







创建虚拟机
使用陈情令快照克隆虚拟机:虚拟机的复制、快照和克隆
新建虚拟机网络上有许多教程:CentOS 6.5系统安装配置图解教程,这里就不详细描述,可看链接,本文有连接网络的教程
配置基础信息
修改主机名
vi /etc/sysconfig/network //命令
HOSTNAME=master001 //修改主机名
修改网卡
vi /etc/udev/rules.d/70-persistent-net.rules
注释掉第一个网卡,改第二个网卡的"eth1"为"eth0"
修改地址配置
vi /etc/sysconfig/network-scripts/ifcfg-eth0 //命令
ONBOOT=yes //开启dns
BOOTPROTO=static //设置静态
IPADDR=192.168.43.101
NETMASK=255.255.255.0
GATEWAY=192.168.43.2
修改DNS域名解析配置文件
vi /etc/resolv.conf //命令
nameserver 192.168.43.2 //插入配置
设置hosts文件
vi /etc/hosts //命令
192.168.43.101 master001 //插入
192.168.43.102 master002
192.168.43.201 slave001
192.168.43.202 slave002
192.168.43.203 slave003
重启
reboot
验证
可以通过ping ip地址,百度验证网络是否接通
创建普通用户
adduser hadoop //创建Hadoop用户
passwd hadoop //为Hadoop用户创建密码
创建software目录
mkdir software
下载hadoop压缩包
下载地址:http://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/
下载jdk压缩包
jdk1.8,64位linux版本下载路径.永久免费
下载SecureCRTPortable软件外接虚拟机,比较容易操作

使用SecureFXPortable链接虚拟机,在用户Hadoop的文件夹中创建software文件夹,并上传jkd压缩包

解压与安装jdk
解压
进入software文件夹,ls命令查看文件夹下内容,有jdk的压缩包,tar命令解压,再查看software下的内容,现在就有jdk的解压包;
复制安装路径
进入解压包的路径下,用pwd命令查看当前工作路径(jdk的安装路径)

更改环境变量
su -l root //切换root(管理员)用户
vi /etc/profile //进入环境变量配置文件
//插入:
#java
export JAVA_HOME=/home/hadoop/software/jdk1.8.0_11
export PATH=$PATH:$JAVA_HOME/bin
Esc+:wq //退出文件
source /etc/profile //使变量生效
验证
输入java或者java -version,若出现版本号或者命令详解,则安装成功,若出现command not found,则安装失败,回过头仔细检查一下是否输错命令或打错字母
解压与安装Hadoop
解压
进入software文件夹,ls命令查看文件夹下内容,有hadoop的压缩包,tar命令解压,再查看software下的内容,现在就有hadoop的解压包;
复制安装路径
进入解压包的路径下,用pwd命令查看当前工作路径(hadoop的安装路径)

更改环境变量
su -l root //切换到root用户
vi /etc/profile //更改环境变量配置
//插入:
#hadoop
export HADOOP_HOME=/home/hadoop/software/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
ESC+:wq //退出写入
source /etc/profile //使环境变量生效
验证
输入hadoop,若出现版本号或者命令详解,则安装成功,若出现command not found,则安装失败,回过头仔细检查一下是否输错命令或打错字母
配置core-site.xml文件
使用hadoop用户,进入software/hadoop-2.6.5/etc/hadoop/的目录下,修改core-site.xml文件

<configuration>
//插入:
<!--指定Zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>slave001:2181,slave002:2181,slave003:2181</value>
</property>
<!--指定Hadoop临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/software/hadoop-2.6.5/tmp</value>
</property>
<!--指定Eclipse访问端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
</configuration>
配置hadoop-env.sh文件
修改java_home地址(地址是解压jdk的地址),其作用是为了使用java环境

