









yolov3学习笔记
具体代码复现可以参考我的下一篇博文:keras框架下的Yolov3
1. Darknet-53网络
Yolov3采用的darknet-53网络模型,此结构主要由75个卷积层构成,卷积层对于分析物体特征最为有效。由于没有使用全连接层,该网络可以通过strides实现对应任意大小的输入图像。结构如下:假设输入图像shape(416,416,3)(这张图的shape输入和我们的是对不上的,我们是(416,416,3)的图像输入,但是没找到对应的网络结构图,不过结构都是一样的,凑合着用把,具体的可以参考最后一段:Netron观测的网络节点图)

backbone部分由Yolov2时期的Darknet-19进化至Darknet-53,加深了网络层数,引入了Resnet中的跨层加和操作。
2. YOLOV3结构

1) 由主要Darknet-53及残差网络模型构成,一共3个Anchor框y1, y2, y3
2) Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。

3) Feature Pyramid Network 对不同深度的feature map分别进行目标检测,当前层的feature map会对未来层的feature map进行上采 样,并加以利用。这是一个有跨越性的设计。该结构可以使得当前的feature map就可以获得“未来”层的信息,这样的话低阶特征与高 阶 特征就有机融合起来了,提升检测精度。
4) res1、res2、res3。。。resn表示res框内含有多少个res_unit,如res1含有1个res_unit。由0上采样(填充)、DBL、resunit构成。
5) DBL模块为yolov3基础层,由卷积层conv和归一化BN层、leakey relu激活函数组成。
6) 尺度y1: 在基础网络之后添加一些卷积层再输出box信息.
尺度y2: 从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个26x26大小的特征图相加,再次通过多个卷积后输出box信息.相比尺度1变大两倍.
尺度3:与尺度2类似,使用了52x52大小的特征图.
3. 前向过程
1)前面所说的,输出共三个特征图,其中,y1下采样32倍,y2下采样16倍,y3下采样8倍,输出特征图输出维度为:
N
∗
N
(
3
∗
(
4
+
1
+
M
)
)
s
.
t
.
,
N
∗
N
为
输
出
特
征
图
格
点
数
,
每
个
特
征
图
y
一
共
3
个
a
n
c
h
o
r
框
(
锚
框
)
,
4
为
表
示
4
维
的
检
测
框
位
置
(
t
x
,
t
y
,
t
w
,
t
h
)
,
1
表
示
检
测
置
信
度
(
1
维
)
,
M
为
分
类
个
数
N*N(3*(4+1+M))\\ \\s.t., N*N为输出特征图格点数,每个特征图y一共3个anchor框(锚框),\\ 4为表示4维的检测框位置(tx,ty,tw,th), 1表示检测置信度(1维),M为分类个数
N∗N(3∗(4+1+M))s.t.,N∗N为输出特征图格点数,每个特征图y一共3个anchor框(锚框),4为表示4维的检测框位置(tx,ty,tw,th),1表示检测置信度(1维),M为分类个数
2)concat源于残差网络Resnet思想,目的在于获得更好的特征,可以将特征图按通道维度进行拼接,改变维度,Y=f(x)+x ,如:
8
∗
8
∗
16
+
8
∗
8
∗
16
=
8
∗
8
∗
32
8*8*16+8*8*16=8*8*32
8∗8∗16+8∗8∗16=8∗8∗32

Y=F(x)+x,其中x是shortcut开始时的特征,而F(x)就是对x进行的填补与增加,成为残差。因此学习的目标就从学习完整的信息,变成学习残差了。这样以来学习优质特征的难度就大大减小了.
- 其中上采样层,将图像采用插值的方法进行填充图像,不改变通道维数。
4)先验框:
对b-box预测时,采用逻辑Logistic回归,y1、y2、y3各自生成3个先验框,共9个anchor picors, 而采用逻辑回归从9个中找到置信度最高的一个先验框,其中先验框只与检测框的w、h有关,与x、y无关。
5)先验框解码:
目的在于求得bw、bh

