







数据架构管理规范
- 概述
1.1. 目的与范围
数据模型用于有效组织企业的数据资产,其设计工作应当在一定的规范约束下进行,这是建设高质量数据模型的前提条件。
1.2 使用对象
数据架构师
数据开发者
数据应用人员
企业数据管理者
1.3 术语介绍
2 研发流程概述
2.1 基础介绍
在数据平台的数据体系建设中,主要分需求阶段、设计阶段、开发阶段、测试阶段、上线运维阶段。此过程涉及的人员比较广,流程比较多,为了更好的保证高效、高质量的完成,所以对整个项目进行了流程进行拆解、人员分工进行制定。
2.2 总体流程图
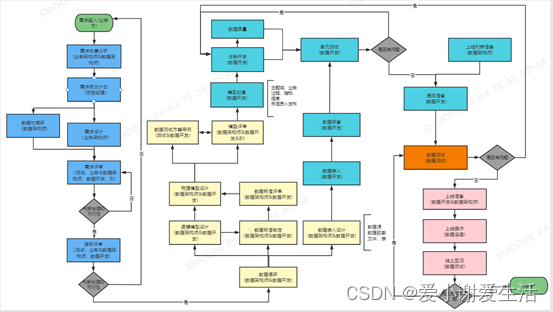
3 公共规范
3.1 设计理念
企业数据的管理和组织,技术上需要满足业务对数据访问、计算、存储、质量上的技术要求,在业务上需要满足企业便捷使用数据的诉求。在维度建模思想基础上,针对大数据存储计算平台的特点,充分考虑新时代大数据应用特点,建立一套模型设计规范与准则,追求建设标准统一、质量可靠、性能优异、成本可控的数据体系。
数据模型的维度设计主要以维度建模理论为基础,基于维度数据模型总线架构,构建一致性的维度和事实。
数据模型的事实表设计在维度模型事实表的基础上,结合数据使用场景的具体实践,进行一定扩展,采用宽表设计方法。所谓宽表:为了提升访问便利性和访问性能,在维度模型的事实表基础上,将部分常用维度退化(冗余)到事实表,或者将一些可枚举型的维度和度量,采用多指标、多字段方式实现在事实表中。
在指标定义中,采取组件化的形式,进行指标标准化定义,先规范定义,后生产,全生命周期控制,保障数据口径统一,减少重复建设,强调数据复用和共享。
3.2 基本原则
高内聚和低耦合:一个逻辑和物理模型由哪些记录和字段组成,应该遵循最基本的软件设计方法论的高内聚和低耦合原则。主要从数据业务特性、访问特性、计算特性等方面来考虑:将业务相近或者相关的数据、粒度相同数据设计为一个逻辑或者物理模型;将高概率同时访问的数据放一起,将低概率同时访问的数据分开存储,针对计算依赖的数据产出时间是否相近,计算是否能同时产出等原则确定组合在一起还是拆分。
核心模型与扩展模型分离:建立核心模型与扩展模型体系,核心模型包括的字段支持常用核心的业务,扩展模型包括的字段支持个性化或是少量应用的需要,必要时让核心模型与扩展模型做关联,不能让扩展字段过度侵入核心模型,破坏了核心模型的架构简洁性与可维护性。
公共处理逻辑下沉及单一:越是底层公用的处理逻辑更应该在数据调度依赖的底层进行封装与实现,不要让公共的处理逻辑暴露给应用层实现,不要让公共逻辑在多处同时存在。公共处理逻辑下沉及单一,既有利于数据复用,也有利于变更修改。
成本与性能平衡:适当的数据冗余换取查询和刷新性能,但是不宜过度冗余与数据复制。
数据可回滚:数据计算处理逻辑不变,在不同时间多次运行数据结果确定不变(累积快照事实表除外)。
一致性:相同的字段在不同表字段命名和定义相同。
命名清晰可理解:表命名规范需清晰、一致,易于下游理解和使用。
3.3 分层架构
数据模型体系中,数据划分为四层:
STG临时缓冲层: 用于存储每天的增量数据和变更数据,如CDC同步update、insert、delete数据;通过更新字段抽取增量数据。如果仅仅insert的数据直接进入ODS层。
ODS(Operational Data Store):主要完成业务系统、日志等结构化和半结构化数据引入到数据中台,保留
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









