







多线程
-
什么是线程
-
线程(Thread)被包涵在进程之中,是进程中的实际运作单位。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。
-
为什么要使用多线程
- 使用多线程来实现多任务并发执行比使用多进程的效率高。
-
python多线程实现
-
简单使用
import threading import time def run(n): print("task", n) time.sleep(1) print('2s') time.sleep(1) print('1s') time.sleep(1) print('0s') time.sleep(1) if __name__ == '__main__': t1 = threading.Thread(target=run, args=("t1",)) t2 = threading.Thread(target=run, args=("t2",)) t1.start() t2.start() ---------------------------------- >>> task t1 >>> task t2 >>> 2s >>> 2s >>> 1s >>> 1s >>> 0s >>> 0s # 可以看到两个线程并发执行,互不影响 -
Thread用来创建一个线程对象
- target
- 线程要执行的目标函数,注意这里不用加上()
- args
- 目标函数的参数,必须通过元组进行传递
- target
-
start()
- 开启线程
-
当我们需要子线程随主进程的结束而结束时
- t1.setDaemon(True)
- setDaemon(True)把子线程变成了主线程的守护线程,因此当主进程结束后,子线程也会随之结束
- 注意:必须在start()之前设置
- t1.setDaemon(True)
-
当我们需要子线程结束之后,主进程再结束时
- t1.join()
- 让主线程等待子线程执行。
- 注意:在start()之后设置
- t1.join()
-
加锁机制
-
由于线程之间是进行随机调度,如果有多个线程同时操作一个数据或对象,会造成程序结果的不可预期,这就是“线程不安全”。
-
线程锁用于锁定资源,即同一时刻允许一个线程执行操作。
-
lock.acquire() 加锁
- 用于操作数据或对象之前
-
lock.release() 释放锁
- 用于操作行为结束后
-
由于一般问题都是出现再在print中
- 所以也可以用format和end=“” 来减少print分步操作
- 这样就避免使用加锁来降低效率\
-
-
argparse
-
命令行解析的标准模块
-
argparse简单使用流程
主要有三个步骤:
-
创建
ArgumentParser()对象-
parser = argparse.ArgumentParser()
-
可选参数如下
prog - 程序的名称(默认:sys.argv[0]) usage - 描述程序用途的字符串(默认值:从添加到解析器的参数生成) description - 在参数帮助文档之前显示的文本(默认值:无) epilog - 在参数帮助文档之后显示的文本(默认值:无) parents - 一个 ArgumentParser 对象的列表,它们的参数也应包含在内 formatter_class - 用于自定义帮助文档输出格式的类 prefix_chars - 可选参数的前缀字符集合(默认值:'-') fromfile_prefix_chars - 当需要从文件中读取其他参数时,用于标识文件名的前缀字符集合(默认值:None) argument_default - 参数的全局默认值(默认值: None) conflict_handler - 解决冲突选项的策略(通常是不必要的) add_help - 为解析器添加一个 -h/--help 选项(默认值: True) allow_abbrev - 如果缩写是无歧义的,则允许缩写长选项 (默认值:True) exit_on_error - 决定当错误发生时是否让 ArgumentParser 附带错误信息退出。 (默认值: True)
