







根据JVM不同版本的迭代,我们从最古老的垃圾回收器谈起,分别是早期的Serial和Serial Old,中期的Parallel Scavenge及Parallel Old,过渡期的ParNew和CMS,以及现在的G1,未来的ZGC。
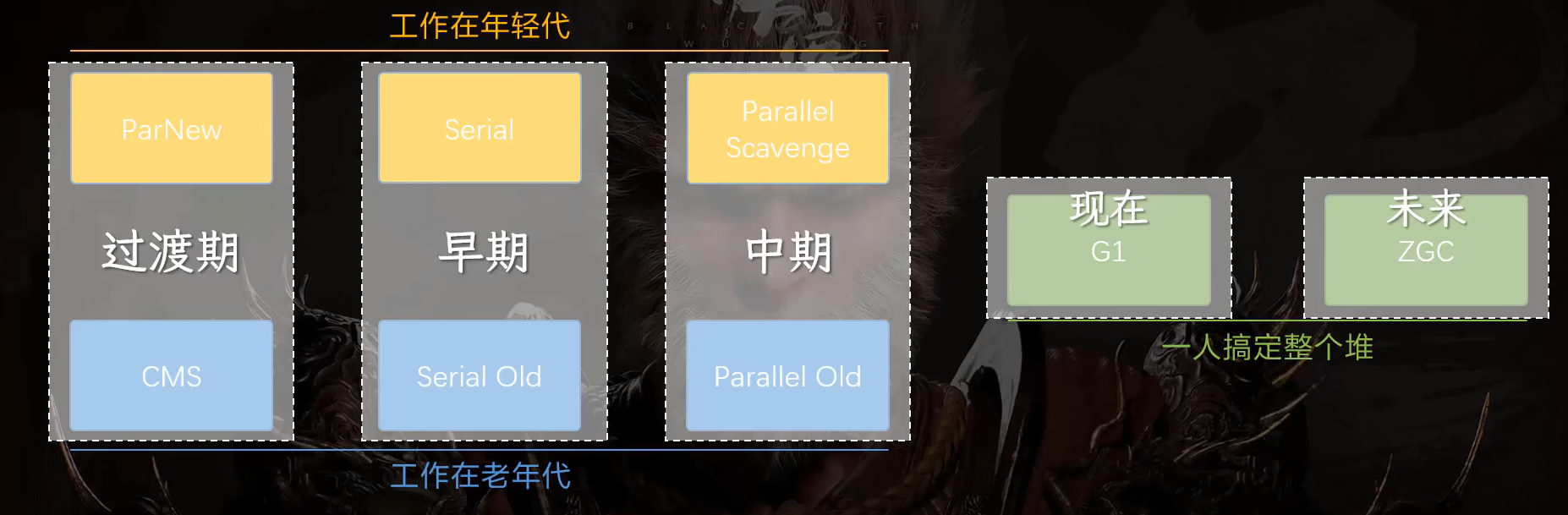
Serial和Serial Old
也叫Serial Young或Serial New,是一个工作在新生代的垃圾回收器,所以一般会有一个搭档负责老年代的垃圾回收,叫Serial Old,这种垃圾回收器是单线程的,不支持并发。
举例说明:
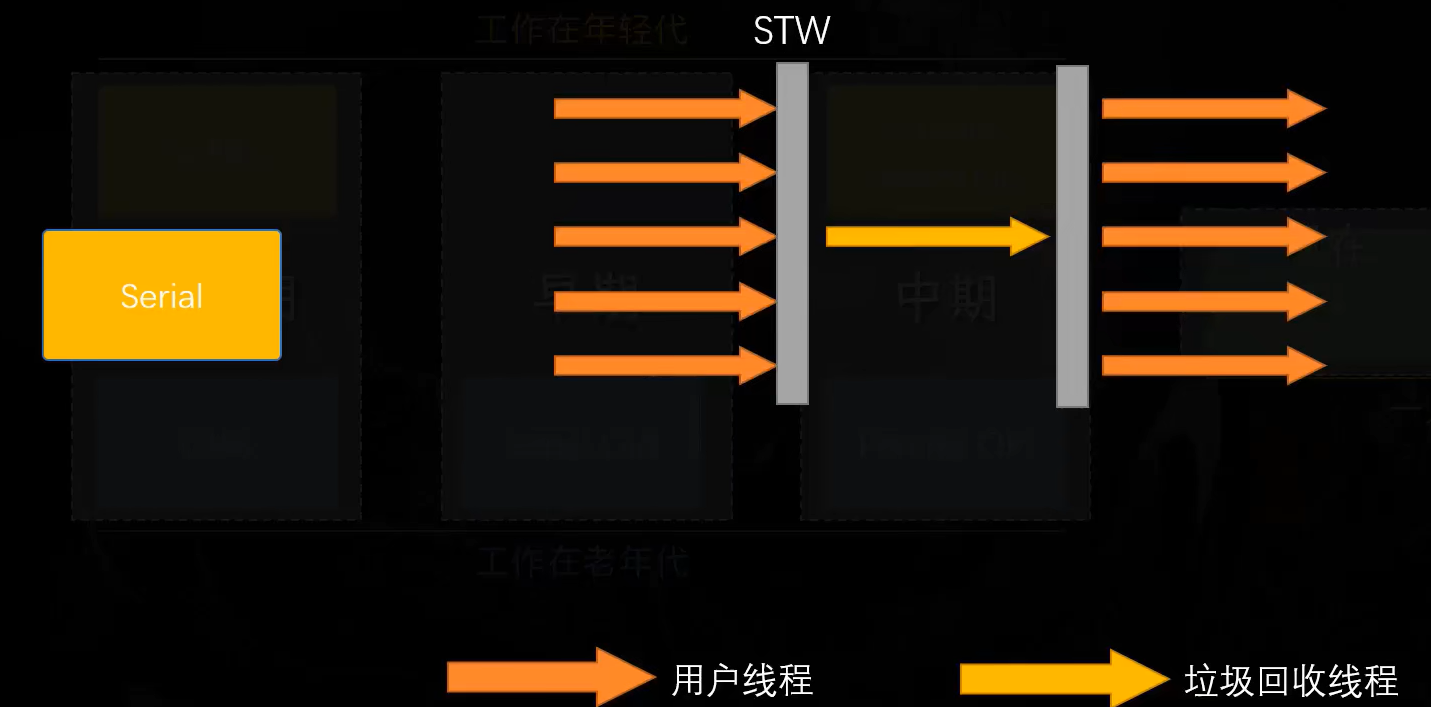
当开始垃圾回收时,所有用户线程必须全部暂停,这个动作叫做STW(Stop The World)。
随后垃圾回收器线程开始工作,标记并回收垃圾。