# The java implementation to use.
export JAVA_HOME=/home/hadoop/software/jdk1.8.0_11
配置hdfs-site.xml
hdfs-site.xml文件Hadoop2.0之后必备配置文件之一,可以在其中配置集群名字空间、访问端口、URL地址、故障转移等

vi hdfs-site.xml
<configuration>
//插入:
<!--设置设备备份数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定高可用集群的名字空间-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 指定NameNone节点的名字空间-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- rpc:远程调用,设置第一个远程调用的地址和端口-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>master001:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>master002:9000</value>
</property>
<!-- 设置网页访问的地址和端口-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>master001:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>master002:50070</value>
</property>
<!-- 设置共享edits的存放地址,将共享edits文件存放在QJournal集群中的QJCluster目录下-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave001:8485;slave002:8485;slave003:8485/QJCulster</value>
</property>
<!-- 设置JournalNode节点的edits文件本地存放路径,是QJournal真实数据存放路径-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/software/hadoop-2.6.5/QJEditsData</value>
</property>
<!-- 开启自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 设置HDFS客户端用来与活动的namenode节点联系的java类-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.hs.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 用于停止活动NameNode节点的故障转移期间的脚本,保证任何时候都只有一个NameNode处于活动状态;
SShfence参数:采用ssh方式连接活动NameNode节点,并杀掉进程;
shell脚本:表示如果sshfence执行失败,在执行自定义的shell脚本,确定只能有一个NameNode处于活动状态-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/home/hadoop/software/hadoop-2.6.5/ensure.sh)
</value>
</property>
<!-- 为了实现SSH登录杀掉进程,还需要配置免密码登录的SSH密匙信息-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 设置SSH连接超时-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
配置mapred-site.xml文件
在hadoop包中是没有这个文件的,需要通过mapred-site.xml.template模板文件复制出此文件,如下操作:

cp mapred-site.xml.template mapred-site.xml //命令
vi mapred-site.xml
<configuration>
//插入:
<!-- 设置jar程序启动Runner类的main方法运行在yarn集群中-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置slaves文件
hadoop集群中所有的DataNode节点都需要写入slaves文件中,因为它是用来指定存储数据的节点文件,Master会读取slaves文件来获取存储信息,根据slaves文件来做资源平衡
注意:
(1)slaves文件名全部都是小写;
(2)slaves文件打开后哦里面有一个“localhost”,这个localhost需要删除,否则集群会把master也当做DataNode节点,会造成master节点负载过重
vi slaves //命令
//删除
localhost
//插入
slave001
slave002
slave003
配置yarn-site.xml
此文件是ResourceManager进程相关配置参数

<configuration>
//插入:
<!-- 设置ResourceManager在哪台节点-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master001</value>
</property>
<!-- Reduce取数据的方式是mapreduce_shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
安装SSH
- shh、yum解析
- 在线安装yum工具,切换到root用户
- 使用命令查找yum库有哪些SSH软件的rpm包

- 使用yum工具在线安装server和client软件,安装过程如图
yum install -y openssh-clients.x86_64
yum install -y openssh-server.x86_64



验证ssh安装成功
输入ssh命令,出现类似如下则安装成功,command not found则安装失败
复制虚拟机
关闭master001
halt //关机命令,需要root权限
复制虚拟机
进入master001的存储文件夹,复制四个副本,作为新的虚拟机,修改四个新虚拟机的名称并用VMware打开

通过选择“我已复制该虚拟机”来告诉VMware平台“我这台虚拟机需要生成一个新的MAC地址”,如果选择其他,则无法生成新的MAC地址

修改虚拟配置
查看MAC地址
cat /etc/udev/rules.d/70-persistent-net.rules

最后一条为最新的MAC地址,并记住ATTR和NAME的值
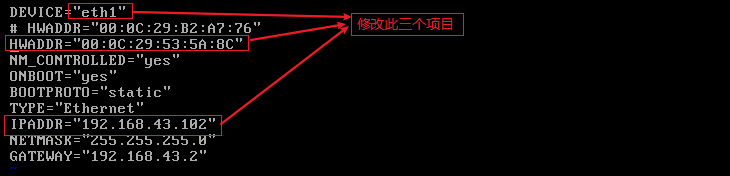
修改MAC地址和IP地址
需要到profile文件中修改最新的MAC地址和网络名称
vi /etc/sysconfig/network-scripts/ifcfg-eth0 //未修改前的“eth0”未更改
修改主机名
vi /etc/sysconfig/network
//改写:
HOSTNAME=master002
//重启使修改生效
reboot
验证修改成功
使用ifconfig命令

