效果图
导入对应的包
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
获取最大列数并案列读取文件
csv_file = "D:\\pulseInfo.csv"
largest_column_count = 0
# 寻找最大行值
with open(csv_file, 'r') as temp_f:
lines = temp_f.readlines()
for l in lines:
column_count = len(l.split(',')) + 1
# 找到列数最多的行
largest_column_count = column_count if largest_column_count < column_count else largest_column_count
temp_f.close()
# colunm_names为最大列数展开
column_names = [i for i in range(0, largest_column_count)]
# 读取文件
dataset = pd.read_csv(csv_file, header=None, delimiter=',', names=column_names)
将数据行转换为列
# 将数据行转为数据列
data = dataset.values
index1 = list(dataset.keys())
data = list(map(list, zip(*data)))
data = pd.DataFrame(data)
去掉CSV每列头部信息,只保留脉形数据
# 去掉CSV文件中头部行信息,只保留时间和脉形数据
feature = data[0]
label = data[1]
设置X、Y轴数据信息
X = label.values
Y = feature.values
建模分析
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 1/4, random_state = 0)
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
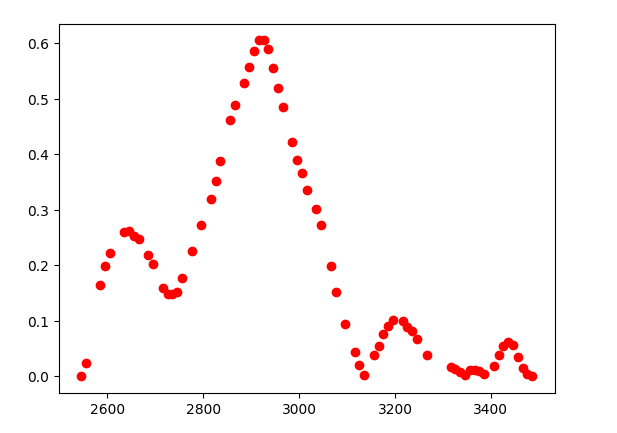
plt.scatter(X_train, Y_train, color = 'red')
数据信息
0.0,0.02397,0.06354,0.12317,0.1642,0.19976,0.22275,0.24146,0.25508,0.25934,0.26119,0.25339,0.24808,0.23429,0.21959,0.20228,0.17923,0.15868,0.14886,0.149,0.15








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