STW结束,用户线程恢复。
随着时间的发展,实际业务的变化,物理内存变得越来越大,这种工作模式很快就不能适应了。STW时间已经变得也来越长,它所造成的服务器卡顿,最高可以长达数十个小时。
Parallel Scavenge和Parallel Old
后来出现了Parallel Scavenge和Parallel Old,它们是多线程的垃圾回收器。
举例说明:
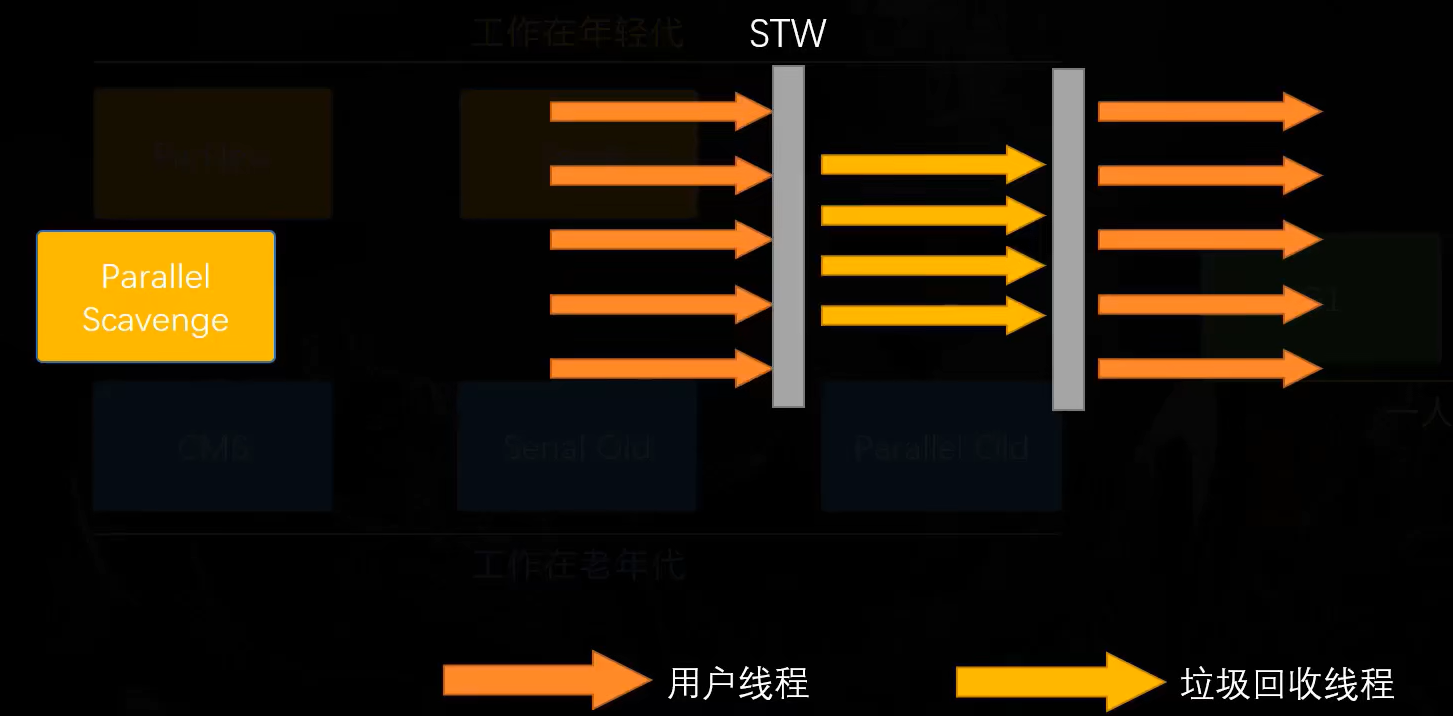
当开始垃圾回收时,所有用户线程必须全部暂停,依然触发了STW。
不过这次垃圾回收变成了多线程,对于多CPU的服务器来讲,提高了不少效率,但STW这个动作依然不可避免。
ParNew和CMS
后来就有了CMS,它支持并发。与它搭档的新生代回收器叫做ParNew,ParNew跟Parallel Scavenge几乎没有区别,就是为了搭配CMS做了一些调整。