-
-
调用
add_argument()方法添加参数-
添加可选参数声明的参数名前缀带-或–,前缀是-的为短参数,前缀是–是长参数,两者可以都有,也可以只有一个,短参数和长参数效果一样。可选参数的值接在位置参数的后面,不影响位置参数的解析顺序。
-
例: 添加-t参数,帮助信息为’目标主机’
parser.add_argument('-t', help='目标主机')使用
parse_args()解析添加的参数 -
例: 打印上面添加的-t获得的数据
args = parser.parse_args() print(args.t)
-
-
-
基于OS
主机发现
原理分析:
-
利用网络上机器IP地址的唯一性,给目标IP地址发送一个数据包,再要求对方返回一个同样大小的数据包来确定两台网络机器是否连接相通。
-
这里利用ping来进行主机发现
-
ping含义:
PING (Packet Internet Groper),因特网包探索器,用于测试网络连接量的程序。Ping发送一个ICMP echo请求消息给目的地并报告是否收到所希望的ICMP echo (ICMP回声应答)。它是用来检查网络是否通畅或者网络连接速度的命令。
-
ping的一般流程
- 当ARP缓存表中没有对应IP的mac地址时,进行ARP广播进球,获取MAC地址,有则直接下一步
- 发起ping请求,构造ICMP的Echo(ping)request type=8,code=0
- 获得回应ping请求,Echo(ping)reply type=0,code=0
-
ping命令依托于ICMP协议
-
ICMP协议头前2个字节(类型,代码)l
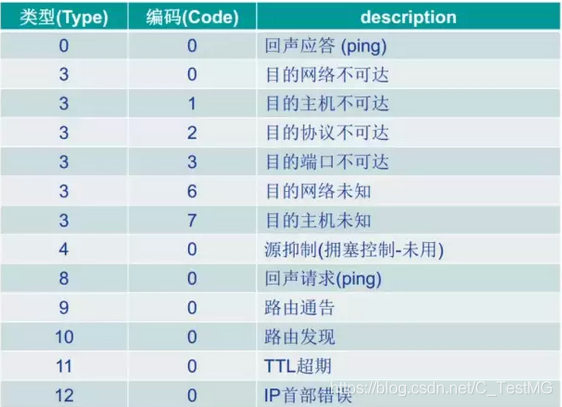
-
-
实现过程:
-
通过ping命令发送ICMP请求报文
- 通过python中的os模块去模拟cmd命令的ping
- os模块提供了多数操作系统的功能接口函数。
-
确认主机的回应(是否存活)
os.system(ping * > NUL)
- > NUL (Windows下的dos重定向符)
和Linux中的重定向一样 这里 > NUL的作用 就是将输出的结果写入到NUL中 而NUL又是空,所以无论命令是否成功,都不会看到任何信息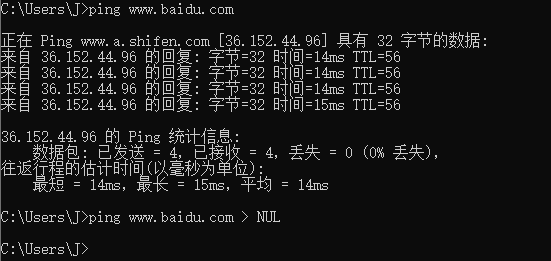
但是其实是有返回值的,当ping命令发送数据包后不能收到数据包时,返回值为1,而收到数据包后返回值为0 将ping * > NUL 赋值给一个变量 通过ping一个存在和一个不存在的域名 看到了不同的返回值, 目标alive:0 目标die:1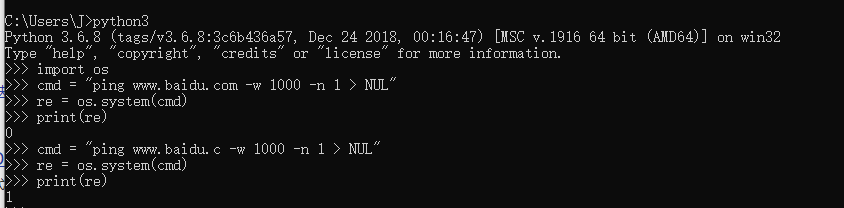
-
通过判断不同的返回值来确认是否存活,已经达到我们的目标
-
但是在后续的使用中发现了问题
-
问题:当我们ping一个无法访问的目标主机时,得到的返回值1却是0,致使结果出现问题
-
成因:其实很简单,上面说到返回值是由发送数据包后能否收到数据包来决定的
- 正常的请求超时是没有问题的

-
但是当无法访问目标主机时,却会收到数据包,使结果出现错误

-
区别
这里要说明一下两者的区别 如果所经过的路由器的路由表中具有到达目标的路由,而目标因为其他原因不可到达,这时候会出现“请求超时” 如果路由表中连到达目标的路由都没有,那就会出现“无法访问目标主机”。
-
-
-
所以不能通过> NUL来进行判断了,通过os.popen(cmd).read()
os.popen()可以实现一个“管道”,从这个命令获取的值可以继续被使用。

可以看到popen的返回值为一个文件对象,所以通过read()去读取

结果正是在cmd中直接ping的返回结果
-
