






一、技术概述
1.这个技术是干什么用的?
过滤敏感词(骂人的话或政治之类的敏感词) ------敏感词过滤DFA算法模型
- 在项目中的匿名吐槽模块或者说匿名表达心理感想,难免会出现一些奇奇怪怪的敏感词违规,先用代码审核一部分比较明显的违规,剩下的内容就由软件的管理员于后台进行审核
- 聊天中发送的对话可能会有敏感词
2.学习这个技术的原因
自己写的方法太慢
1.将敏感词存放于(文件 或 数据库存储 或 redis)里面
2.在项目加载时,取出内容存放于全局静态 (hashMap 或 hashSet)对象
3.获取某段需要进行敏感词过滤的语句记为 str ,然后
外层循环利用迭代器遍历hashmap 或 hashSet 获取敏感词,
内层调用 str.find("敏感词") ,
如果存在敏感词则进行替换, 不然就直接跳过
3.技术的难点在哪
如果直接copy别人的代码调用,那不是很难。但自己写函数,难免遇到思维上的问题。
同时要会自己写代码,方便处理,如 后端管理者可以自主添加敏感词。而不是仅仅只能依靠工具类。
二、技术详述
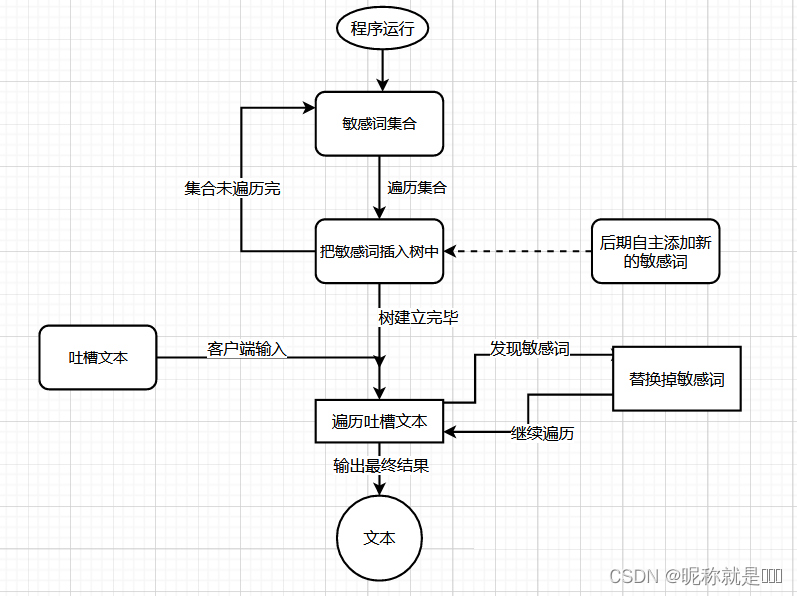
1.流程图
此模型实际上是 模拟字典树(trie) 的方式而来,不过 存放的数据类型 发生了变化
在流程图之前先举几个小栗子理解一下
栗子1:
举这个栗子的作用:下面可以体验一下如何用敏感词建树和查找敏感词
五个敏感词如下:
abc 、 acd 、bac 、cabd 、 ab
