






文章目录
前言
最近在了解自动驾驶方向的MOT方向,看了一篇综述后发现目前nuScenes数据集和KITTY数据集用的挺多,然后自动驾驶的MOT方向目前用的方法主要是深度学习和KCF(核相关滤波)两大类方法,由于本人之前主要研究军事方向的多传感器多目标跟踪方法的,所以决定先学习一下KCF这些方法和之前研究的课题存在多大的重合。(我一看KCF就想到疯狂星期四hahhaha)
在KCF方法中,我选择了目前在nuScenes数据集上做的最好的两个方法Poly- MOT和Fast-Poly,这两个方法是同一个团队发表的,由于后者是基于前者改进的,故而我决定先学习和复现一下Poly- MOT。(另外Fast-Poly的代码目前还没公布hahahah)
下图出自综述:3D Multiple Object Tracking on Autonomous Driving: A Literature Review,该综述主要将图上的每个方法都粗略地介绍了一遍,然后介绍了该领域的数据集和衡量标准。如有需要请在arXiv上请自行下载。

Poly-MOT
首先需要先看一下Poly-MOT的文章:[2307.16675] Poly-MOT: A Polyhedral Framework For 3D Multi-Object Tracking (arxiv.org)
可以先下载该论文大致了解一下该方法的主要架构、创新点和实验效果等。

nuSceness数据集
接下来需要下载nuScenes数据集,对其结构和内容大致了解一下,官网放在这里了:nuscenes官网 。注意需要注册登录才能下载。
另外也可以在这个网站下载:paperswithcode,这个网站可以看很多领域的方法排名,而且可以轻松的跳转到论文、数据集和开源代码的页面,非常方便。具体方法是在搜索框搜索3D Multi-Object Tracking,然后可以看到下图页面,后续就可以查看nuScenes数据集上各个方法的排名或者下载操作等等,尽情探索吧~

进入nuScenes数据集的官网后,先通过介绍进行基本了解,然后推荐下载如下图所示Full中mini,来跟着官方的文档初步认识一下nuScenes数据集的基本结构和内容。

下载好之后根据下面的教程配一下该数据集需要的环境,主要就是装一下该数据集需要的nuscenes-devkit包,建议使用python3.7。官方给出了步骤,在首页下的Tutorials下选择nuScenes,如下图所示。

也有博客进行了汉化,这里也给出链接,大家可以参考:NuSences 数据集解析以及 nuScenes devkit 的使用
复现Poly-MOT
前面已经做好了准备工作了,接下来我们跑一下Poly-MOT看看它到底是什么样,有什么效果。
首先下载poly项目代码:https://github.com/lixiaoyu2000/Poly-MOT
然后根据README文档中的Use Poly-MOT的步骤进行操作:
-
创建并激活虚拟环境。
conda env create -f environment.yaml conda activate polymot提示: 如果第一句运行有问题,也可以创建虚拟环境后再按照environment.yaml 文件手动pip需要的包。另外在给pip换镜像时,是要在%APPDATA%路径下的pip文件夹下创建pip.ini文件,然后添加内容如下:
[global] index-url = http://mirrors.aliyun.com/pypi/simple trusted-host = mirrors.aliyun.com我在镜像的下面添加这句话:trusted-host = mirrors.aliyun.com,是因为我不添加总会报SSL的错,就无法pip,加上后就能成功了,如果友友们没有这个错可以不用加这行。
提示:找不到%APPDATA%的话,直接打开我的电脑,把%APPDATA%粘到路径框里然后按下回车就会导航过去,如下图。

