defget_data(fold):
train_df_f = train_df.copy()
train_df_f['is_valid']=(train_df_f['fold']== fold)#验证集#from fastai.vision.all import *
dls = ImageDataLoaders.from_df(train_df_f,
valid_col='is_valid',#验证集列
seed=365,#seed
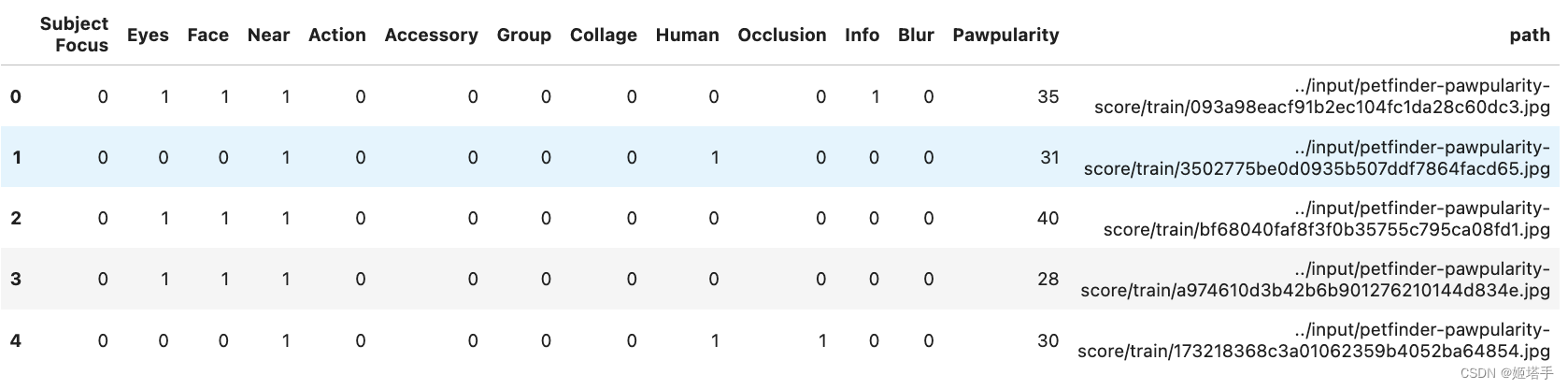
fn_col='path',#图像的路径
label_col='norm_score',#label#label is in the first column of the DataFrame
y_block=RegressionBlock,#The type of target
bs=BATCH_SIZE,#pass in batch size
num_workers=8,
item_tfms=Resize(224),#pass in item_tfms
batch_tfms=setup_aug_tfms([Brightness(), Contrast(), Hue(), Saturation()]))#图像增强策略return dls
all_preds =[]for i inrange(N_FOLDS):print(f'Fold {i} results')
learn = get_learner(fold_num=i)
learn.fit_one_cycle(5,2e-5, cbs=[SaveModelCallback(), EarlyStoppingCallback(monitor='petfinder_rmse', comp=np.less, patience=2)])
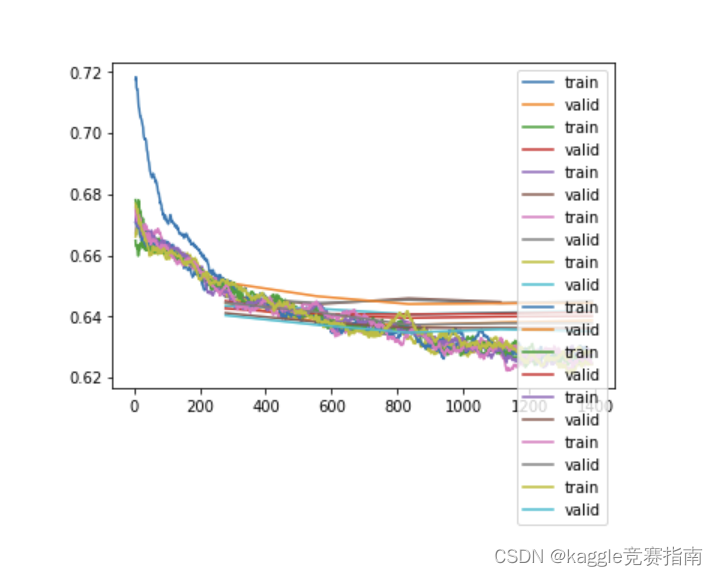
learn.recorder.plot_loss()
dls = ImageDataLoaders.from_df(train_df,#pass in train DataFrame
valid_pct=0.2,#80-20 train-validation random split
seed=365,#seed
fn_col='path',#filename/path is in the second column of the DataFrame
label_col='norm_score',#label is in the first column of the DataFrame
y_block=RegressionBlock,#The type of target
bs=BATCH_SIZE,#pass in batch size
num_workers=8,
item_tfms=Resize(224),#pass in item_tfms
batch_tfms=setup_aug_tfms([Brightness(), Contrast(), Hue(), Saturation()]))
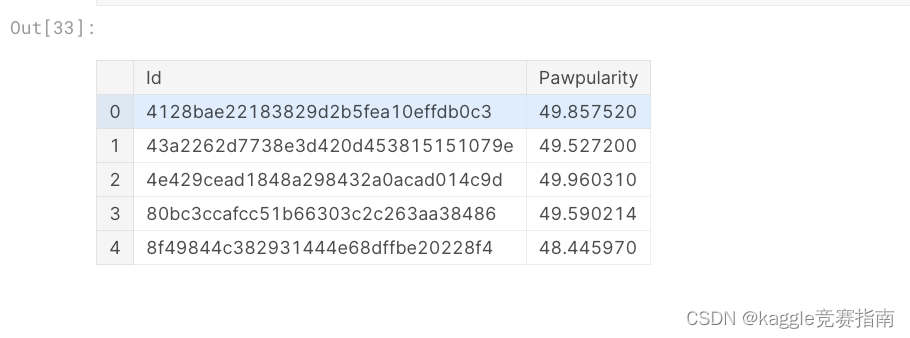
test_dl = dls.test_dl(test_df)
preds, _ = learn.tta(dl=test_dl, n=5, beta=0)
all_preds.append(preds)del learn
torch.cuda.empty_cache()
gc.collect()




























 2023
2023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