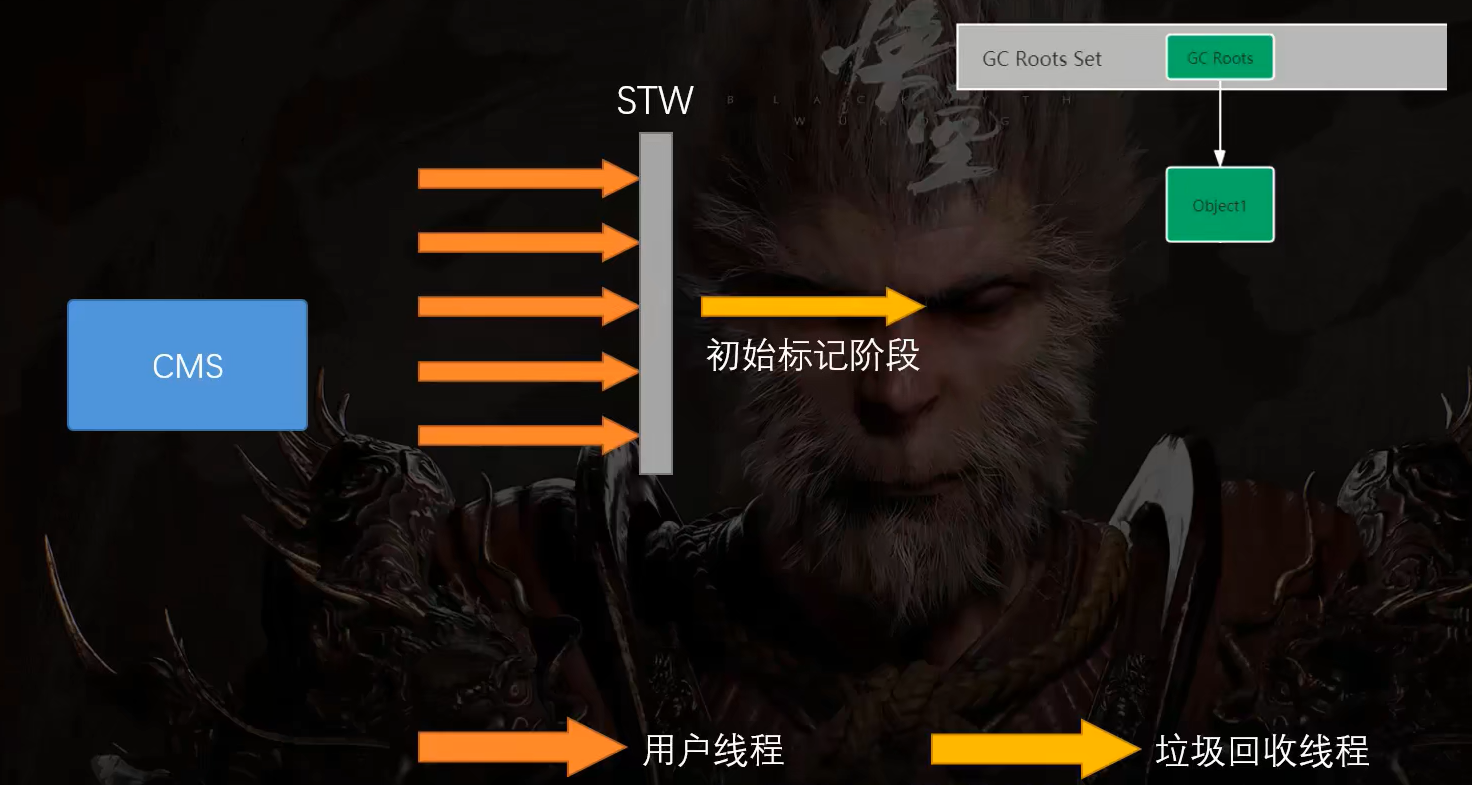
CMS的并发工作流程:
这是用户线程,CMS介入也会触发STW。
不过,在初始标记垃圾的阶段,它只会标记根对象的第一层,因此,停顿时间比较短。
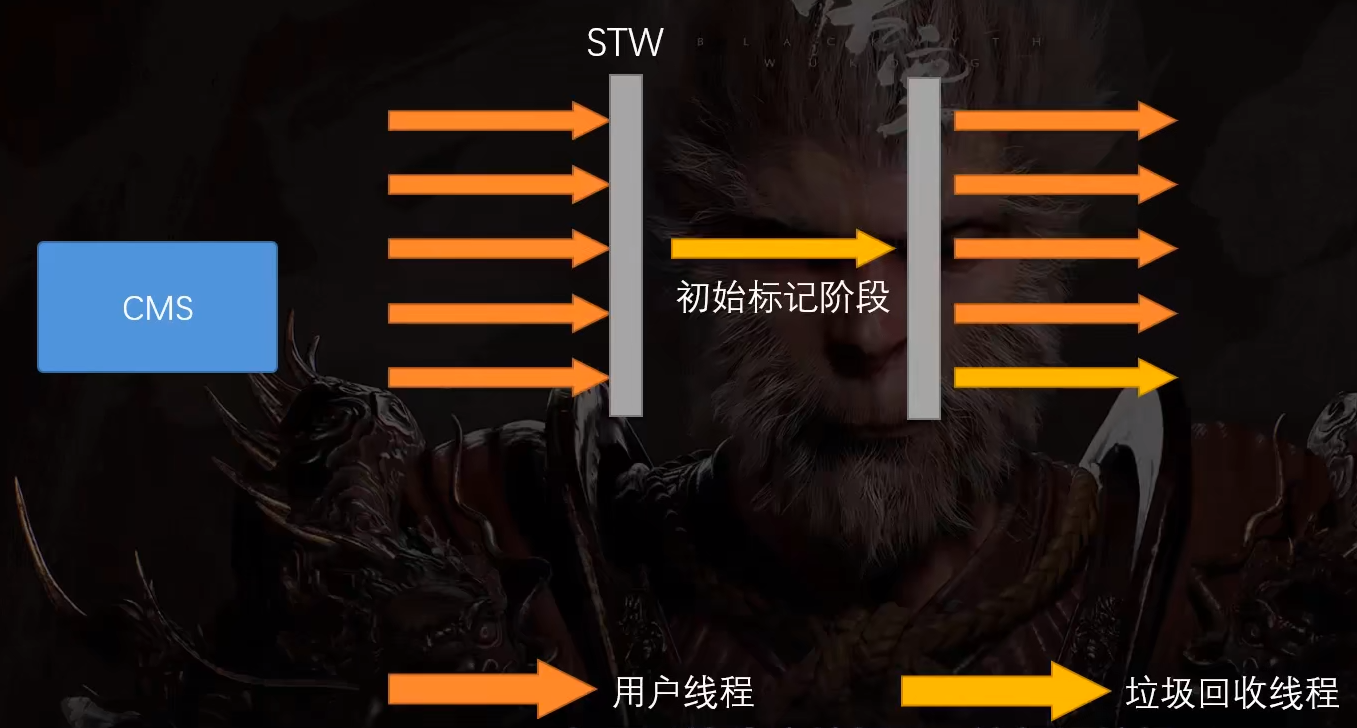
多线程的工作是极其复杂的,如果一边生产垃圾,一边标记垃圾,就会不可避免的产生错标、漏标的问题。
错标是如何产生的呢?
例如,当你调用了一个obj.close();方法,该方法是异步的,紧接着obj被设为null。
此时,CMS扫描到它,将obj标记为垃圾。
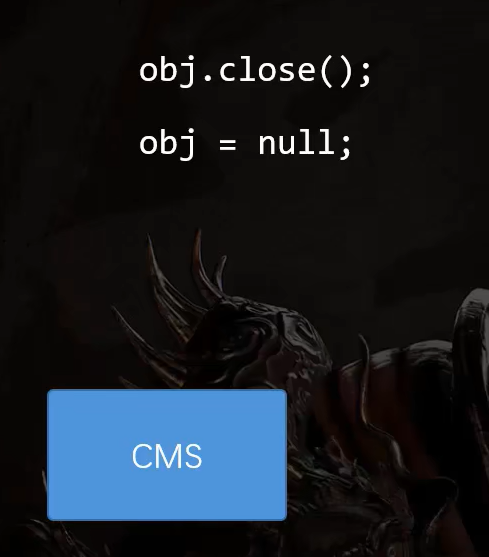
在500ms之后,close()方法当中,obj又将自身引用this传递给了其他对象,那么,obj从垃圾又回到了正常使用的状态。