那么我们只需要通过对返回结果进行分析判断主机是否存活即可
经过分析只需要判断返回内容是否含有’TTL’字符串即可
-
多线程的使用
这里只涉及到了简单地创建,启动,设置join是为了让子线程结果全部返回后再进行统计
-
在区别基于掩码的扫描和基于范围的扫描时利用了ipaddress模块
-
ipaddress模块作用:创建、检查和操作IP地址
-
创建地址对象 paddress.ip_address()
- 根据传入值(整数(十进制/十六进制/八进制/二进制)或字符串)自动创建IPV4/IPV6地址,函数自动判断地址类别
-
定义ip网络 ipaddress.ip_network()
-
可以处理网络地址/掩码位数格式
-
注意:如果数据中设置了主机位,如‘192.168.1.1/24’,则会弹出错误提示——设置了主机位:
192.168.12.1/24 has host bits set -
可以通过设置strict=False实现附加位强制为0:
ipaddress.ip_network('192.168.1.1/24',strict=False) 再次处理192.168.12.1/24时,会自动解析为'192.168.1.0/24'
-
-
-
实现代码
import os
import threading
import argparse
import ipaddress
from scapy.layers.inet import ICMP, IP
from scapy.sendrecv import sr1
# ping执行
def os_ping(host):
global count
cmd = "ping {} -w 1000 -n 1 ".format(host)
txt = os.popen(cmd).read()
if 'TTL' in txt:
print('[+] {}\n'.format(host), end='')
count += 1
else:
print('[-] {}\n'.format(host), end='')
# 范围扫描的处理
def range_func():
a = args.t.split('-')
b = a[0].rfind('.')
end = a[0][:b] + '.' + a[1]
start = int(ipaddress.ip_address(a[0])) # 范围开头ip
end = int(ipaddress.ip_address(end)) # 范围结尾ip
for i in range(start, end + 1):
i = ipaddress.ip_network(i)
i = str(i).split('/')
t1 = threading.Thread(target=os_ping, args=(i[0],))
thread.append(t1)
t1.start()
for i in thread:
i.join()
# 掩码扫描的处理
def mask_func():
a = list(ipaddress.ip_network(args.thost, strict=False))
for ip in a:
t1 = threading.Thread(target=os_ping, args=(ip,))
thread.append(t1)
t1.start()
for i in thread:
i.join()
if __name__ == '__main__':
thread = []
count = 0
parser = argparse.ArgumentParser(description="主机发现")
parser.add_argument('-t', '--thost', help='目标主机')
args = parser.parse_args()
if '-' in args.thost:
range_func()
elif '/' in args.thost:
mask_func()
