






测试表格: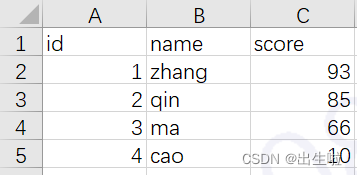
path = r'D:\test.xlsx'
data = pd.read_excel(path)读取数据
print(data.shape,type(data.shape))
print(data.shape[0],type(data.shape[0]))
print(data.shape[1],type(data.shape[1]))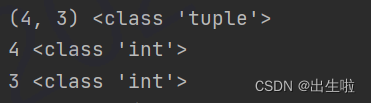
行数为4,列数为3,可以发现不包含column,shape()返回值为元组类型
print(data.index,type(data.index))
print(len(data.index))
print(data.index.stop,type(data.index.stop)) 
查看index(),使用len(data.index)、index.stop,也可以查看表格行数
print(data.index[0],type(data.index[0]))
for i in data.index:
print(i) 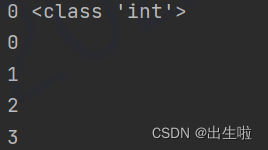
取出index里面的数据
print(data.columns,type(data.columns))
print(len(data.columns))
print(data.columns[0],type(data.columns))
for i in data.columns:
print(i)
查看data.columns,len()同样可以取到列数,还可以使用for循环遍历columns

















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









