






一:先行描述
我们在使用Datax读取文本类型的文件的时候,会因为 单个 “ 导致读取到脏数据的问题,上期是修改的源码,这期的话,有一个简单的方法。
通过阅读Datax txtfilereader![]() https://github.com/alibaba/DataX/tree/master/txtfilereader 文档我们可以发现 ,人家为我们提供了csvReaderConfig这一个配置项
https://github.com/alibaba/DataX/tree/master/txtfilereader 文档我们可以发现 ,人家为我们提供了csvReaderConfig这一个配置项
下面是这我截取的关于csvReaderConfig的描述:
-
csvReaderConfig
-
描述:读取CSV类型文件参数配置,Map类型。读取CSV类型文件使用的CsvReader进行读取,会有很多配置,不配置则使用默认值。
-
必选:否
-
默认值:无
-
常见配置:
"csvReaderConfig":{
"safetySwitch": false,
"skipEmptyRecords": false,
"useTextQualifier": false 这一行我们发现可以禁止使用文本限定符
}
所有配置项及默认值,配置时 csvReaderConfig 的map中请严格按照以下字段名字进行配置:
boolean caseSensitive = true;
char textQualifier = 34; //这一行可以是 设定我们自己的文本限定符
boolean trimWhitespace = true;
boolean useTextQualifier = true;//是否使用csv转义字符
char delimiter = 44;//分隔符
char recordDelimiter = 0;
char comment = 35;
boolean useComments = false;
int escapeMode = 1;
boolean safetySwitch = true;//单列长度是否限制100000字符
boolean skipEmptyRecords = true;//是否跳过空行
boolean captureRawRecord = true;二:演示
1:首先是默认没有任何配置,但是修改了源码的配置

2 :没有修改源码的配置
我们可以看到没人是 ” 且报了错误

3:没有修改源码的但是配置了Json
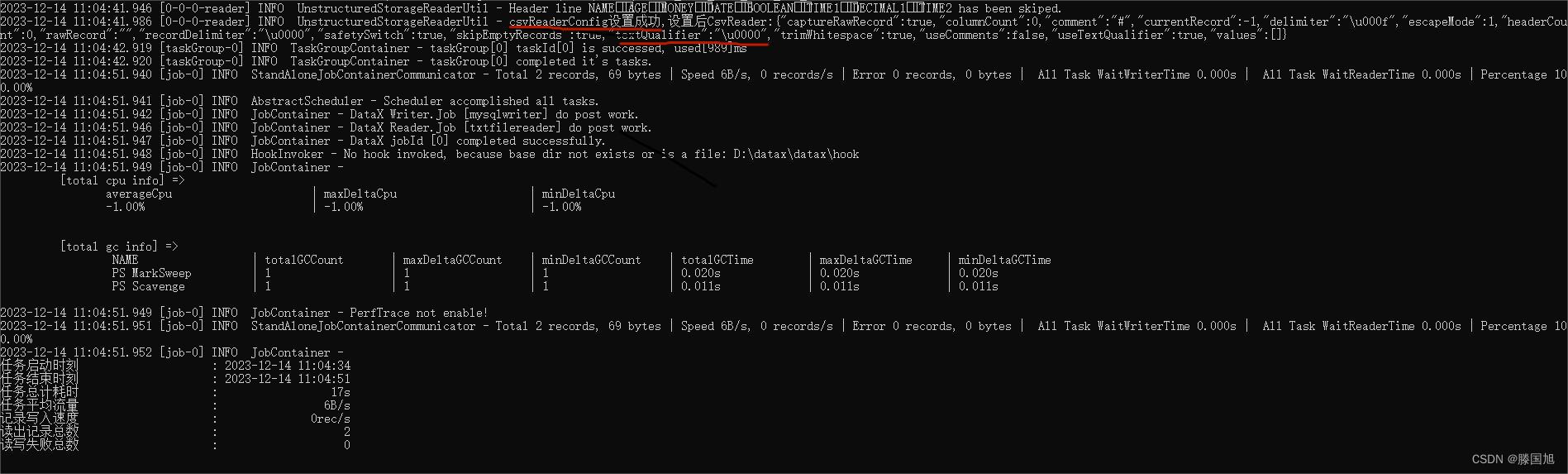
我们可以看到文本限定符成功修改,当然我们也可以根据文档提供的属性自行配置,也可以关闭使用文本限定符。
三:文件
{
"job":{
"content":[
{
"reader":{
"parameter":{
"path":[
"D:\\test\\datax\\GRNGBS_OAMS_CAPS_NAME_DX0_20230419.dat"
],
"csvReaderConfig": {
"textQualifier": "\u0000"
},
"nullFormat":"",
"column":[
{
"index":0,
"type":"String"
},
{
"index":2,
"type":"Long"
},
{
"index":4,
"type":"Double"
},
{
"format":"yyyy/MM/dd",
"index":6,
"type":"Date"
},
{
"index":8,
"type":"Long"
},
{
"format":"dd/MM/yyyy HH:mm:ss",
"index":10,
"type":"Date"
},
{
"index":12,
"type":"Double"
},
{
"index":14,
"type":"string"
},
{
"format":"dd/MM/yyyy HH:mm:ss",
"index":16,
"type":"Date"
}
],
"skipHeader":true,
"encoding":"UTF-8",
"fieldDelimiter":"\u000F"
},
"name":"txtfilereader"
},
"writer":{
"parameter":{
"password":"cinda_db",
"session":[],
"column":[
"NAME",
"AGE",
"MONEY",
"DATE",
"BOOLEAN",
"TIME1",
"DECIMAL1",
"JSON1",
"TIME2"
],
"connection":[
{
"jdbcUrl":"jdbc:mysql://192.168.124.5:3308/cinda_db?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&zeroDateTimeBehavior=CONVERT_TO_NULL&&allowMultiQueries=true",
"table":[
"CAPS_NAME_TEST"
]
}
],
"writeMode":"insert",
"username":"cinda_db",
"preSql":[
"delete from CAPS_NAME_TEST"
]
},
"name":"mysqlwriter"
}
}
],
"setting":{
"speed":{
"channel":1
}
}
}
}
dat文件
NAME AGE MONEY DATE BOOLEAN TIME1 DECIMAL1 TIME2
"1 11 12 2023/11/15 130/11/2023 00:00:00 22.00 8/11/2023 00:00:00
2 12 12 2023/11/18 107/11/2023 00:00:00 22.00 9/11/2023 00:00:00
数据库数据

那么以上就是csvReaderConfig的简单配置,希望可以帮助到各位小伙伴们,如果小伙伴们有什么建议或者意见,欢迎评论指出,谢谢大家了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