画树的过程可想象为: “摸着石头过河” -----一生中,每个人前进的方向都有可能不一样,你走的路前人可能已经走过。也有可能没有前人走过,要你自己探索,创造石头走过,最终到达自己想去的地方,mark一下(拍张照片之类的)
如果前人已经铺好路,即石头存在就可以直接往前走;
若石头不存在就自己创造一颗石头,然后再往前走;
画出的字典树如下:
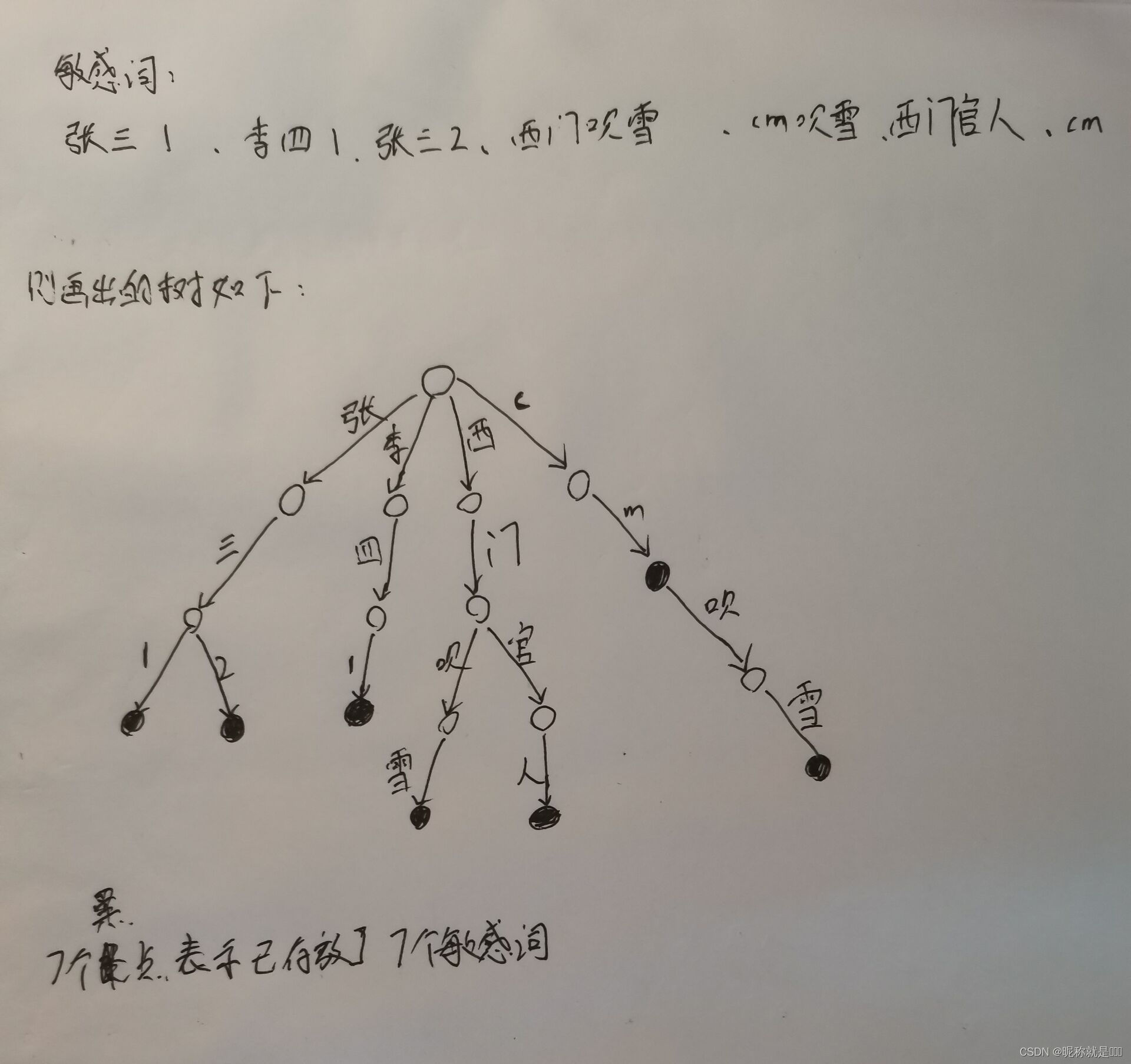
其中 黑点数目表示插入的敏感词的数目

按照上面的图,先简单为例,假设我们得到了一个短语,判断它是不是敏感词呢?
假设此时短语为abc, 按照“摸着石头过河”的想法进行分析,如下:
1. a这块石头存不存在? 存在则过去
2. b这块石头存不存在? 存在则过去
3. c这块石头存不存在? 存在则过去,到达自己想去的地方,则表示这个短语已经在字典树中存在,因此是敏感词
假设此时短语为abd, 按照“摸着石头过河”的想法进行分析,如下:
1. a这块石头存不存在? 存在则过去
2. b这块石头存不存在? 存在则过去
3. d这块石头存不存在? 发现不存在d这块石头,前方的路断了,就表示没有人到达过,则表示这个短语不在字典树中存在,因此不是敏感词
栗子2: 敏感词的组成不再限制于英文字符,可以变成汉字等
举这个栗子的作用:了解DFA敏感词算法的底层数据结构存储的可以不仅仅是英语字符也可以中文汉字,甚至可以是其它东西
7个敏感词如下:
张三1 、 李四1 、张三2 、西门吹雪 、cm吹雪 、西门官人 、cm
画出的树如下:
那这边的数据结构要用到什么呢?