else:
os_ping(args.thost)
print("alive count: {}".format(count))
Tracert实现
原理分析:
Tracert 命令用 IP 生存时间 (TTL) 字段和 ICMP 错误消息来确定从一个主机到网络上其他主机的路由。
- 基于UDP的实现
- 在基于UDP的实现中,客户端发送的数据包是通过UDP协议来传输的,使用了一个大于30000的端口号,服务器在收到这个数据包的时候会返回一个端口不可达的ICMP错误信息,客户端通过判断收到的错误信息是TTL超时还是端口不可达来判断数据包是否到达目标主机
- 流程:
- 首先,tracert送出一个TTL是1的IP 数据包到目的地,当路径上的第一个路由器收到这个数据包时,它将TTL减1。
- 此时,TTL变为0,所以该路由器会将此数据包丢掉,并送回一个「ICMP time exceeded」消息(包括发IP包的源地址,IP包的所有内容及路由器的IP地址),tracert 收到这个消息后,便知道这个路由器存在于这个路径上。
- 接着tracert 再送出另一个TTL是2 的数据包,发现第2个路由器…
- tracert 每次将送出的数据包的TTL 加1来发现另一个路由器,这个重复的动作一直持续到某个数据包 抵达目的地。
- 当数据包到达目的地后,该主机则不会送回ICMP time exceeded消息,一旦到达目的地,由于tracert通过UDP数据包向不常见端口(30000以上)发送数据包,因此会收到「ICMP port unreachable」消息,故可判断到达目的地。
- 注意:tracert 有一个固定的时间等待响应(ICMP TTL到期消息)。如果这个时间过了,它将打印出一系列的*号表明:在这个路径上,这个设备不能在给定的时间内发出ICMP TTL到期消息的响应。然后,Tracert给TTL记数器加1,继续进行。
- 问题:
- 如今因为安全问题大部分的应用服务器都不提供UDP服务(或者被防火墙挡掉),所以我们拿不到服务器的任何返回,程序会认为还没有结束,一直尝试增加数据包的TTL。
- 基于ICMP的实现
- ICMP实现中,直接发送一个**ICMP回显请求(echo request)数据包,服务器在收到回显请求的时候会向客户端发送一个ICMP回显应答(echo reply)**数据包,在这之后的流程还是跟第一种方案一样。这样就避免了我们的traceroute数据包被服务器的防火墙策略墙掉。
TTL
- TTL(time-to-live)
- 是IP数据包中的一个字段,它指定了数据包最多能经过几次路由器。从我们源主机发出去的数据包在到达目的主机的路上要经过许多个路由器的转发,在发送数据包的时候源主机会设置一个TTL的值,每经过一个路由器TTL就会被减去一,当TTL为0的时候该数据包会被直接丢弃(不再继续转发),并发送一个超时ICMP报文给源主机。
实现过程:
-
既然也是ICMP包,只涉及到ttl的更改,那么在使用ping时,只需带上-i(指定TTL)参数即可
-
结果还是通过popen().read()对返回数据的分析进行判断
-
失败情况判断是当数据包的丢失率达到100%
-
成功情况我们要获取每一跳路由的IP地址,所以分析发现只需要通过字符串索引可以实现目标
-
-
先使用find找到头索引值和尾索引值
- 再利用字符串索引得到结果IP
start = txt.find('来自') end = txt.find(' 的回复') re[ttl] = txt[start + 3:end]
-
-
最后一个问题是怎么判断tracert已经结束
-
tracert不像主机探测一开始就有明确的目标范围,且多线程之间互不干涉
-
解决方法
- 先给一个比较大的TTL
- 将所有线程结果添加到字典中
- 遍历字典将重复的那个IP(目标IP,也就是最后地址)取出
- 再次遍历打印到目标IP结束
-
-
多线程使用:
- 这里只涉及到了简单地创建,启动,设置join是为了让子线程结果全部返回后再进行统计