但此时CMS并不知情,依然会把obj回收掉。
由于错标的存在,CMS又设计了一个阶段,叫做重新标记,它也会触发STW。
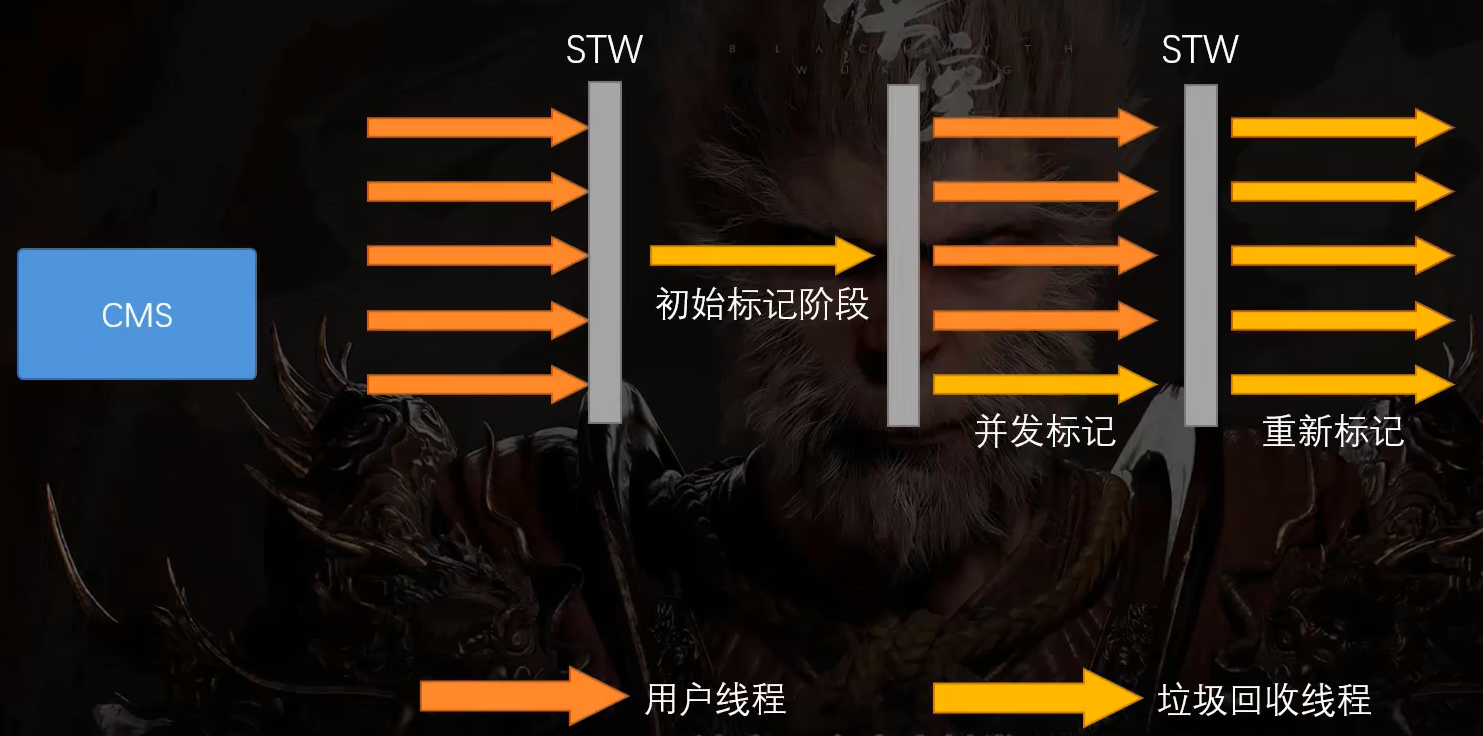
以多线程的方式重新修正错误的标记,然后再以并发的方式清理垃圾
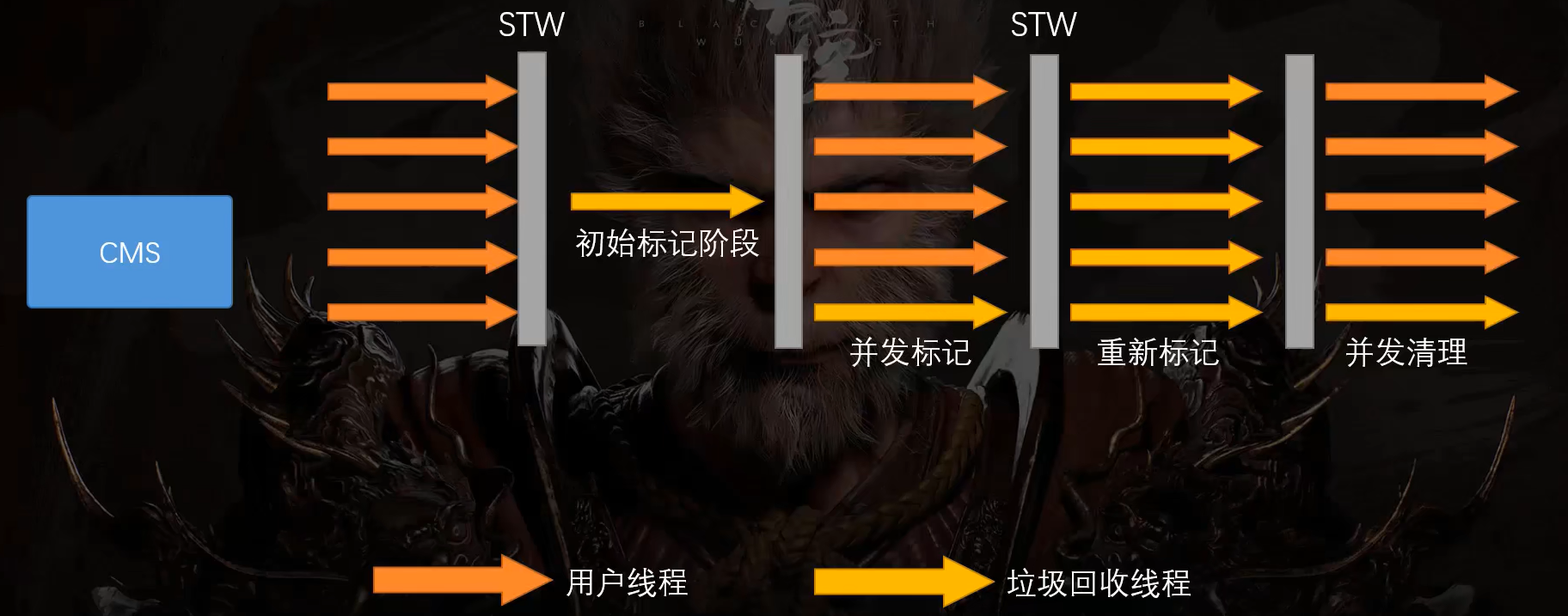
G1
CMS解决了一些问题,但又带来了不少新的问题。从jdk-1.7后,就出现了一个叫做G1的垃圾回收器。不过,直到1.9以后,才变成jdk默认的垃圾回收器。
G1不需要任何搭档,一个人就可以管理整个堆内存,它的机制也更加复杂。
G1允许用户手动设置一个期望的STW时间,当然,这并不是说可以任意调整STW时间。G1也不保证一定能够准确的符合这个设置的时间,它只会尽量靠近这个时间。
它是如何做到的呢?