hashMap
因为每个节点下面可能新建的节点是不唯一的,因此最基本是要用List或者集合,但是我们又要在O(1)时间内根据一个敏感字找到具体的子节点,因此最好用hashMap可以key为字符,然后value为hashMap,这样就可以进行树的建立。
下面为HashMap源码,可以看出key与Value都可以任意类型,因此可以创建树结构,想对hashMap了解更多,请参考下方的参考文章

流程图:
2.代码
为简单起见,以下代码基本 copy 自最下方参考文章(请勿判抄袭),且仅仅展示部分代码,并进行改动,结合上面流程图描述思路;若需要完整代码请看参考文章
1.存放敏感词的数据结构
public static HashMap sensitiveWordMap;
2.初始化,并建树
public static synchronized void init(Set<String> sensitiveWordSet) {
//初始化敏感词容器,减小扩容操做
sensitiveWordMap = new HashMap(sensitiveWordSet.size());
String key;
Map nowMap;
Map<String, String> newWorMap;
//迭代sensitiveWordSet
Iterator<String> iterator = sensitiveWordSet.iterator();
while (iterator.hasNext()) {
//关键字
key = iterator.next();
nowMap = sensitiveWordMap;
for (int i = 0; i < key.length(); i++) {
//转换成char型
char keyChar = key.charAt(i);
//库中获取关键字
Object wordMap = nowMap.get(keyChar);
//若是存在该key,直接赋值,用于下一个循环获取
if (wordMap != null) {
nowMap = (Map) wordMap;
} else {
//不存在则,则构建一个map,同时将isEnd设置为0,由于他不是最后一个
newWorMap = new HashMap<>();
//不是最后一个
newWorMap.put("isEnd", "0");
nowMap.put(keyChar, newWorMap);
nowMap = newWorMap;
}
if (i == key.length() - 1) {
//最后一个
nowMap.put("isEnd", "1");
}
}
}
}
3.查找敏感词所在的位置
private static int checkSensitiveWord(String txt, int beginIndex, int matchType) {
//敏感词结束标识位:用于敏感词只有1位的状况
boolean flag = false;
//匹配标识数默认为0
int matchFlag = 0;
char word;
Map nowMap = sensitiveWordMap;
for (int i = beginIndex; i < txt.length(); i++) {
word = txt.charAt(i);
//获取指定key
nowMap = (Map) nowMap.get(word);
if (nowMap != null) {//存在,则判断是否为最后一个
//找到相应key,匹配标识+1
matchFlag++;
//若是为最后一个匹配规则,结束循环,返回匹配标识数
if ("1".equals(nowMap.get("isEnd"))) {
//结束标志位为true
flag = true;
//最小规则,直接返回,最大规则还需继续查找
if (MinMatchTYpe == matchType) {
break;
}
}
} else {//不存在,直接返回
break;
}
}
if (matchFlag < 2 || !flag) {//长度必须大于等于1,为词
matchFlag = 0;
}
return matchFlag;
}
4.进行替换处理
//获取替换字符串
private static String getReplaceChars(char replaceChar, int length) {
String resultReplace = String.valueOf(replaceChar);
for (int i = 1; i < length; i++) {
resultReplace += replaceChar;
}
return resultReplace;
}
5.继续遍历文本查找剩下的敏感词 (本函数为自己写的,直接获取新的文本内容,而不是如参考文章中 先收集敏感词,再集中替换)
public static String getNewTest(String txt) {
//用于构造新的Txt
StringBuilder bd=new StringBuilder();
for (int i = 0; i < txt.length(); i++) {
//判断是否包含敏感字符
int length = checkSensitiveWord(txt, i, matchType);
if (length > 0) {//存在敏感词,进行替换
bd.append("****");
i = i + length - 1;//减1的缘由,是由于for会自增
}else{
bd.append(txt[i]);
}
}
return bd.toString();
}
三、技术过程中遇见的问题和解决过程
代码运用基本不难,难的是前期的思考,就比如此数据结构为何要用hashMap,而不用其它数据结构,如果理
解比较清楚就可以对上面的函数进行改造,然后运用
对于很多新增的敏感词可以在后台审核时,如果判定这个词是敏感词,此时再插入树(hashMap)中,使敏感词
的词库变大,而不仅仅只是那些词
具体运用就是在Service层里的方法,调用以上方法对前端传来的数据进行过滤处理 ==> 得到过滤后的结果
四、总结
如果只想简单利用,直接copy参考文献即可,简单修改即可用
若想理解清楚,并自己实现代码,就需要理解
1. 普通Trie树的创建与查询,最好自己手动画一下树,以及自己思考几个样例进行查询
2. 理解hashMap的优势在哪,为什么要用到这个数据结构
3. 自己代码实现
若想要更进一步,
1. 思考ac自动机(基础为Trie树和KMP模式匹配算法)可以用于这个敏感词检索吗,它使用于什么场景下?
2. 对于很多谐音识别不了(固定词库不够大),人为识别也太麻烦,因此最好的方式还是要利用神经网络进行训练














 1511
1511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









