






一:数据文件
在这个文件里面是第二行是多了一个“ 这时候我们运行

二:错误日志

观察日志我们可以发现是有个列越界的错误,但是我的字段和数据都是对应的,而且下面的error只提示了一行的错误数据,说明只读了一行。
这是因为datax回去寻找第一个开头的“直到另一个”结尾 为一个文本。
如果字段开头有个双引号 会报错,如果字段里有三个双引号也会报错。
三:解决方法
我们先来查看datax源码这个TxtFileReader这个模块发现

当开始读取文件的时候走的是 UnstructuredStorageReaderUtil.readFromStream()方法,那么我们点进去发现在这个readFromStream()方法里面找到了下面这个doReadFromStream()方法

接着进去发现在这个方法里面 有一个CsvReader对象,我们进入这个对象里面看看

CCsvReader对象
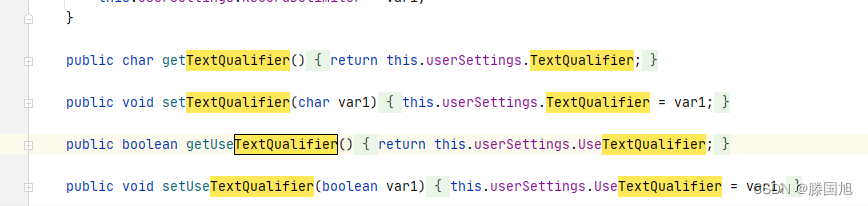

在这里发现datax的默认的文本限定符为 ‘ “ ’ 那么我们只要修改这个文本限定符就可以了
// 设置文本限定符,
/**
* 在CSV文件中,文本限定符通常用来包围包含特殊字符或分隔符的文本字段,以确保正确解析。
*
* 然而,Unicode字符 \u0000 是空字符(Null字符),这意味着在这个设置中,文本限定符被
设置为空字符。这可能是在特定的情境下,希望不使用文本限定符,而是将整个字段作为纯文本
处理的情况。
*
* 因此,这行代码的作用是告诉CSV文件阅读器,在处理CSV文件时,不使用文本限定符或将文本
限定符设置为空字符
*/
csvReader.setTextQualifier('\u0000'); // 这段新加的代码
setCsvReaderConfig(csvReader);使用mvn -U clean package assembly:assembly -Dmaven.test.skip=truej将datax重新打包 会生成一个target文件夹,这个下面有我们重新打包好的文件,替换原来的重新运行。
四:运行结果
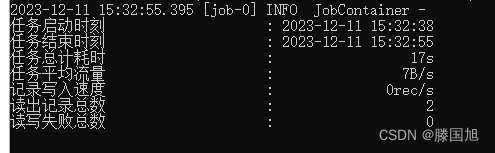

这个问题得到了解决,当数据过多的时候会出现其他的各种各样问题,也许并不是我们配置的问题,而是数据本身的问题,所以我们在导入的过程中也要尽量保证数据的正确性。
希望这篇文章可以给小伙伴们带来帮助,也希望小伙伴们指出这篇文章的纰漏,敬请指教,谢谢大家啦。















 1338
1338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