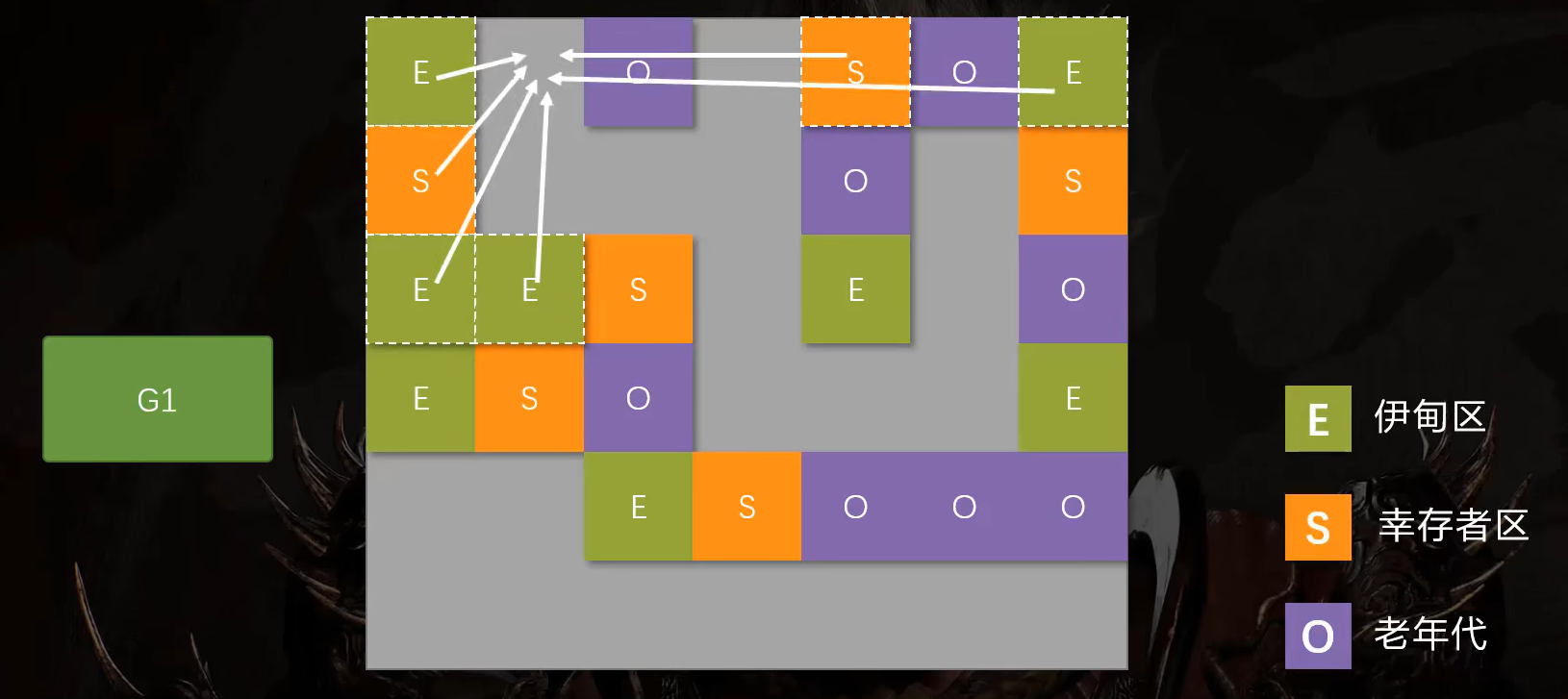
首先,G1将整个堆内存划分为若干相等大小的区域,区域的数量一般默认为2048。
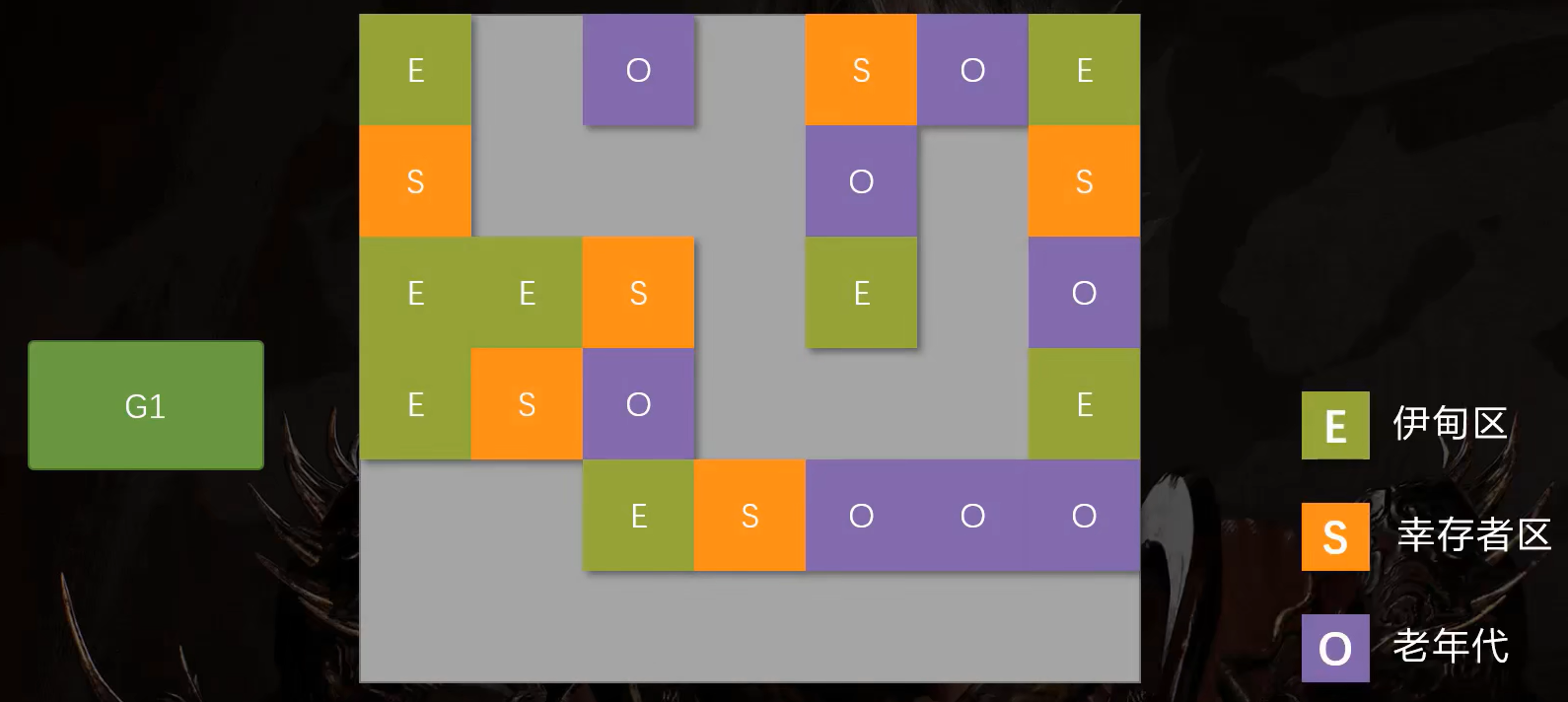
当一块区域被年轻代使用时,它就属于年轻代。当清空回收后,又被老年代使用时,它就属于老年代。
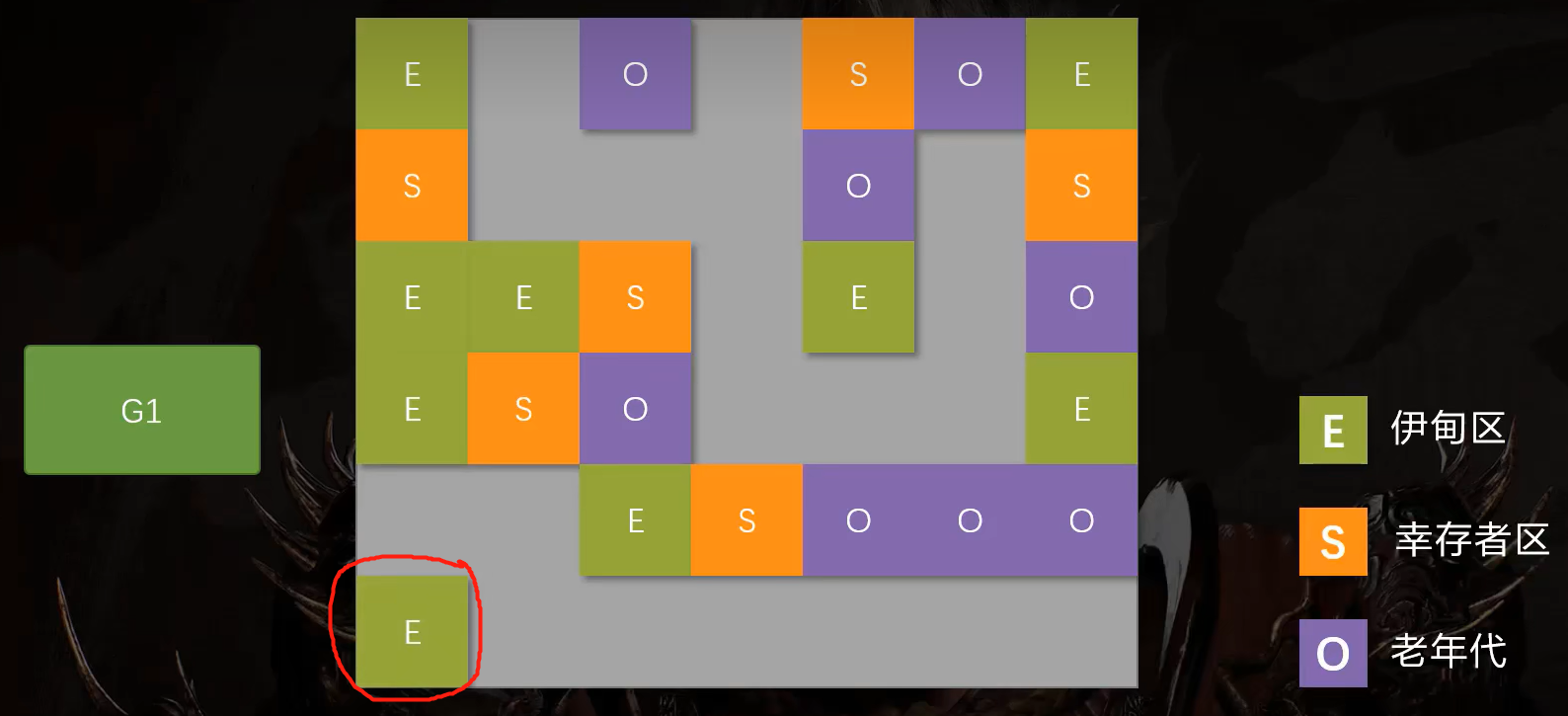
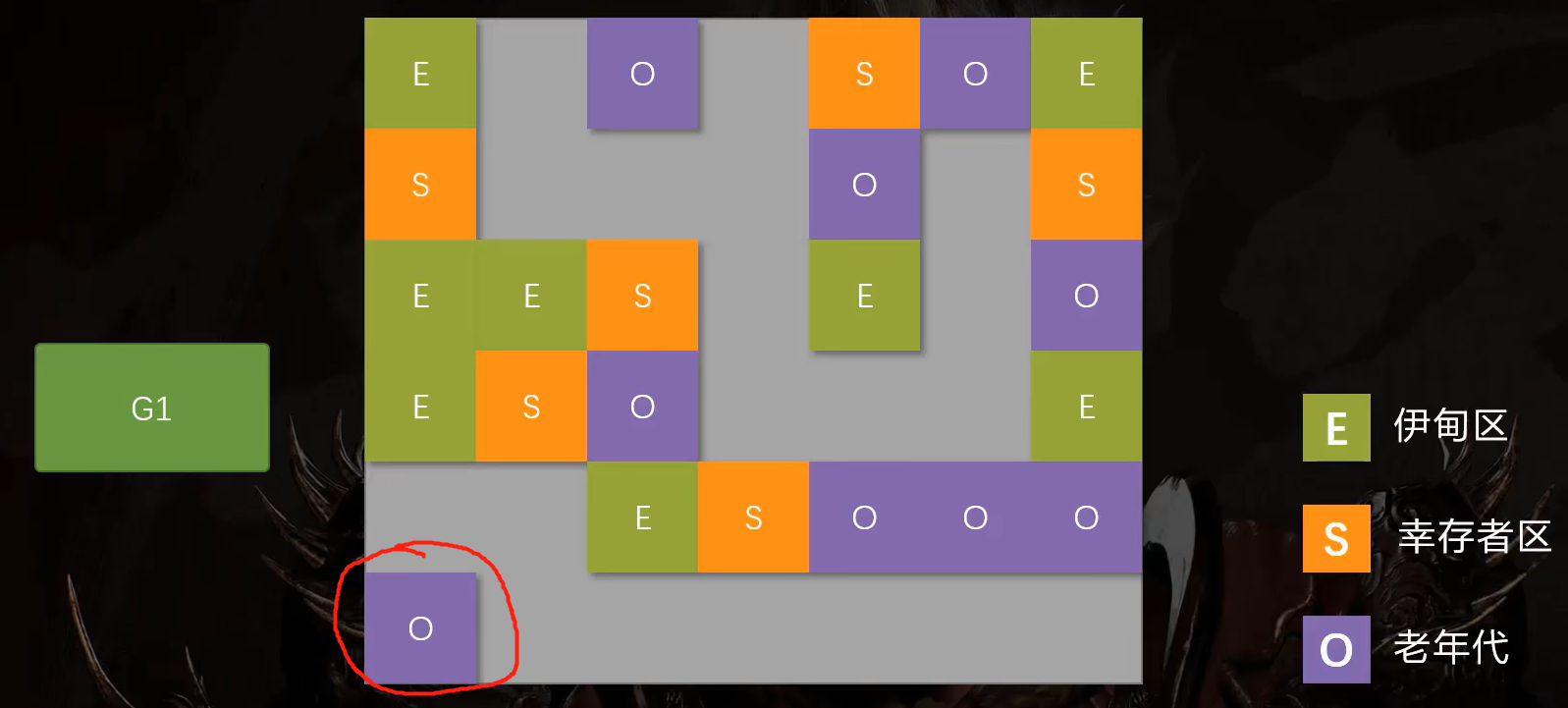
这不仅方便了扩展,而且当GC扫描内存时,它无需扫描整块内存,而是扫描特定区域的内存即可。大大提高了它所能支持的堆内存的大小。
