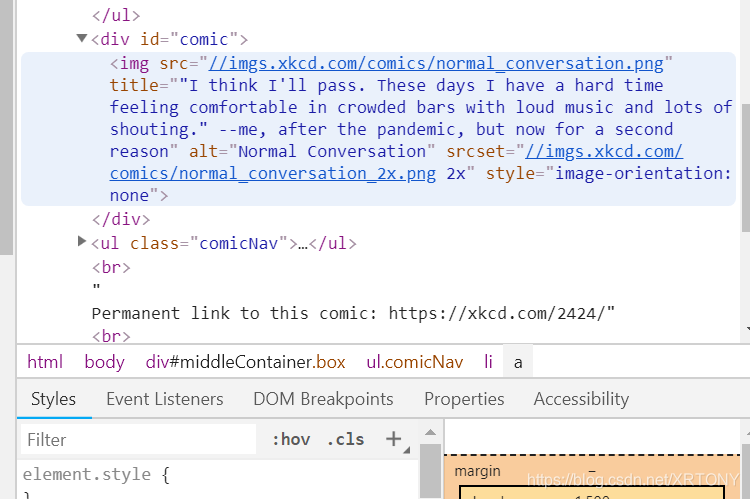
2. 首先明确,为什么出现#comic img?我们来看一下这张图片:
总览图
细节图
不急,我们来慢慢分析,以后的网页都可以这样分析处理。首先看这里:
当光标移动到这里,我们看控制台显示:
开始分析,这个图片,在一个< div>标签里面,表明这里是一个分区,换句话说,就是和其他部分分开了,看这个html的布局也可以看出来。
其次,重点在于,这个< div>的id=“comic”,并且图像处于标签< img>中,属性标签设置知道了,我就可以在select里面,用选择器来选择‘#comic img’,对图片,也就是我们要在这个页面抓取的信息进行非常精确的定位。(其他同理,以此类推)
3.4. 第三、四行就是在没有抓取到信息时,在程序中作出相应的回应,提高程序的健壮性。(这里就不赘述了哈)
5. else: 也就是,我们的comicElem接收到了返回值的时候,开始应对!
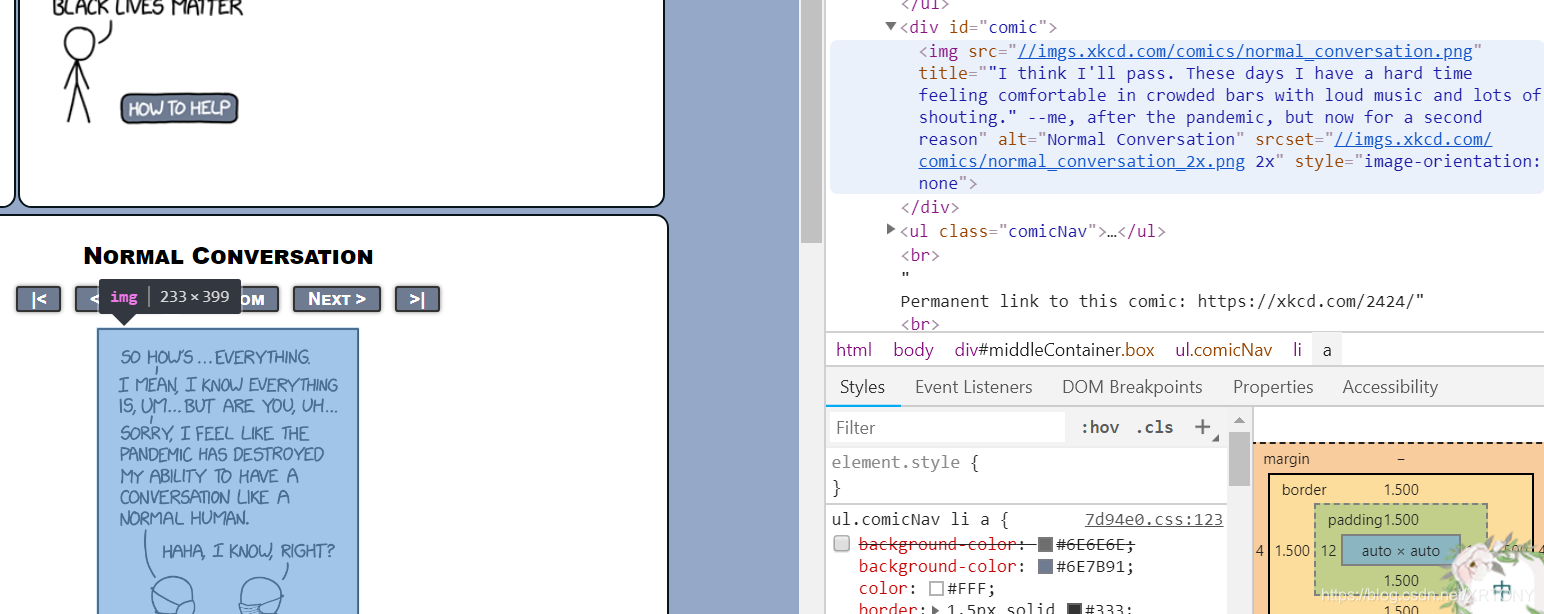
6. 我们来看看comicElem里面有什么?或许可以加深大家的理解:(上图)
我改了一下代码,可以看到,这个列表里面只有一个元素。那就是关于< img>的网页信息
参考一下原网页代码:(看看是不是?蓝色部分)
好,我们继续,现在对比三个(上图)
可以看到comicElem[0].get(‘src’),提取了src的字符串,用于下一步的赋值。
换句话说,这里的print(type(comicElem))显示为<class ‘bs4.element.ResultSet’>,你可以根据自己的需要,筛选你想要抓取的元素,以此应对各种复杂的网页抓取,能够这样分析,相信会解决很多难以处理的网络抓取。(print(comicElem[0].get(‘alt’)) 得到了Barrel - Part 1,确实正确,也表明思路正确)
7. 输出信息
8.9. res=requests.get(comicUrl)【特别注意一下,comicUrl需要加一个‘http’头,通过网页html代码和IDLE返回值,清晰可见,comicUrl里面没有‘http’头】
res.raise_for_status() #检查连接
10.11.12.13. imageFile=open(os.path.join(‘xkcd’,os.path.basename(comicUrl)),‘wb’)
把下载的文件开始准备写入文件夹(先打开)
for chunk in res.iter_content(100000):
imageFile.write(chunk)
