







偶然翻起电脑里的文件,突然发现了这篇文档,已然一年有余。也该回忆Hadoop下安装配置完全分布式集群的步骤和方法了。
前言:
Hadoop完全分布式集群:按照hadoop集群的基本要求,其中一个是master节点,它的作用是用于运行hadoop程序中的namenode、secondarynamenode和jobtracker(2.x版本取消了这种叫法)。另外的两个节点就是slave节点,运行hadoop程序汇总的datanode和tasktracker。因此,本系统安装了三台虚拟主机,主机名分别为:master,slave1,slave2。
配置环境:
处理器:Intel(R) Core(TM) i5-3210M CPU @ 2.50GHz (4CPUs), ~2.5GHz
内存:4GB
软件环境:
操作系统:win7
系统类型:64位操作系统
软件安装包:hadoop-2.7.1、jdk1.7.0_79
需安装的主机系统:
<span style="font-family:Times New Roman;"> Namenode:master(ip:192.168.33.11)
Datanode:slave1(ip:192.168.33.12)、slave2(ip:192.168.33.13)</span>1.配置主机hosts
<span style="font-family:Times New Roman;"> 192.168.33.11 master
192.168.33.12 slave1
192.168.33.13 slave2</span>(2)在所有机器上都使用相同的用户:root用户,本系统用来测试实践的。具体的使用要看个人意愿,也可使用自己创建的非root用户。
2. 配置SSH免密码登录
这个环节比较重要,而且很关键。SSH主要通过RSA算法来产生公钥和私钥,传输过程中对数据进行加密来保障数据的安全性和可靠性,公钥部分是公共部分,私钥主要用于对数据进行加密,以防数据被盗窃。Hadoop集群的各个节点之间需要进行数据的访问,访问与被访问的节点都必须进行验证。使用SSH的方法通过密钥验证及数据加密方式进行远程安全登录操作。
(1) 在每个节点分别产生公私密钥:
# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
上述命令产生公私密钥,产生目录在root用户主目录的.ssh目录下。使用ls命令,就可以看到目录下产生了“ id_rsa(私钥) id_rsa.pub(公钥) “。
紧接着把公钥文件复制成authorized_keys文件,这是必须要完成的。
# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys(2) 配置完后。在当前目录下使用ssh localhost 来验证使用登录成功。成功后注销退出。 (3) 让主节点(master)通过SSH免密码登录两个子节点(slave) 要实现这个功能,两个slave节点中的公钥文件可是必须要包含主节点的公钥信息,这样master节点就可以顺利安全地访问两个slave节点了。
在slave1主机下:
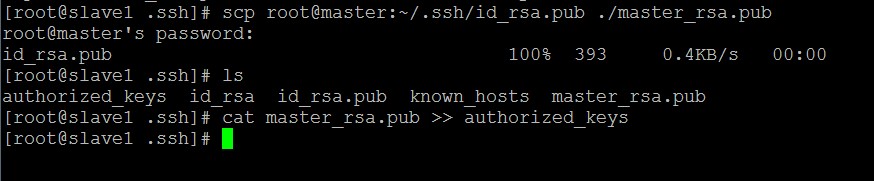
上述过程显示了node1节点通过scp命令远程登录master节点,并复制master的公钥文件到当前目录下,这一过程需要密码验证。然后将master节点的公钥文件追加到authorized_keys文件中,通过这步的操作,master节点就可以通过ssh免密码连接到node1节点了。 在node1节点中首次连接时需要, "YES"确认连接,这意味着master节点在连接node1时需要咨询用户,否则无法连接,输入yes后成功接入,紧接着注销退至master节点。要实现ssh免密码登录连接到其他节点,还需要重新执行一次sshslave1,如果没有要求输入"yes",那便是成功了。

如上图所示,master已经可以通过ssh免密码登录到slave1节点。有关slave2节点的ssh免密码登录和slave1节点配置一样。对master自身进行ssh免密码登录测试工作:

至此,SSH密码登录已经配置成功。
3.配置JDK
在oracle官网下载jdk-7u79-linux-x64.tar.gz,安装到/home/java下,使用 vi .bash_profile在当前用户目录下设置java的环境变量:
#setjava environment
exportJAVA_HOME=/home/java/jdk1.7.0_79
exportPATH=$PATH:$HOME/bin:${JAVA_HOME}/bin保存退出后,使用source .bash_profile即可
输入 java -version命令,出现下面的命令即是配置成功。
[root@master~]# java -version
javaversion "1.7.0_79"
Java(TM)SE Runtime Environment (build 1.7.0_79-b15)
JavaHotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mod4.配置hadoop安装包
在hadoop官网下载hadoop-2.7.1.tar.gz安装包,安装包解压到/home下。使用 vi /etc/profile修改系统环境配置,在文件末尾加入下面的内容:
#set hadoopenvironment
exportHADOOP_HOME=/home/hadoop-2.7.1
exportPATH=$HADOOP_HOME/bin:$PATH
保存退出后,使用source /etc/profile即可。5.配置hadoop-env.sh文件
使用cd /home/hadoop-2.7.1/etc/hadoop中,找到hadoop-env.sh
文件,使用vi编辑,根据自己安装java的路径进行修改,使得hadoop能够找到java的路径。

6.配置nameNode
6.1 修改core-site.xml文件
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<name>hadoop.tmp.dir</name>
<value>/home/Kevin-YE/tmp</value>
</property>
</configuration>
<property>注意:hadoop.tmp.dir是hadoop文件系统依赖的基础配置,很多路径都依赖它。它默认的位置是在/tmp/{$user}下面,在local和hdfs都会建有相同的目录,但是在/tmp路径下的存储是不安全的,因为linux一次重启,文件就可能被删除。导致namenode启动不起来。
6.2 修改hdfs-site.xml文件
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.1.101:9001</value>
</property>
</configuration><span style="font-family:Times New Roman;font-size:18px;">
</span>6.3 修改mapred-site.xml
注意:2.x版本要用mv命令把mapred-site.xml.temple改成mapred-site.xml文件
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.33.11:9001</value>
</property>
</configuration><span style="font-size:18px;"><strong>
</strong></span>7. 配置masters文件和slaves文件
在cd /home/hadoop-2.7.1/etc/hadoop中,使用vi masters里写入namenode节点机器的IP地址地址:
192.168.33.11在slaves中写入作为datanode节点机器的IP地址:
192.168.33.12
192.168.33.138. 格式化namenode
初次启动hadoop,先要关闭所有机器上的防火墙,不然会导致datanode起不来。
<span style="font-family:Times New Roman;"> /etc/init.d/iptables stop</span>在主节点master上进行操作:
<span style="font-family:Times New Roman;"><span style="white-space: pre;"> </span>Hadoop namenode -format</span>在主节点master上进行操作:
<span style="font-family:Times New Roman;"> <span style="white-space:pre"> </span>(1)cd /home/hadoop-2.7.1/sbin
<span style="white-space:pre"> </span>(2)./start-dfs.sh</span>如果没有其他的错误,那么hadoop就会正常启动,并且能看到下面的内容:
<span style="font-family:Times New Roman;">[root@master sbin]# jps
XXXX SecondaryNameNode
XXXX Jps
XXXX NameNode</span><span style="font-family:Times New Roman;">[root@slave1 sbin]# jps
XXXX Jps
XXXX DataNode</span><span style="font-family:Times New Roman;">[root@slave2 sbin]# jps
XXXX Jps
XXXX DataNode</span>














 3558
3558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