代码实现
import os
import threading
import argparse
# 遍历找出目标地址
def find_end():
ip = []
for k, v in re.items():
if v in ip:
repeat = v
return repeat
else:
ip.append(v)
# 从字典键名为1开始打印直到键值为目标地址结束
def result(repeat):
for i in range(1, len(re)):
print(i, '-', re[i])
if re[i] == repeat:
break
def thread_up():
threads = []
for ttl in range(1, 32):
t1 = threading.Thread(target=tracert_up, args=(args.thost, ttl))
t1.start()
threads.append(t1)
for i in threads:
i.join()
repeat = find_end()
result(repeat)
def tracert_up(target, ttl):
cmd = 'ping {target} -i {ttl} -w 1000 -n 1 '.format(target=target, ttl=ttl)
txt = os.popen(cmd).read()
if '100%' in txt:
re[ttl] = '请求超时'
else:
# 字符串索引获取ip地址
star = txt.find('来自')
end = txt.find(' 的回复')
re[ttl] = txt[star + 3:end]
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="tracert实现")
parser.add_argument('-t', '--thost', help='目标主机')
args = parser.parse_args()
re = {}
thread_up()
MTU实现
原理分析:
-
MTU: 最大传输单元,是指一种通信协议的某一层上面所能通过的最大数据包大小
-
对于windows操作系统来讲,以太网网卡MTU默认为1500,可以通过修改工具进行修改,但只能改小,不能改大。
-
在7层网络协议中,MTU是数据链路层的概念。MTU限制的是数据链路层的payload,也就是上层协议的大小,例如IP,ICMP等。
-
OSI中的层 功能 TCP/IP协议族 应用层 文件传输,电子邮件,文件服务,虚拟终端 TFTP,HTTP,SNMP,FTP,SMTP,DNS,Telnet 表示层 数据格式化,代码转换,数据加密 没有协议 会话层 解除或建立与别的接点的联系 没有协议 传输层 提供端对端的接口 TCP,UDP 网络层 为数据包选择路由 IP,ICMP,RIP,OSPF,BGP,IGMP 数据链路层 传输有地址的帧以及错误检测功能 SLIP,CSLIP,PPP,ARP,RARP,MTU 物理层 以二进制数据形式在物理媒体上传输数据 ISO2110,IEEE802,IEEE802.2
-
-
这个1500字节就是网络层IP数据报的长度限制,因为**IP数据报的首部为20字节,所以IP数据报的数据区长度最大为1480字节.而这个1480字节在这里有需要存放ICMP报文.又因为ICMP Echo消息的ICMP **报头的大小为 8 字节,所以ICMP数据报的数据区最大长度为1472字节
-
ICMP报头
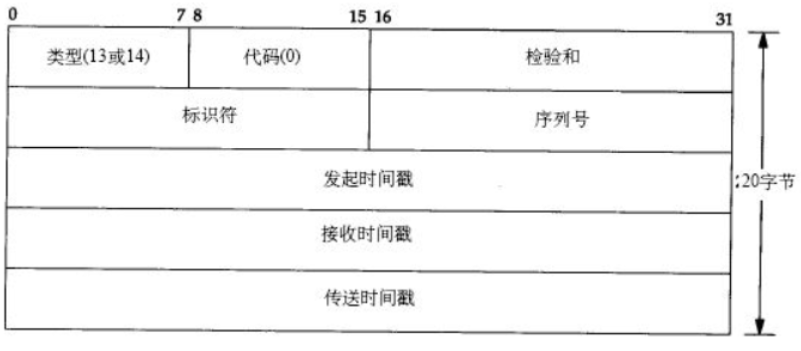
- 类型(1字节)+代码(1字节)+检验和(2字节)+标识(2字节)+序号(2字节)+可选项
-
IP报头
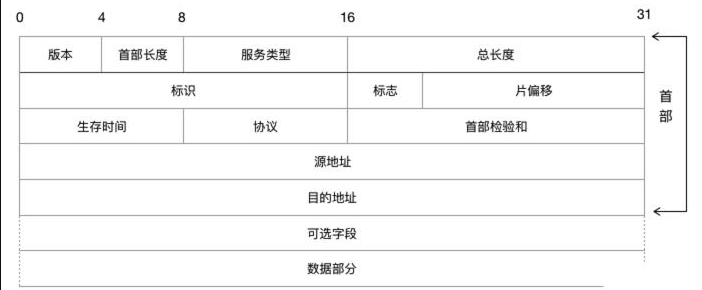