imageFile.close()
关闭文件
14.因为我们下载好一个,需要去下载上一张图片,所以关键在于,我们的当前图片中,存在着上一个图片的信息:(上图分析)
我们可以看到,用选择器来说选择< a>标签中,rel属性为"prev"的部分,利用这个< a>元素的href属性去取得前一张图片的URL
15. url=‘http://xkcd.com’+prevLink.get(‘href’)中,加上页头“http:”再连接prevLink.get(‘href’),并且继续循环,直到第一张图片的prev=‘#’,结束所有操作,也就是下载结束啦!
16. 结束所有操作,print(‘Done.’)







4.完整代码附上
#下载漫画
#! python3
import requests,os,bs4
os.chdir(r'C:\Users\LX\Desktop')
url='http://xkcd.com/'+input('enter number')+'/'
#url='http://xkcd.com/'
os.makedirs('xkcd',exist_ok=True)
while not url.endswith('#'):
print('DownLoading page |%s...' %url)
res=requests.get(url)
res.raise_for_status()
soup=bs4.BeautifulSoup(res.text,features='html.parser')
comicElem=soup.select('#comic img')
if comicElem==[]:
print('Could not find comic image.')
else:
comicUrl='http:'+comicElem[0].get('src')
print('DownLoading imgae|%s...' %(comicUrl))
res=requests.get(comicUrl)
res.raise_for_status()
imageFile=open(os.path.join('xkcd',os.path.basename(comicUrl)),'wb')
for chunk in res.iter_content(100000):
imageFile.write(chunk)
imageFile.close()
prevLink=soup.select('a[rel="prev"]')[0]
url='http://xkcd.com'+prevLink.get('href')
print('Done.')