修改成功,接下来使用此方法修改其他虚拟机,在此就不一一写命令,只贴图



ping 其他虚拟机以验证内网联通
!!!需要同时开启所ping 虚拟机才能ping得通
设置免密
安装Hadoop之前,由于集群中**!!!!!!!!!未写完**
生成密匙
由于要对Hadoop用户进行免密设置,所以需要切换到Hadoop,并回到其家用户
cd ~
ssh-keygen -t rsa -P ''
执行ssh-keygen -t rsa -P此命令后,将在/home/hadoop/.ssh/目录下以rsa方式生成id_rsa的密匙

对所有节点进行免密
将密匙……
ssh-copy-id master001
ssh-copy-id master002
ssh-copy-id slave001
ssh-copy-id slave002
ssh-copy-id slave003





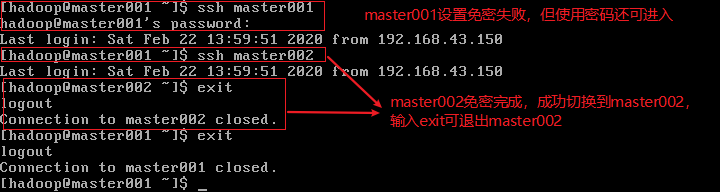
验证免密成功与否
将前面注释掉的HWADDR还原防止找不到虚拟机

master002执行上述同样操作,还原master001的MAC地址后,master002设置master001免密成功!
安装zookeeper
下载zookeeper
下载zookeeper-3.4.10.tar.gz
上传到slave003的hadoop用户software文件夹下:

配置zookeeper
进入Hadoop用户的software目录下,解压zookeeper文件

tar -zxf zookeeper-3.4.10.tar.gz
进入zookeeper的conf目录,将zoo_sample.cfg模板复制出zoo.cfg文件并编辑zoo.cfg文件

cd software/zookeeper-3.4.10/conf
ls
cp zoo_sample.cfg zoo.cfg
ls
vi zoo.cfg
//改写:
//快照存放目录
dataDir=/home/hadoop/software/zookeeper-3.4.10/tmp/zookeeper
//插入:
//服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口),这个配置项的书写格式比较特殊,规则如下:server.N=YYY:A:B
server.1=slave001:2888:3888
server.2=slave002:2888:3888
server.3=slave003:2888:3888
创建/home/hadoop/software/zookeeper-3.4.10/tmp/zookeeper文件夹

mkdir -p /home/hadoop/software/zookeeper-3.4.10/tmp/zookeeper
cd /home/hadoop/software/zookeeper-3.4.10/tmp/zookeeper
vi myid //创建myid文件并编辑
//插入:
3
传输到zookeeper配置
将slave003中的zookeeper目录传送到slave001和slave002,过程中需要输入密码

cd ~/software/
ls
//scp -r zookeeper-3.4.10/ slave003:~/software/ 命令格式
scp -r zookeeper-3.4.10/ slave001:~/software/
scp -r zookeeper-3.4.10/ slave002:~/software/
将slave001和slave002的hadoop用户的/software/zookeeper-3.4.10/tmp/zookeeper目录下的myid分别修改为1和2
slave001:
cd software/zookeeper-3.4.10/tmp/zookeeper
vi myid
1
slave002:
cd ~/software/zookeeper-3.4.10/tmp/zookeeper
vi myid
2
启动zookeeper
zookeeper没有设置环境变量,所以要想启动zookeeper则要进入**~/software/zookeeper-3.4.10/bin/**目录的bin下开启zookeeper的服务文件zkServer.sh,也可以通过服务文件查看服务状态和停止集群
cd ~/software/zookeeper-3.4.10/bin/
ls
./zkServer.sh start
jps
启动时如果有错误,仔细检查一次zoo.cfg有没有打错、打漏,否则会出现zookeeper_server.pid: No such file or directory这种错误
成功启动会出现以下页面

启动Hadoop集群
启动journalnode进程
格式化NameNode时需要到zookeeper每个节点上分别启动journalnode进程
hadoop-daemon.sh start journalnode
Hadoop相关:分布式,数据存储,数据计算
Hadoop框架核心:HDFS和MapReduce,是Hadoop的基础
HDFS为数据提供分布式存储
MapReduce为数据进行处理
















 1709
1709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