G1的设计原本也是针对大内存使用的,因此,在它的设计当中,会有大量空间换时间的算法细节。
当G1进行垃圾回收时,它会根据设定的STW时间来调整策略,会将需要扫描的区域,进行价值排序。因为不同的区域垃圾数量不同,回收的时间也不太一样。如果设定了50ms,它就会尽可能的保证50ms的时间,优先回收一部分区域。


如果业务对用户的响应时间、计算要求都比较高,就必须在兼顾吞吐量情况下,来对GC策略进行调整。
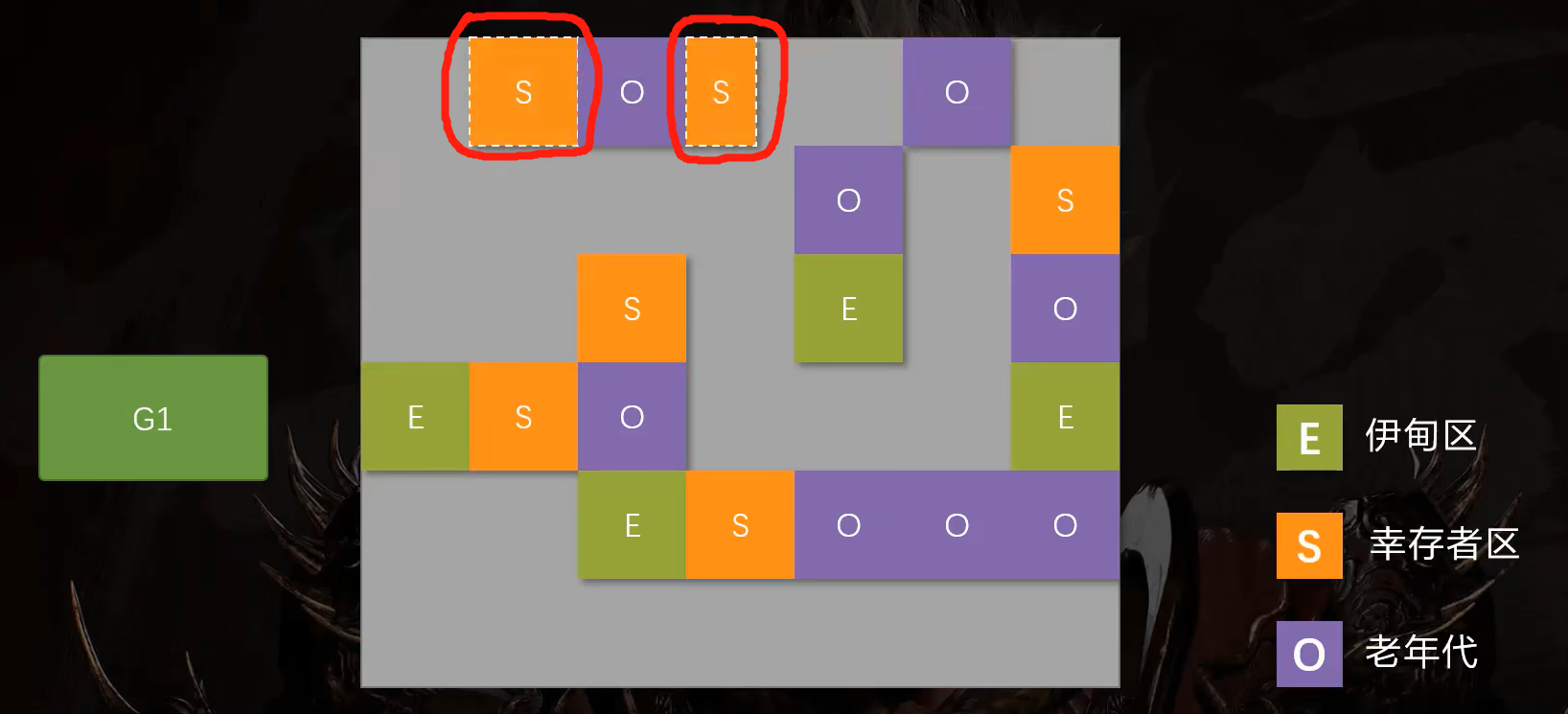
表面上看,G1划分的区域,也会产生碎片。但G1在垃圾回收时,区域之间依然采用了复制算法,直接进行了碎片整理。