虚线框即为先验框,蓝色框为预测真实框
o
b
j
=
{
b
x
=
σ
(
t
x
)
+
c
y
b
y
=
σ
(
t
y
)
+
c
y
b
w
=
P
w
e
t
w
b
h
=
P
h
e
t
h
s
.
t
.
,
σ
为
激
活
函
数
,
(
t
x
)
和
=
σ
(
t
y
)
为
基
于
矩
形
框
中
心
点
左
上
角
的
坐
标
偏
移
σ
为
激
活
函
数
,
P
w
e
t
w
和
P
h
e
t
h
为
先
验
框
的
宽
、
高
obj=\begin{cases} b_x=\sigma(t_x)+c_y\\ b_y=\sigma(t_y)+c_y \\ b_w=P_we^{tw} \\ b_h=P_he^{th}\end{cases} \\ s.t., \sigma为激活函数,(t_x)和=\sigma(t_y)为基于矩形框中心点左上角的坐标偏移\\ \sigma为激活函数,P_we^{tw}和P_he^{th}为先验框的宽、高
obj=⎩⎪⎪⎪⎨⎪⎪⎪⎧bx=σ(tx)+cyby=σ(ty)+cybw=Pwetwbh=Pheths.t.,σ为激活函数,(tx)和=σ(ty)为基于矩形框中心点左上角的坐标偏移σ为激活函数,Pwetw和Pheth为先验框的宽、高
6) 检测置信度解码:由sigmoid函数解码,数据区间在[0,1]范围内
7) 类别解码:共M维分类类别,使用sigmoid解码,取消了类别之间的互斥,使得多目标检测更为灵活。
特
征
图
共
13
∗
13
∗
3
+
26
∗
26
∗
3
+
52
∗
52
∗
3
=
10647
个
b
o
x
以
及
相
应
类
别
和
置
信
度
特征图共13*13*3+26*26*3+52*52*3=10647个box以及相应类别和置信度
特征图共13∗13∗3+26∗26∗3+52∗52∗3=10647个box以及相应类别和置信度
8) 其中,采用对数空间变换是为了防止梯度消失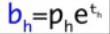
模型训练时,将10647个Box全部送入网络,进行标签和损失的计算
模型推理时,选取一个置信度阈值,过滤低阈值box, 再经过Nms非极大值抑制,则可以预测整个结果。
非极大值抑制的过程是一个迭代-遍历-消除的过程:
1)将所有框的得分排序,选中最高分及其对应的框。
2)遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,我们就将框删除。
3)从未处理的框中继续选一个得分最高的,重复上述过程。
4. 反向过程(训练策略)
1)预测框共分3种情况:正例、负例、忽略样例(忽略样例个人认为是v3的精髓了,真的精致)
2)正例:任取一个ground truth,与10647个框全部计算IOU,IOU最大的预测框,即为正例。并且一个预测框,只能分配给一个ground truth。例如第一个ground truth已经匹配了一个正例检测框,那么下一个ground truth,就在余下的10646个检测框中,寻找IOU最大的检测框作为正例。ground truth的先后顺序可忽略。正例产生置信度loss、检测框loss、类别loss。
预测框为对应的ground truth box标签(需要反向编码,使用真实的x、y、w、h计算出tx、ty、tw、th);类别标签对应类别为1,其余为0;置信度标签为1。
3)负例:正例除外(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例),与全部ground truth的IOU都小于阈值0.5,则为负例。负例只有置信度产生loss,置信度标签为0。
4)忽略样例:正例除外,与任意一个ground truth的IOU大于阈值0.5,则为忽略样例。忽略样例不产生任何loss。
为什么使用忽略样例?: 由于Yolov3使用了多尺度特征图,不同尺度的特征图之间会有重合检测部分。比如有一个真实物体,在训练时被分配到的检测框是特征图1的第三个box,IOU达0.98,此时恰好特征图2的第一个box与该ground truth的IOU达0.95,也检测到了该ground truth,如果此时给其置信度强行打0的标签,网络学习效果会不理想。如果给全部的忽略样例置信度标签打0,那么最终的loss函数会变成Lossobj和Lossnoobj的拉扯,不管两个loss数值的权重怎么调整,或者网络预测趋向于大多数预测为负例,或者趋向于大多数预测为正例。而加入了忽略样例之后,网络才可以学习区分正负例。
- IOU为预测框P1与真实框P2的交集与并集的比值
- 优化器,论文里采用adam,感觉SGD也可以,没试过
5. 损失函数
损失函数为三个特征输出图的损失函数之和
LossN = LossN1 + LossN2 + LossN3

1) (\lambda)为权重常数,控制检测框Loss、obj置信度Loss、noobj置信度Loss之间的比例,通常负例的个数是正例的几十倍以上,可以通过权重超参控制检测效果。
1
i
j
o
b
j
表
示
若
为
正
例
,
则
输
出
为
1
,
若
为
负
例
,
则
输
出
为
0
1_{ij}^{obj}表示若为正例,则输出为1,若为负例,则输出为0
1ijobj表示若为正例,则输出为1,若为负例,则输出为0
x、y、w、h使用MSE作为损失函数,置信度、类别标签由于是0,1二分类,所以使用交叉熵作为损失函数。
具体代码复现可以参考我的下一篇博文:keras框架下的Yolov3
6. 网络模型结构
使用Netrun查看yolov3整体结构如图:
















 4638
4638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