- 版本(4位)+首部长度(4位)+服务(8位)+总长度(16位)+标识(16位)+标志(3位)+片偏移(13位)+生存时间(8位)+协议(8位)+首部检验和(16位)+源地址(32位)+目的地址(32位),共20字节,以及可选字段和填充数据。
-
-
当我们发送的ICMP数据大于1472的时候会怎样呢?这也就是说IP数据报大于1500字节,大于 MTU.这个时候发送方IP层就需要分片.把数据报分成若干片,使每一片都小于MTU,如果不分片(IP包DF标志位为1,也就是不允许分包),将会导致数据包发送不出去
-
这里就利用这个特性来测试MTU的大小(这里的MTU为ICMP的 )
-
IP包标志位
-
目前只有两位有意义
<1>标志位中的最低位记为MF(More Fragment)。MF=1即表示后面*“还有分片”*的数据报。MF=0表示这已是若干数据报片中的最后一个。
<2>标志字段中间的以为记为DF(Don’t Fragment)。意思是*"不能分片"的数据报。只有当DF=0*是才允许分片(默认为0)。
-
实现过程:
- 也是ICMP包,通过-f设置包的不分片(设置IP包DF标志位为1) -l 设置数据大小
- 也就是说windows下ping指令的 -l 参数是指OSI模型第4层数据分段前的长度。
- 这里只需要判断数据包是否能够发出(前提:目标地址一定能得到回应),所以不需要对应答进行分析,直接 > NUL判断返回值即可
- 当返回值为0时,代表有回应,将MTU记录到列表中
- 最后遍历列表求出最大值+28,即为MTU值
代码实现
import os
import threading
import argparse
def mtu_test(mtu):
cmd = "ping {} -f -l {} -n 1 > NUL".format(args.thost,mtu)
re = os.system(cmd)
if re == 0:
mtu_arr.append(mtu)
def thread_up():
for i in range(1500, 1400, -1):
t1 = threading.Thread(target=mtu_test, args=(i,))
t1.start()
thread.append(t1)
for i in thread:
i.join()
# 得到最大MTU
def mtu_get():
max_mtu = 1
for mtu in mtu_arr:
if mtu > max_mtu:
max_mtu = mtu
print(max_mtu+28)
if __name__ == '__main__':
thread = []
mtu_arr = []
parser = argparse.ArgumentParser(description="MTU实现")
parser.add_argument('-t', '--thost', help='目标主机')
args = parser.parse_args()
thread_up()
mtu_get()
拓展学习
在连接宽带时测试MTU为1480,WIFI时为1500
-
wireshark抓包分析
-
在WIFI网络下找到数据为1472的最大传输包
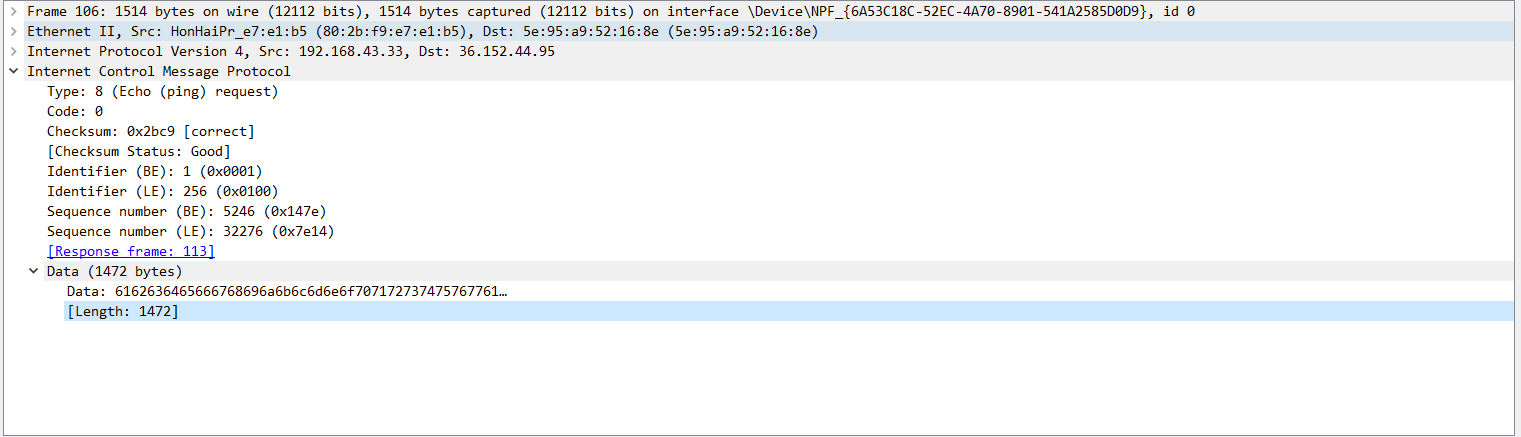
- Ethernet II 帧最大尺寸为1514字节,去掉头部14字节的开销,那么MTU1500字节
-
在宽带连接下找到数据为80的最大传输包
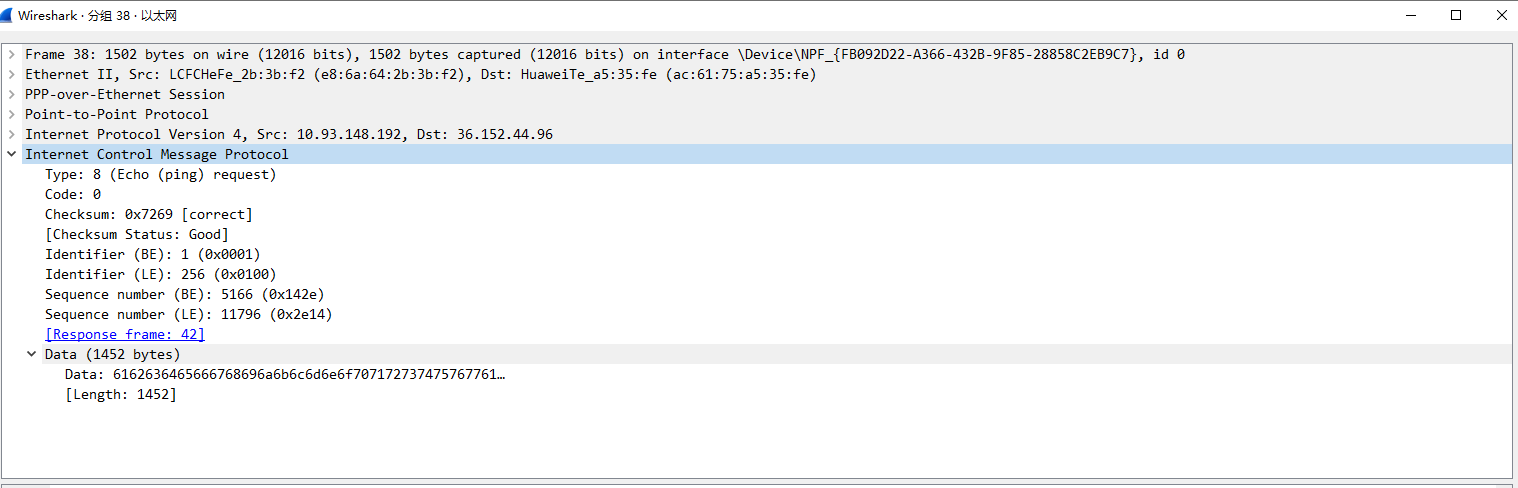
-
很明显,当使用宽带连接时,出现了新的协议pppoe
-
但是pppoe协议封装总共用了8个字节,按理说MTU应该为1492( 这里的Ethernet II 帧为1502字节也可以看出,Ethernet II 帧并未达到最大)
-
查找资料
1.可能是为了兼容
2.可能是避免二次拨号带来的又一次PPPoE的封装
3.避免数据包碎片??
-
-