举例说明:
假设这几个区域要进行垃圾回收。
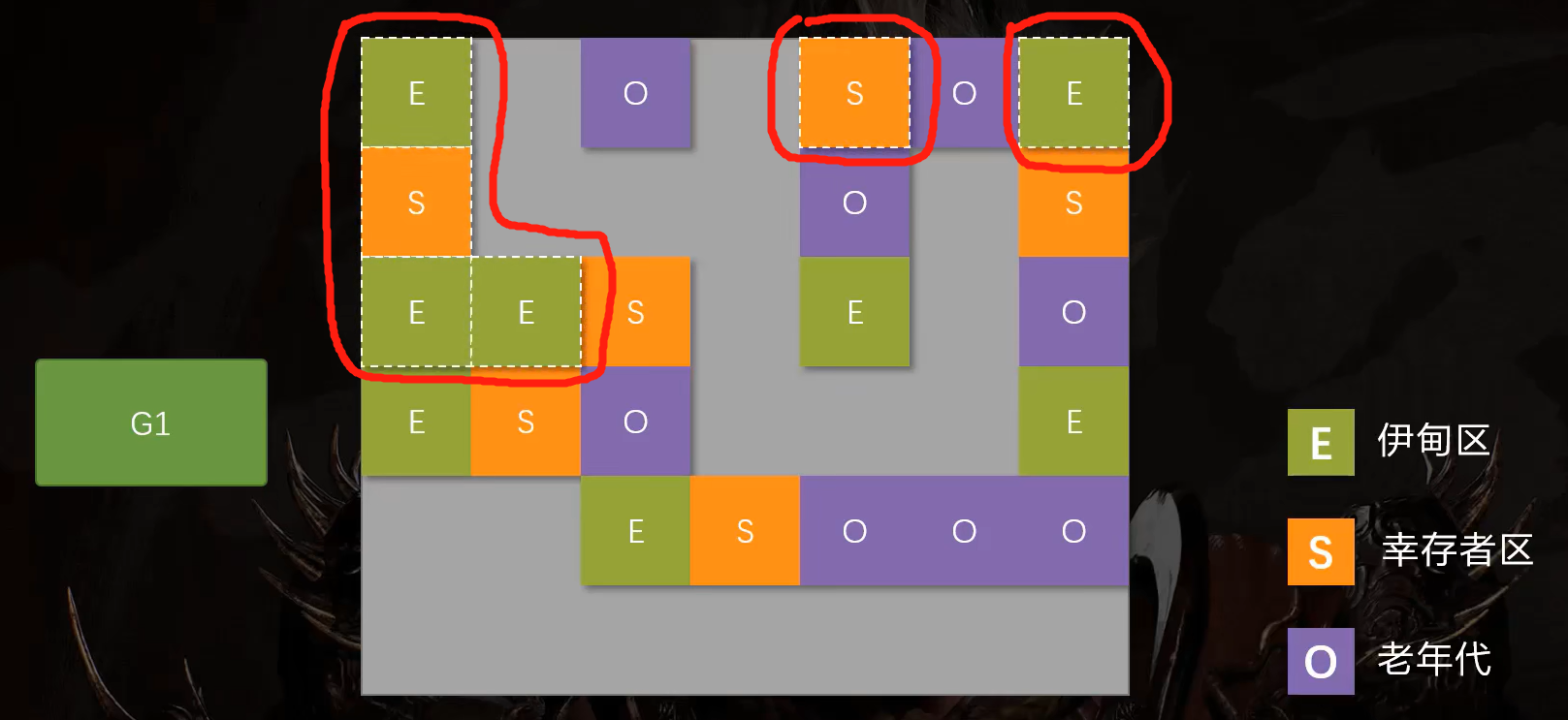
采用复制算法,直接将存活的对象赋值到新的区域内。这样就避免了产生碎片。
另外,G1还把大对象单独存放了,这个区域叫做H(humongous)。
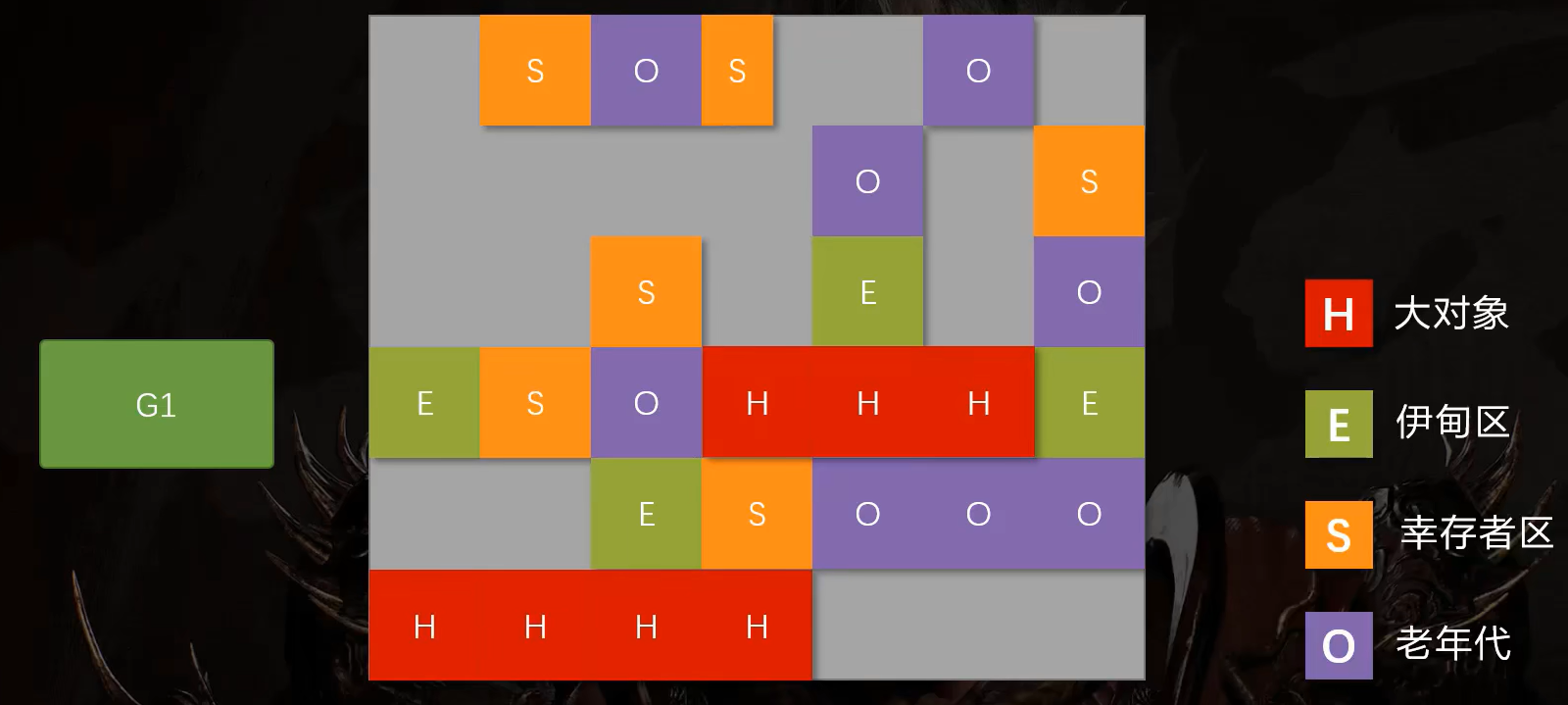
在之前的GC算法中,当一个对象过于巨大,就会直接放入老年代。现在,它依然属于老年代,但存储是独立的。它在被回收之前,内存的位置始终固定不变。这样就避免了对老年代做垃圾回收整理时,频繁的移动大对象。