把%APPDATA%粘到路径框里后,按下回车。

-
准备数据
下载检测器的.json文件。
翻译:文档中提到强烈建议您从先锋探测器工厂(CenterPoint等)官方网站下载探测器文件.json,在线追踪时,我们需要使用.json格式的探测器文件。
对于这段话,我的理解是,跟踪的输入即为检测器的输出,我们可以通过下载官方通过CenterPoint等检测器对nuscenes数据集的检测结果(.json文件),可以直接作为我们在线跟踪的输入,这样就免去了自己配环境来跑检测的麻烦(因为目前我们重点研究的是跟踪)。官方给了CenterPoint这个网站,在里面寻找到这个页面,点击URL
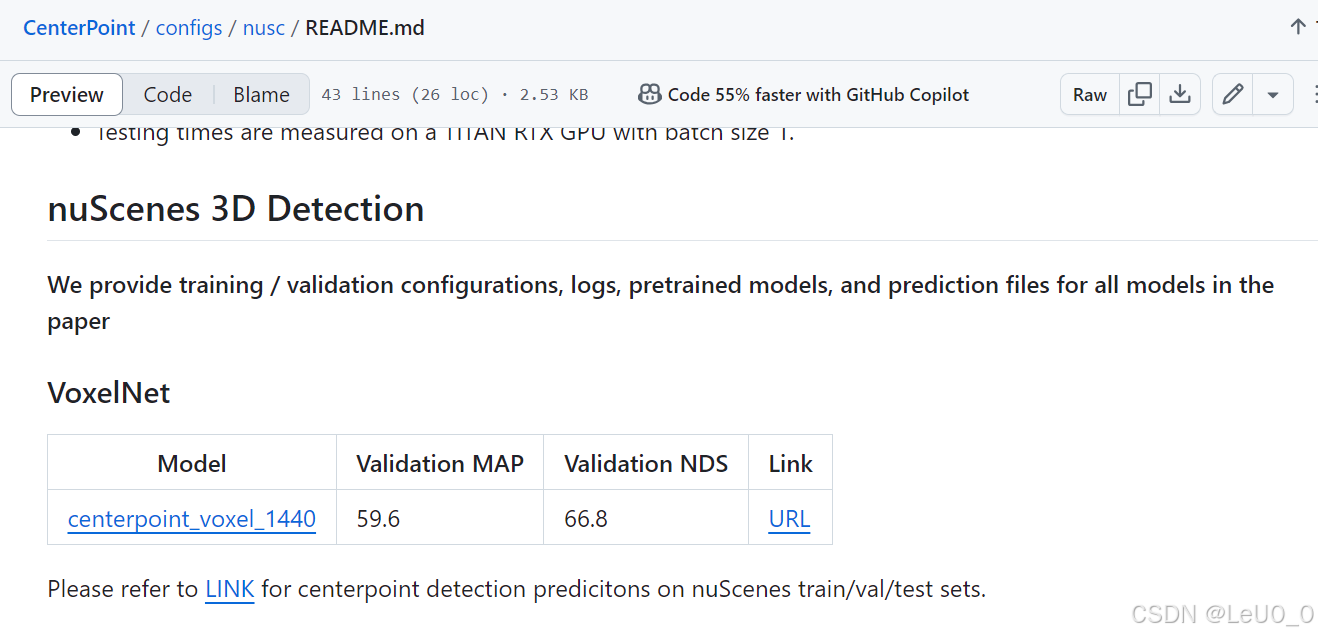
我们就会看到下面这个页面,其中的infos_val_10sweeps_withvelo_filter_True.json就是我们需要的Nuscenes val集的检测器结果啦!
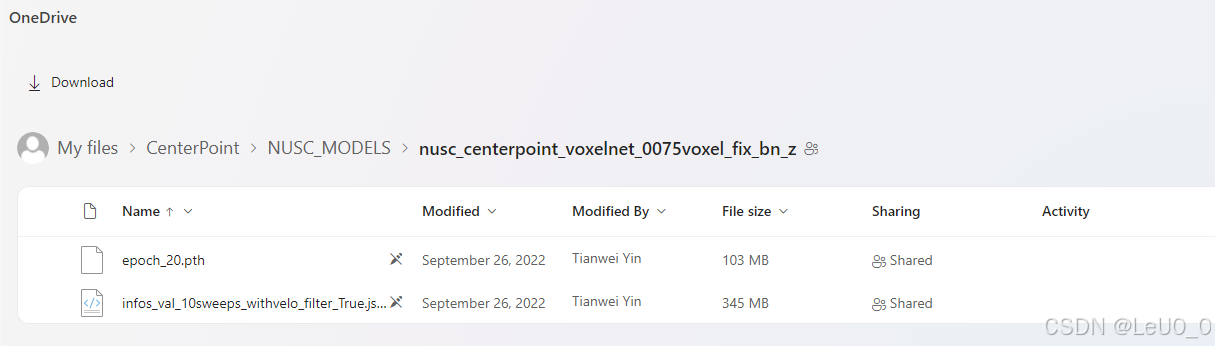
下载nuscenes数据集
翻译:虽然Poly-MOT在线跟踪时不需要数据库,但为了评估跟踪效果,数据库还是有必要的。下载数据并整理如下:
#For nuScenes Dataset
└── NUSCENES_DATASET_ROOT
├── samples <-- keyframes
├── sweeps <-- frames without annotation
├── maps <-- map infos
├── v1.0-trainval <-- train/val set metadata
├── v1.0-test <-- test set metadata注意:nuscenes的下载页面有很多不同的版本可供下载,通过比对上面文件结构中的文件名和尝试下载,最终发现只需要下载这三个即可。分别是Full下trainval中的第一个blob的数据、test的metadata和trainval的metadata。