所以要是将路由MTU设置为1492可以提升传输效率,但可能出现奇怪的错误
-
-
基于Scapy
Scapy
-
Scapy是一个强大的,用Python编写的交互式数据包处理程序,它能让用户发送、嗅探、解析,以及伪造网络报文,从而用来侦测、扫描和向网络发动攻击。
-
这里介绍常用的函数
-
命令 效果 send(pkt) 用于发3层报文 sendp(pkt) 用于发2层报文 sniff() 用于网络嗅探,类似Wireshark和tcpdump sr1(pkt) 发送+接收3层报文 pkt.show() 针对数据包的展开试图 srp(pkt) sr(pkt) IP() 构造IP层数据包 ICMP() 构造ICMP层数据包
主机发现
原理分析:
-
和OS的主机发现基本一致、
-
scapy需要组包,所以抓包分析
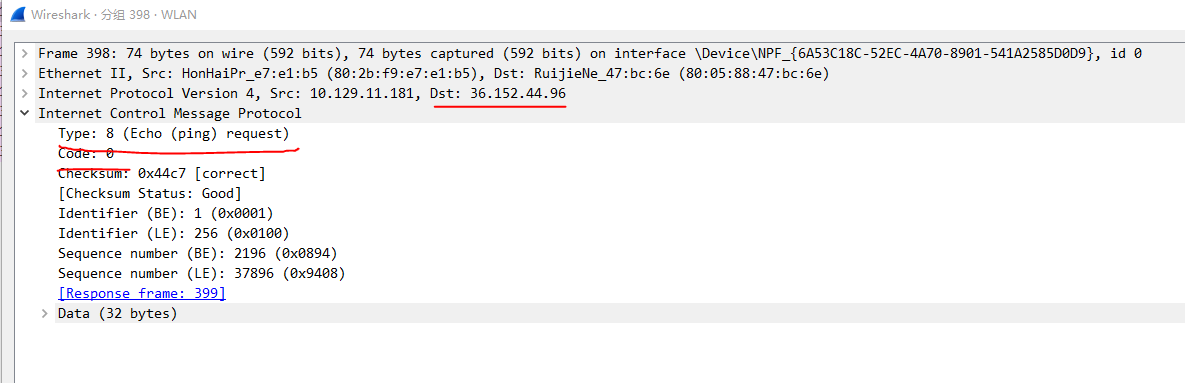
IP层: dst为目标探测IP地址
ICMP层:
type 8 code 0 回显请求(ping请求)->type0 code 0 回显应答(ping应答)
另一种请求:type13 code0 的时间戳请求 -> type14 code0 时间戳应答
实现过程:
-
通过scapy组包
-
开启多个线程用sr1发送并接收
-
这里会出现一个问题:
多个线程sr1发送数据包后,都在等待接收应答数据包,会因为数据包应答的时间不一致出现错误接收导致结果出错
- 可以将发送和接收分为两步进行
- scapy中sniff类似Wireshark,进行网络嗅探接收响应包
-
-
所以用send发送,sniff接收
- 出现新的问题:我们想要准确的收到所有数据包,就必须让嗅探先启动再开始发送数据包,但是sniff一旦启动就不再接下去执行了
- 解决方法
- 1.将sniff设置为线程
- 2.让send通过线程并行,并且先sleep一会儿让抓包先开始
-
分析sniff接受的响应包
- 响应包ICMP层 需要 type=0,code=0
- 获取响应包IP层的 src (源地址,即谁给我们的响应)
-
获取的src添加到全局列表中,并用全局变量count计数
-
判断程序的停止
-
send 发包当循环结束时自然会结束
-
而sniff收包,需要通过stop_filter参数来结束,当stop_filter目标函数的返回值为true时,sniff停止
-
设置stop_filter目标函数为stop_sniff(pkt)
def stop_sniff(pkt): global stop return stopsniff每一次收包都会返回stop
-
我们只需要设置全局变量stop为false,当for循环结束,将全局变量stop改为true
-
为了准确收到最后几个包,在for循环后sleep几秒再给stop赋值true
-
-
代码实现:
import threading
import time
from scapy.layers.inet import ICMP, IP
from scapy.sendrecv import send, sniff
#接受响应包处理
def sniff_call(packet):
global count, alive
if packet.haslayer(ICMP) and packet[ICMP].code == 0 and packet[ICMP].type == 0:
alive.append(packet[IP].src)
count += 1
#发包函数
def send_packet_after(pkt):
send(pkt, iface='Intel(R) 82579LM Gigabit Network Connection', verbose=False)
#sniff停止函数
def stop_sniff(pkt):
global stop
return stop
#构造数据包,多线程发送
def send_packet():
global stop