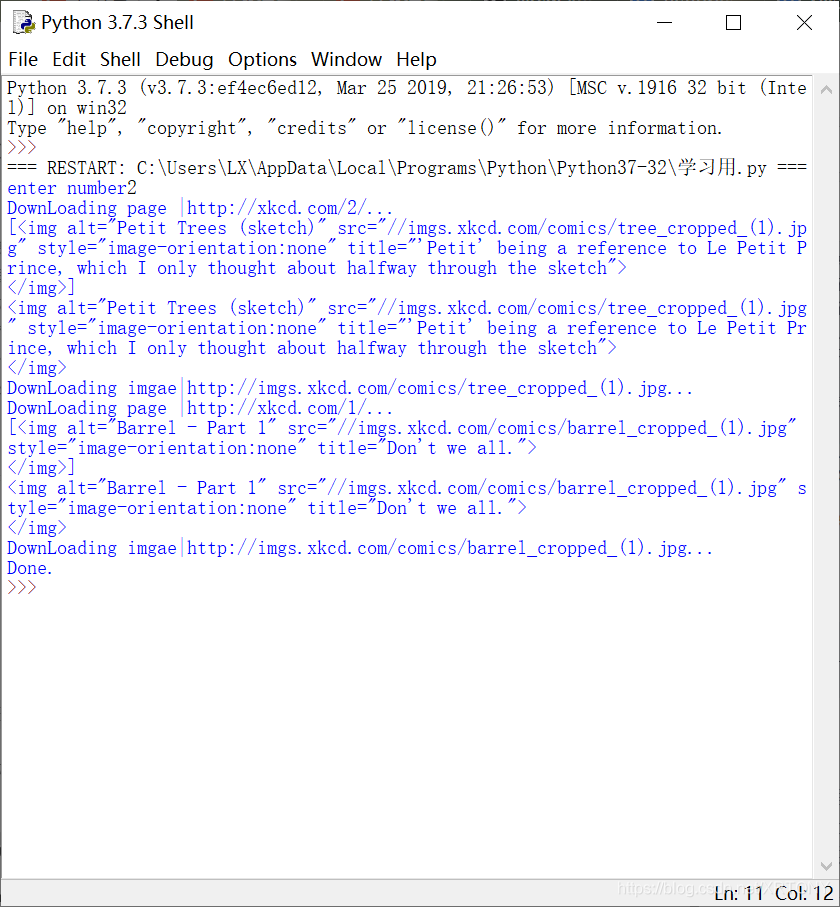
5.运行结果附上

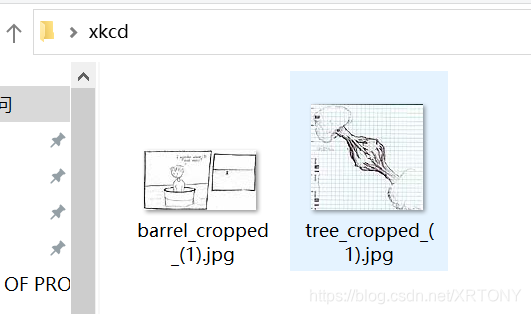
三、总结
这就是整个程序的过程分析!谢谢大家!
用心写了很久,希望可以帮到大家并且可以一起交流,真心感谢大家的支持!
htmlparser [1] 是一个纯的java写的html(标准通用标记语言下的一个应用)解析的库,它不依赖于其它的java库文件,主要用于改造或提取html。它能超高速解析html,而且不会出错。现在htmlparser最新版本为2.1。毫不夸张地说,htmlparser就是目前最好的html解析和分析的工具。无论你是想抓取网页数据还是改造html的内容,用了htmlparser绝对会忍不住称赞。
 ↩︎
↩︎















 825
825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