下载以及解压都需要一定的时间,因为那个blob很大。解压后按照上面要求的文件结构,将需要的文件夹粘一起,夹在一个名为nuscenes的文件夹下,具体结构如下(由于官方文档中并没有说明下载哪些,我是缺什么就下载然后往里面粘贴这样试的,最后结构和要求的一样)

准备在线跟踪的token table
翻译: token table用于识别每个场景的第一帧。
cd Poly-MOT/data/script
python first_frame.py
注意:运行前先将其中的数据集以及跟踪结果路径修改为自己的(我的如下)。最终输出的结果存在data/utils/first_token_table/{version}/nusc_first_token.json

准备检测器
翻译: 跟踪器要求探测器必须按照时间顺序排列。reorder_detection.py 用于按时间顺序重新排列探测器。
cd Poly-MOT/data/script
python reorder_detection.py
注意:需要修改函数reorder_detection内的文件路径(detector路径、数据库路径、token路径等),结果会输出在data/detector/first_token_table/{version}/{version}_{detector_name}.json中。我的修改如下图:

-
运行与评估
翻译:所有的超参数都封装在 config/nusc_config.yaml 中,你可以更改 yaml 文件来定制你自己的跟踪器。论文中 CenterPoint 的准确率可以通过当前 nusc_config.yaml 中的参数重现。这里的参数我没有修改直接运行下面的test。
python test.py注意:这里还有一个问题,运行之后报错大概意思是找不到detection_name然后顺着报错的文件提示,发现在centerpoint生成的.json结果文件中的是用的tracking_name, 猜测应该是poly-MOT跑的最好的LK3D(LargeKernel3D)里面估计是detection_name(后面去找了一下,确实是这样的),所以如果你用CenterPoint检测的结果进行跟踪时,应该将poly代码中的detection_name改为tracking_name,另外还会有detection_score也同样要改。我的修改如下图。

在这个过程中还遇到了一个问题,具体在哪一步运行报错的我不太记得了,问题大概是:在源代码中将当前时间直接作为文件名字,但是在我这里运行显示会报错,因为windows系统的文件名不允许含有“:“,通过查阅资料,我修改了时间的格式,使用”—”代替了“:”,再去作为存储文件的名字就不会报错了,具体修改如下,添加代码位置如下图所示。
# 获取当前时间并格式化为合法的路径名,避免使用 ':' 字符 localtime = time.strftime("%Y%m%d_%H-%M-%S", time.localtime()) result_path = f"result/{localtime}"

修改后,就不会报错啦,在 result中可以看一下名字果然改了。

最终耐心的等待几个小时,就可以看到跑出来的参数啦,在我这里跑出来的结果比官方最好的75.4低,我跑出来是69.8,具体原因我猜测是我跑的数据只有85个场景,只有十分之一可能不够有代表性,另外最高的跟踪效果是检测器LargeKernel3D跑出来的,但是我没找到它的检测结果.json文件(我再找找哈哈哈)

-
可视化
可视化这部分,我运行了一下提供的jupyter,但是结果我没太看懂,如果有理解的友友,欢迎不吝赐教。
新的学习内容与心得
在这个过程中我学习到了python的虚拟环境创建,下载anaconda来创建python虚拟环境,然后在Pycharm中创建新的项目并使用已经创建的虚拟环境运行。pip如何换镜像,使用python 安装jupyter包来运行别人创建的jupyter文档,使用IDM插件快速下载大的文件。
代码结构分析
还在学习中,敬请期待…


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