time.sleep(2)
threads = []
for ip_end in range(256):
target_ip = '10.30.25.{}'.format(ip_end)
pkt = IP(dst=target_ip) / ICMP()
t1 = threading.Thread(target=send_packet_after, args=(pkt,))
threads.append(t1)
t1.start()
for a in threads:
a.join()
time.sleep(2)
stop = True #发送结束将sniff也结束
if __name__ == '__main__':
count = 0
alive = []
stop = False
print('扫描开始...')
thread = threading.Thread(target=send_packet)
thread.start()
sniff(prn=sniff_call, iface='Intel(R) 82579LM Gigabit Network Connection', stop_filter=stop_sniff)
for i in range(256):
ip = '10.30.25.{}'.format(i)
if ip in alive:
print(ip)
print('have {} alive target, This is alive list'.format(count))
拓展学习
sniff的stop_filter参数
# 当stop_filter=stop_sniff时,
sniff(prn=sniff_call, iface='Intel(R) 82579LM Gigabit Network Connection', stop_filter=stop_sniff)
def stop_sniff(pkt):
global stop
return stop
- 发现stop_sniff必须要接收pkt参数,删去参数时会报错
stop_sniff() takes 0 positional arguments but 1 was given
# 也就是Stop_sniff()接受0个位置参数,但需要给出了1个
-
查询stop_filter定义
- 在sniff中原本的作用是定义一个函数,决定在抓到指定的数据之后停止,正因为这样所以定义的函数必须要接受一个参数,也就是收到的流量包
-
所以这里是使用了一个小技巧来更方便的停止sniff的抓包
- 本来的写法应该是
def stop_sniff(pkt):
if pkt[IP].src == "10.30.25.255":
return True
- 但这样写又会出现新的错误,Layer [IP] not found,也就是接受的包没有IP层
- 这里的解决方法是的sniff引入新参数filter
- 作用:过滤规则,可以在里面定义winreshark里面的过滤语法
sniff(prn=sniff_call, iface='Intel(R) 82579LM Gigabit Network Connection', stop_filter=stop_sniff,filter="icmp")
#在过滤规则中添加只抓取拥有icmp层的流量包
实现代码
def stop_sniff(pkt):
if pkt[IP].dst == "10.30.25.255":
return True
sniff(prn=sniff_call, iface='Intel(R) 82579LM Gigabit Network Connection', stop_filter=stop_sniff,filter="icmp")















 91
91











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