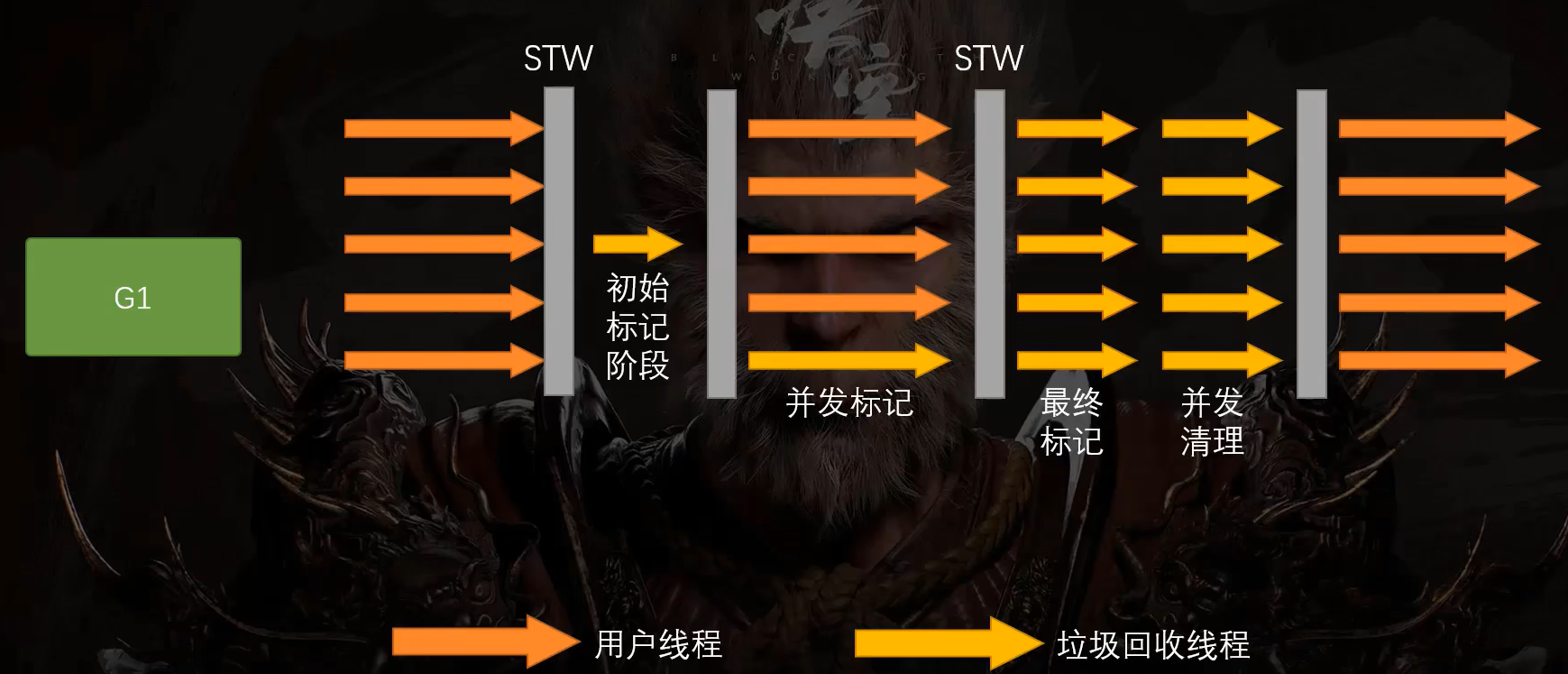
G1的工作流程跟CMS差不多。只不过,由于它不需要扫描全部内存,所以STW时间是非常短的。并且,在最终标记阶段,G1用三色标记法修正了CMS会出现错标的问题。
查看自己的JVM使用了哪种回收器的命令:java -XX:+PrintCommandLineFlags -version

可以看到这里有一个UseParallelGC,通过这张表来查看一下对应的垃圾回收器组合。

















 233
233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











